Course
Machine Learning with PySpark
4 hr
21.7K
In this article, we've outlined some of the most common machine learning interview questions you might encounter when applying for a role in the industry or interviewing a candidate. Practicing these questions and preparing answers can help you make sure the interview goes smoothly.
Basic questions are related to terminologies, algorithms, and methodologies. Interviewers ask these questions to assess the technical knowledge of the candidate.
Semi-supervised learning is the blend of supervised and unsupervised learning. The algorithm is trained on a mix of labeled and unlabeled data. Generally, it is utilized when we have a very small labeled dataset and a large unlabeled dataset.
In simple terms, the unsupervised algorithm is used to create clusters and by using existing labeled data to label the rest of the unlabelled data. A Semi-supervised algorithm assumes continuity assumption, cluster assumption, and manifold assumption.
It is generally used to save the cost of acquiring labeled data. For example, protein sequence classification, automatic speech recognition, and self-driving cars.
Apart from the dataset, you need a business use case or application requirements. You can apply supervised and unsupervised learning to the same data.
Generally:
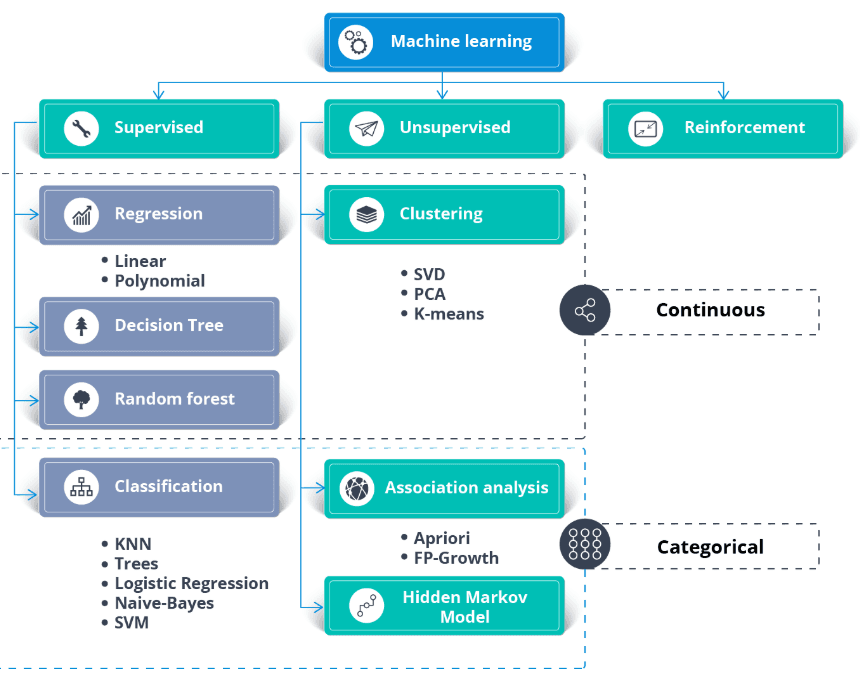
Image from thecleverprogrammer
Learn the machine learning fundamentals by taking our course.
The K Nearest Neighbor (KNN) is a supervised learning classifier. It uses proximity to classify labels or predict the grouping of individual data points. We can use it for regression and classification. KNN algorithm is non-parametric, meaning it doesn't make an underlying assumption of data distribution.
In the KNN classifier:
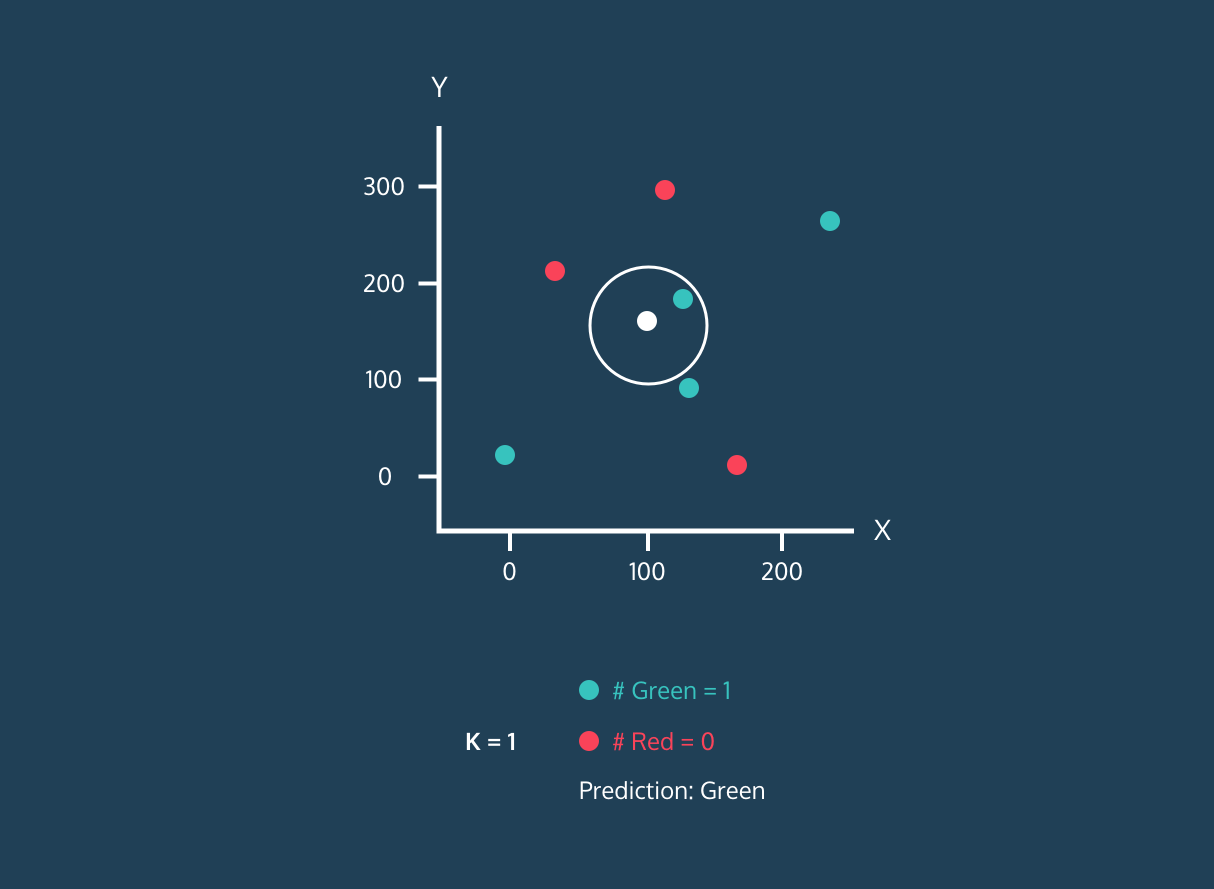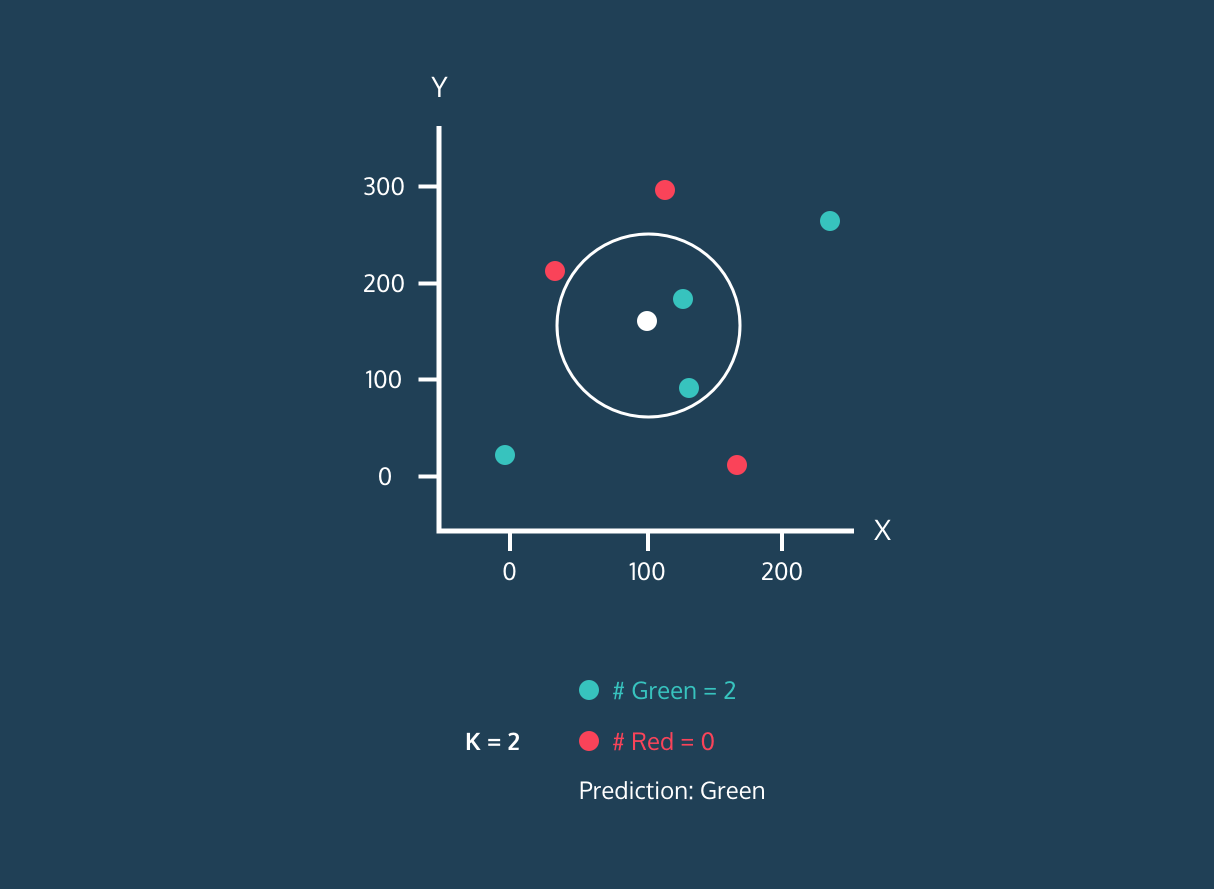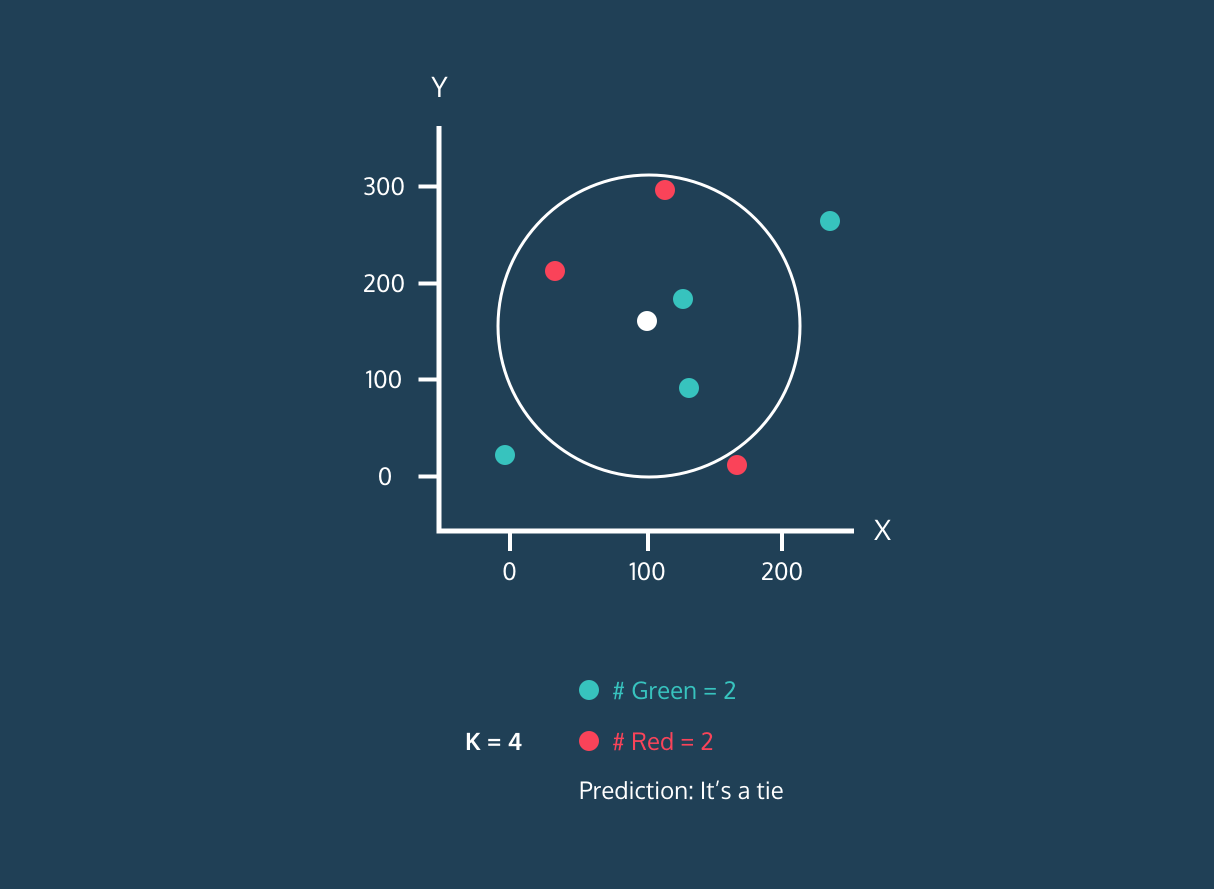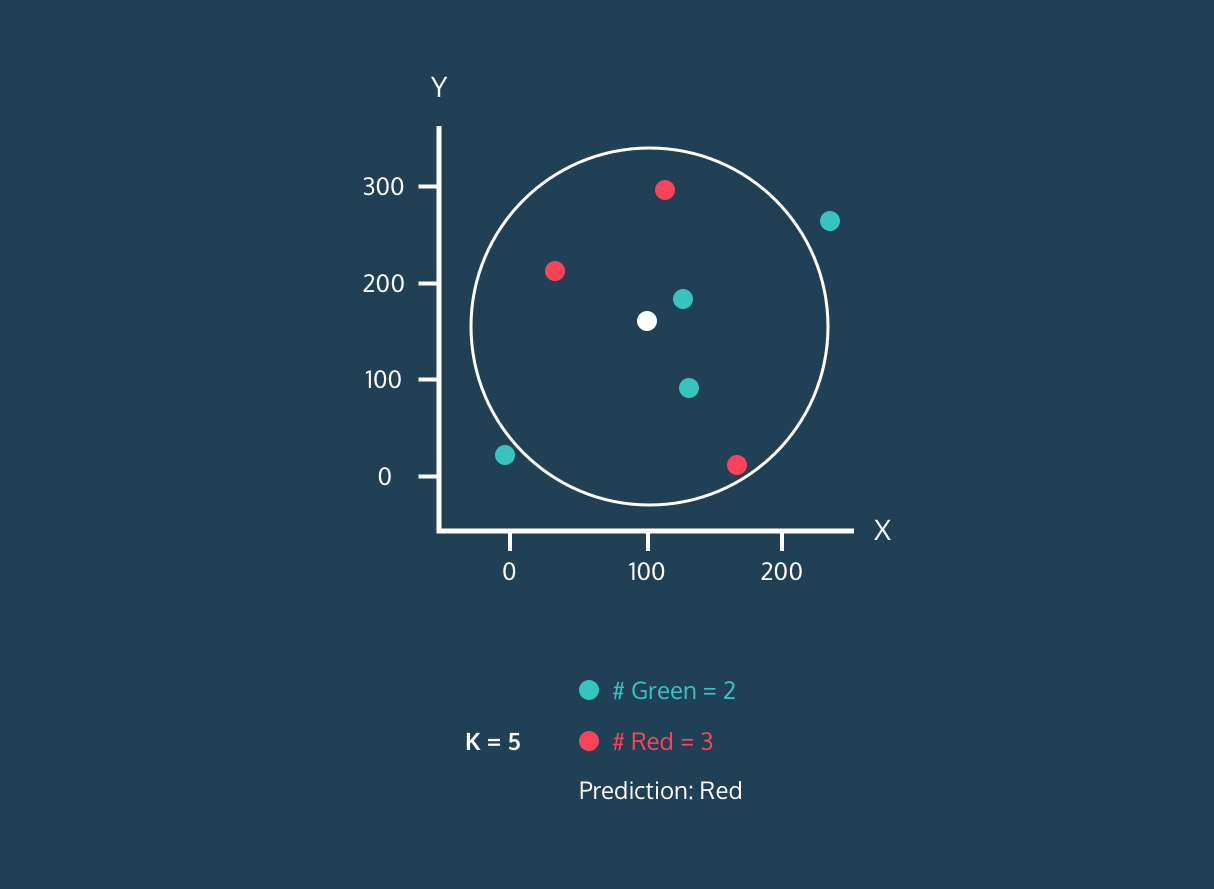
Image from Codesigner's Dev Story
Learn all about supervised learning classification and regression models by taking a short course.
Feature importance refers to techniques that assign a score to input features based on how useful they are at predicting a target variable. It plays a critical role in understanding the data's underlying structure, the behavior of the model, and making the model more interpretable.
There are several methods to determine feature importance:
Understanding feature importance is crucial for model optimization, reducing overfitting by removing non-informative features, and improving model interpretability, especially in domains where understanding the model's decision process is critical.
The technical interview session is more about assessing your knowledge about processes and how well you are equipped to handle uncertainty. The hiring manager will ask machine learning interview questions about data processing, model training and validation, and advanced algorithms.
Yes. Most of the algorithms use Euclidean distance between data points, and if the feature value varies greatly, the results will be quite different. In most cases, outliers cause machine learning models to perform worse on the test dataset.
We also use feature scaling to reduce convergence time. It will take longer for gradient descent to reach local minima when features are not normalized.
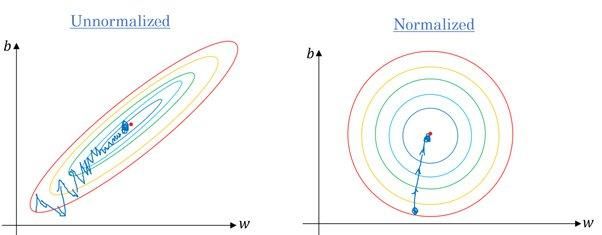
Gradient without and with scaling | Quora
Feature engineering skills are in high demand. You can learn everything about the subject by taking a DataCamp course, such as Feature Engineering for Machine Learning in Python.
Low bias occurs when the model is predicting values close to the actual value. It is mimicking the training dataset. The model has no generalization which means if the model is tested on unseen data, it will give poor results.
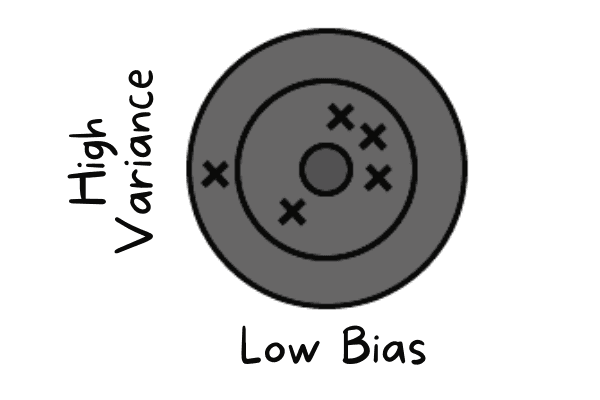
Low bias and high variance | Author
To fix these issues, we will use bagging algorithms as it divides a data set into subsets using randomized sampling. Then, we generate sets of models using these samples with a single algorithm. After that, we combine the model prediction using voting classification or averaging.
For high variance, we can use regularization techniques. It penalized higher model coefficients to lower model complexity. Furthermore, we can select the top features from the feature importance graph and train the model.
Cross-validation is used to evaluate model performance robustly and prevent overfitting. Generally, cross-validation techniques randomly pick samples from the data and split them into train and test data sets. The number of splits is based on the K value.
For example, if the K = 5, there will be four folds for the train and one for the test. It will repeat five times to measure the model performed on separate folds.
We cannot do it with a time series dataset because it doesn't make sense to use the value from the future to forecast the value of the past. There is a temporal dependency between observations, and we can only split the data in one direction so that the values of the test dataset are after the training set.
The diagram shows that time series data k fold split is unidirectional. The blue points are the training set, the red point is the test set, and the white is unused data. As we can observe with every iteration, we are moving forward with the training set while the test set remains in front of the training set, not randomly selected.
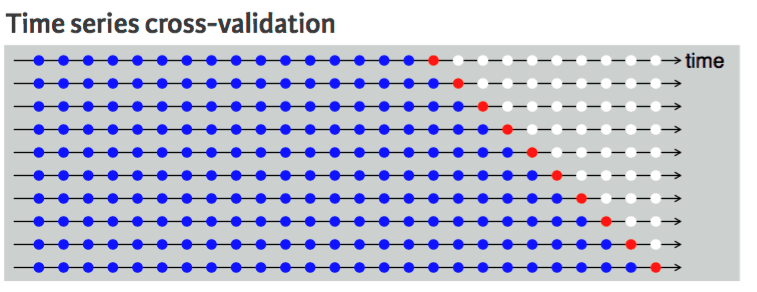
Time series cross validation | UC Business Analytics R Programming Guide
Learn about time series data manipulation, analysis, visualization, and modeling by taking Time Series with Python.
Most machine learning jobs offered on LinkedIn, Glassdoor, and Indeed are role specific. As such, during the interview, they will focus on role-specific questions. For the computer vision engineering role the hiring manager will focus on image processing questions.
Imagine an image of 250 X 250 and a fully connected hidden first layer with 1000 hidden units. For this image, the input features are 250 X 250 X 3 = 187,500, and the weight matrix at the first hidden layer will be 187,500 X 1000 dimensional matrix. These numbers are huge for storage and computation, and to combat this problem, we use convolution operations.
Learn image processing by taking a short Image Processing in Python course
If you do not have enough data to train a convolutional neural network, you can use transfer learning to train your model and get state-of-the-art results. You need a pre-trained model which was trained on a general but larger dataset. After that, you will fine-tune it on newer data by training the last layers of the models.
Transfer learning allows data scientists to train models on smaller data by using fewer resources, computing, and storage. You can find open-source pre-trained models for various use cases easily, and most of them have a commercial license which means you can use them to create your application.
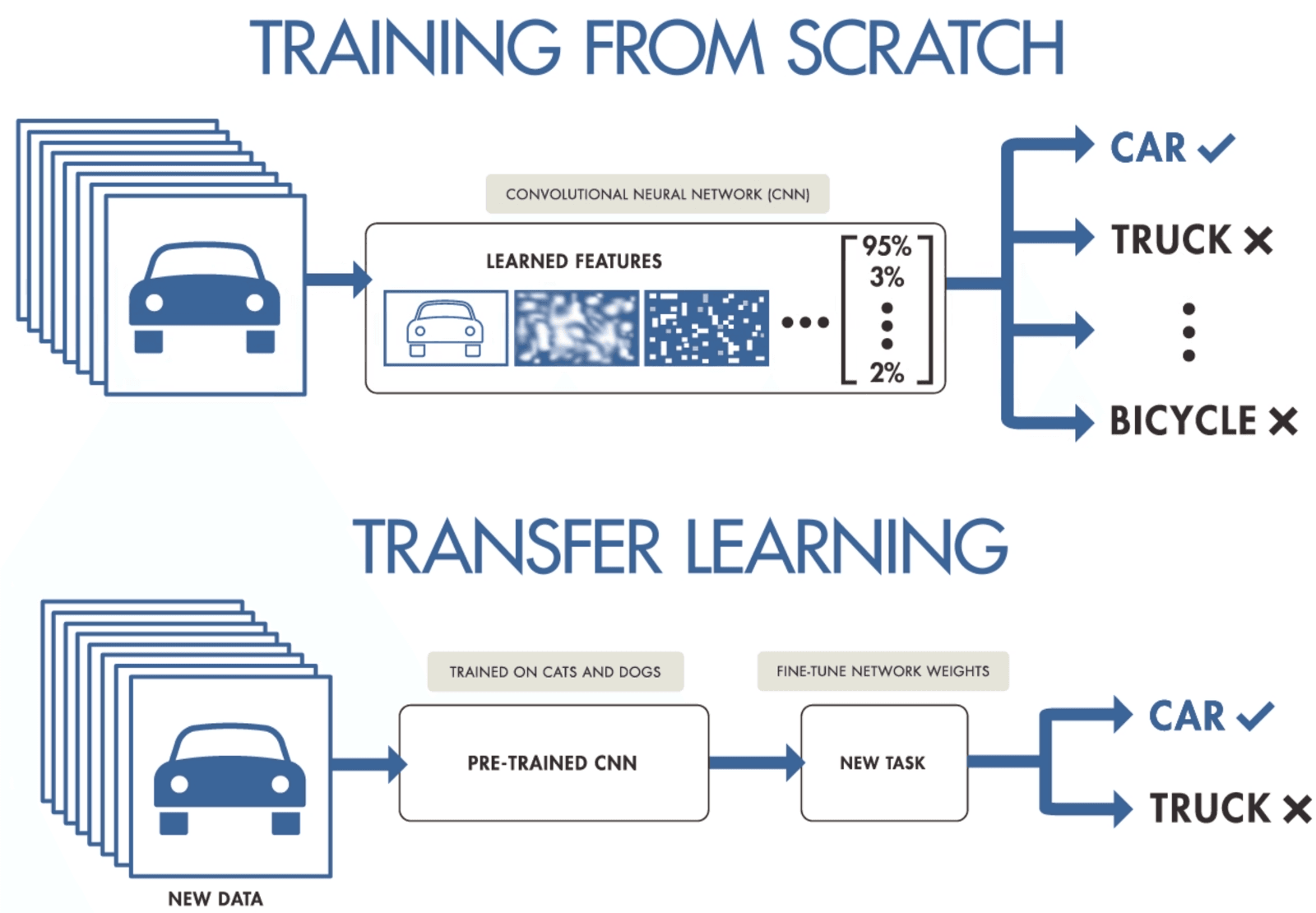
Transfer Learning by purnasai gudikandula
YOLO is an object detection algorithm based on convolutional neural networks, and it can provide real-time results. The YOLO algorithm requires a single forward pass through CNN to recognize the object. It predicts both various class probabilities and boundary boxes.
The model was trained to detect various objects, and companies are using transfer learning to fine-tune it on new data for modern applications such as autonomous driving, wildlife preservation, and security.
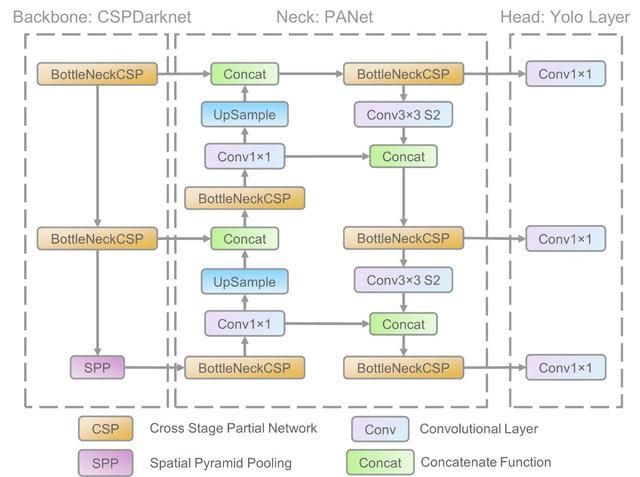
YOLO V5 model architecture | researchgate
Syntactic Analysis, also known as Syntax analysis or Parsing, is a text analysis that tells us the logical meaning behind the sentence or part of the sentence. It focuses on the relationship between words and the grammatical structure of sentences. You can also say that it is the processing of analyzing the natural language by using grammatical rules.
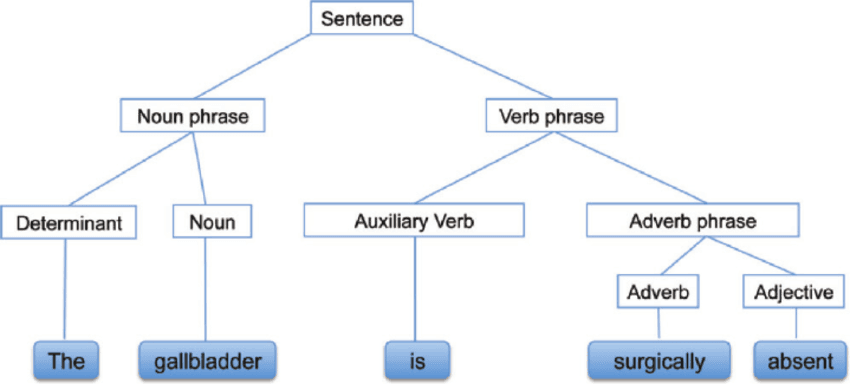
Syntactic Analysis | researchgate
Stemming and lemmatization is a normalizing technique used to minimize the structural variation of words in a sentence.
Stemming removes the affixes added to the word and leaves it in base form. For example, Changing to Chang.
It is widely used by search engines for storage optimization. Instead of storing all the forms of the words, it only stores the stems.
Lemmatization converts the word into its lemma form. The output is the root word instead of the stem word. After lemmatization, we get the valid word that means something. For example, Changing to Change.

Stemming vs. Lemmatization | Author
It is the responsibility of machine learning engineers to optimize the model inference. Due to large language models, it has become more difficult to deploy models in production and reduce inference time to microseconds.
To improve inference time, we can use:
Learn the basics of NLP by completing Natural Language Processing in Python skill track.
Reinforcement learning uses trial and error to reach goals. It is a goal-oriented algorithm and it learns from the environment by taking correct steps to maximize the cumulative reward.
In typical reinforcement learning:
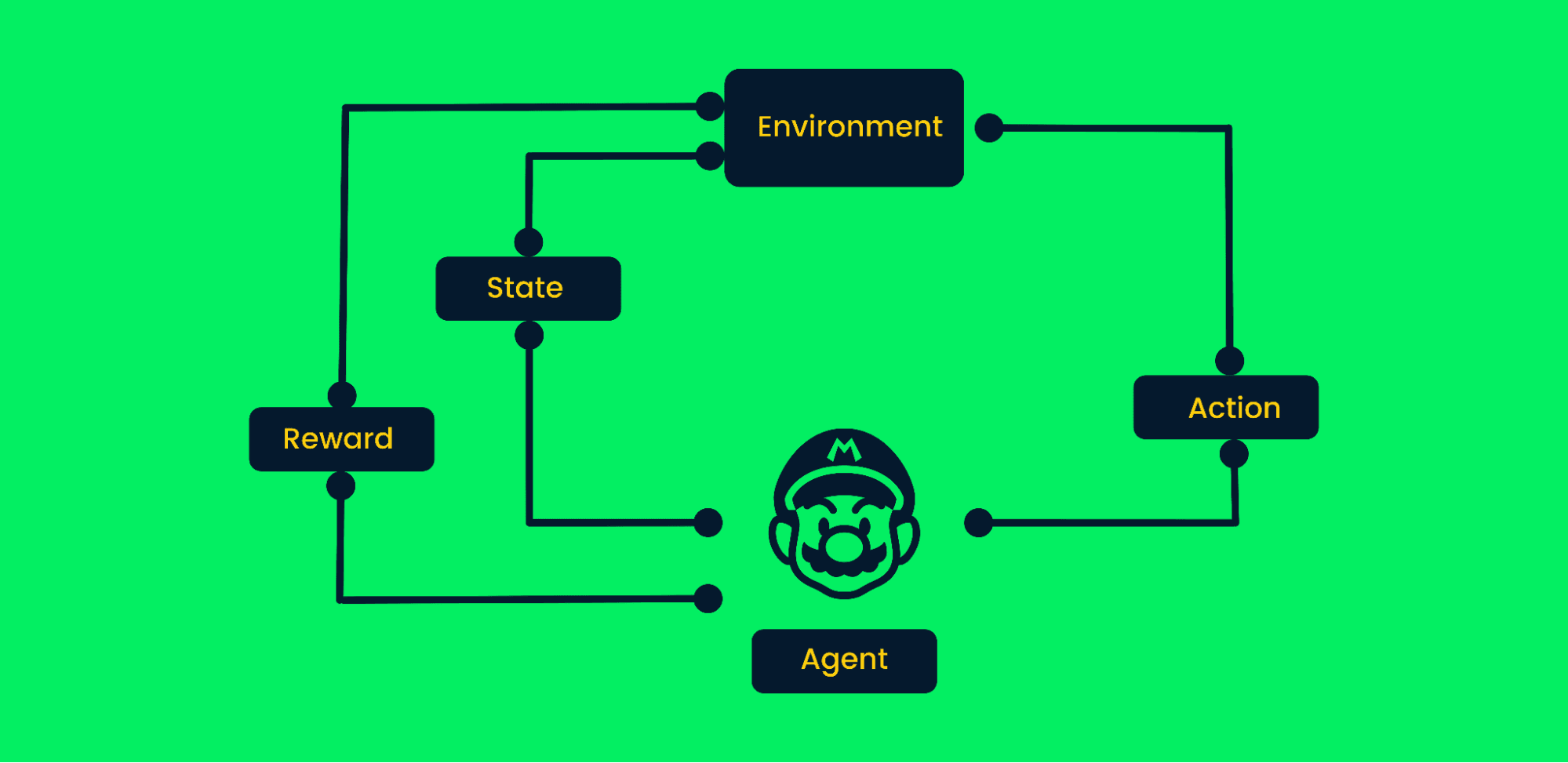
Reinforcement Learning Framework | Author
On-Policy learning algorithms evaluate and improve the same policy to act and update it. In other words, the policy that is used for updating and the policy that is used to take action are the same.
Target Policy == Behavior Policy
On-policy algorithms are Sarsa, Monte Carlo for On-Policy, Value Iteration, and Policy Iteration
Off-Policy Learning algorithms are completely different as the updated policy is different from the behavior policy. For example, in Q-learning, the agent learns from an optimal policy with the help of a greedy policy and takes action using other policies.
Target Policy != Behavior Policy
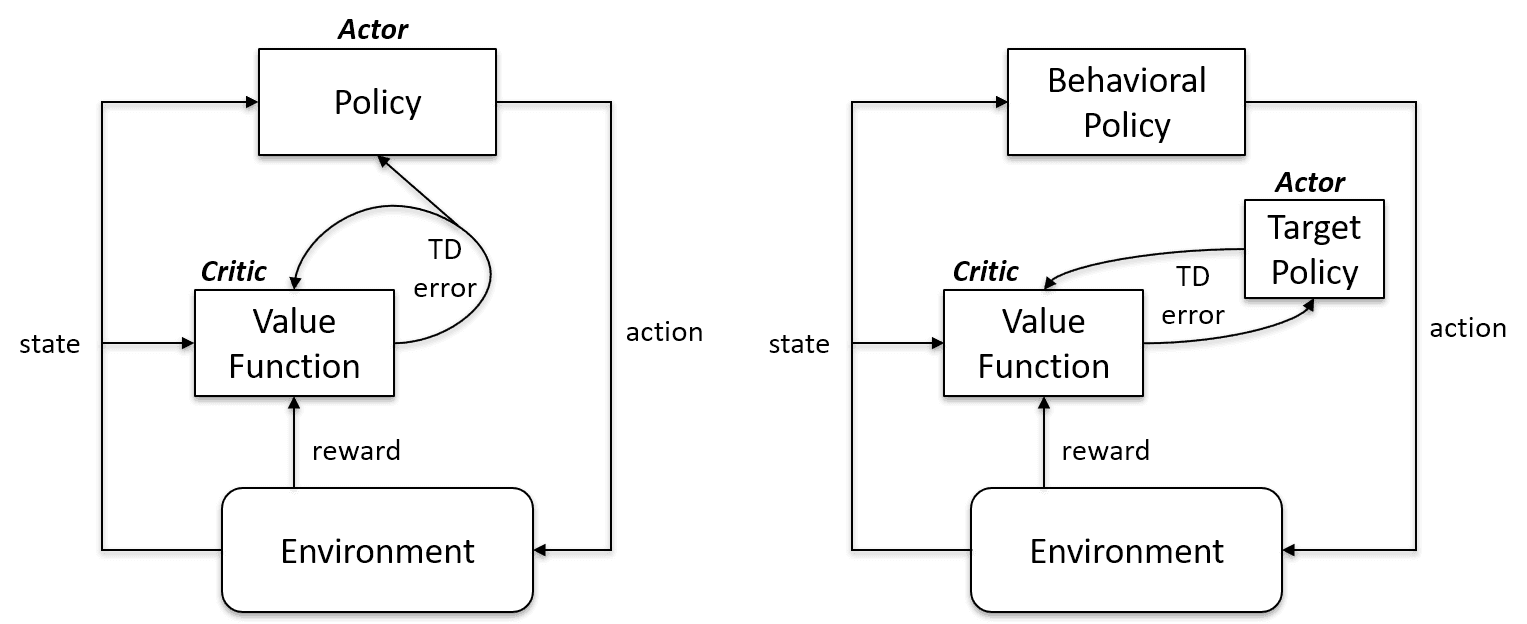
On-policy vs. Off-policy case | Artificial Intelligence Stack Exchange
Simple Q learning is great. It solves the problem on a smaller scale, but on a larger scale, it fails.
Imagine if the environment has 1000 states and 1000 actions per state. We will require a Q table of millions of cells. The game of chess and Go will require an even bigger table. This is where Deep Q-learning comes for the rescue.
It utilizes a neural network to approximate the Q value function. The neural networks recipe states as an input and outputs the Q-value of all possible actions.
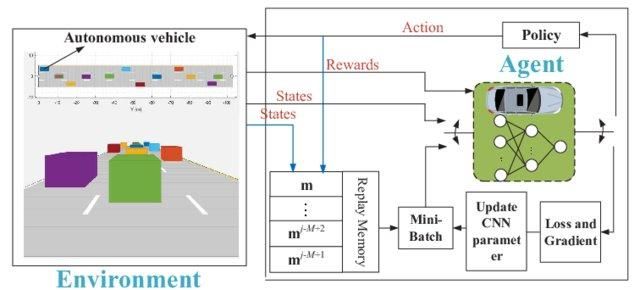
Deep Q-network for autonomous driving | researchgate
Below, we’ve outlined some potential questions the interviewer might ask you at some of the top tech companies:
Receiver operating characteristics (ROC) shows the trade-off between sensitivity and specificity.
The curve is plotted using the False positive rate (FP/(TN + FP)) and true positive rate (TP/(TP + FN))
The area under the curve (AUC) shows the model performance. If the area under the ROC curve is 0.5, then our model is completely random. The model with AUC close to 1 is the better model.
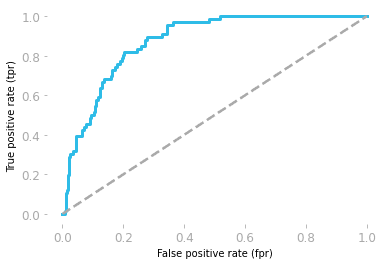
ROC curve by Hadrien Jean
For dimensionality reduction, we can use feature selection or feature extraction methods.
Feature selection is a process of selecting optimal features and dropping irrelevant features. We use Filter, Wrapper, and Embedded methods to analyze feature importance and remove less important features to improve model performance.
Feature extraction transforms the space with multiple dimensions into fewer dimensions. No information is lost during the process, and it uses fewer resources to process the data. The most common extraction techniques are Linear discriminant analysis (LDA), Kernel PCA, and Quadratic discriminant analysis.
In the case of a spam classifier, a logistics regression model will return the probability. We either use the probability of 0.8999 or convert it into class (Spam/Not Spam) using a threshold.
Usually, the threshold of a classifier is 0.5, but in some cases, we need to fine-tune it to improve the accuracy. The 0.5 threshold means that if the probability is equal to or above 0.5, it is spam, and if it is lower, then it is not spam.
To find the threshold, we can use Precision-Recall curves and ROC curves, grid search, and by manually changing the value to get a better CV.
Become a professional machine learning engineer by completing Machine Learning Scientist with Python career track.
Linear regression is used to understand the relation between features (X) and target (y). Before we train the model, we need to meet a few assumptions:
Note: the residuals in linear regression are the difference between actual and predicted values.
During coding interviews, you will be asked about machine learning problems, but in some cases, they will assess your Python skills by asking you general coding questions. Become an expert Python programmer by taking the Python Programmer career track.
Creating a bigram function is quite easy. You need to use two loops with the zip function.
It is quite easy if you break down the problem and use zip functions.
def bigram(text_list:list):
result = []
for ls in text_list:
words = ls.lower().split()
for bi in zip(words, words[1:]):
result.append(bi)
return result
text = ["Data drives everything", "Get the skills you need for the future of work"]
print(bigram(text))Results:
[('Data', 'drives'), ('drives', 'everything'), ('Get', 'the'), ('the', 'skills'), ('skills', 'you'), ('you', 'need'), ('need', 'for'), ('for', 'the'), ('the', 'future'), ('future', 'of'), ('of', 'work')]The activation function is a non-linear transformation in neural networks. We pass the input through the activation function before passing it to the next layer.
The net input value can be anything between -inf to +inf, and the neuron doesn't know how to bound the values, thus unable to decide the firing pattern. The activation function decides whether a neuron should be activated or not to bound the net input values.
Most common types of Activation Functions:
The answer is completely up to you. But before answering, you need to consider what business goal you want to achieve to set a performance metric and how you are going to acquire the data.
In a typical machine learning system design, we:
You need to make sure you are focusing on design rather than theory or model architecture. Make sure to talk about model inference and how improving it will increase the overall revenues.
Also, give an overview of why you selected a certain methodology over the other.
Learn more about building recommendation systems by taking a course on DataCamp.
Solving coding challenges and working on your Python skills will improve your chance of getting past the coding interview stage.
Before jumping into solving a problem, you need to understand the question. You simply need to create a boolean function that will return True if by shifting the alphabets in String B, you get String A.
A = 'abid'
B = 'bida'
can_shift(A, B) == Truedef can_shift(a, b):
if len(a) != len(b):
return False
for i in range(len(a)):
mut_a = a[i:] + a[:i]
if mut_a == b:
return True
return False
A = 'abid'
B = 'bida'
print(can_shift(A, B))
>>> TrueEnsemble learning is used to combine the insights of multiple machine learning models to improve the accuracy and performance metrics.
Simple ensemble methods:
Advance ensemble methods:
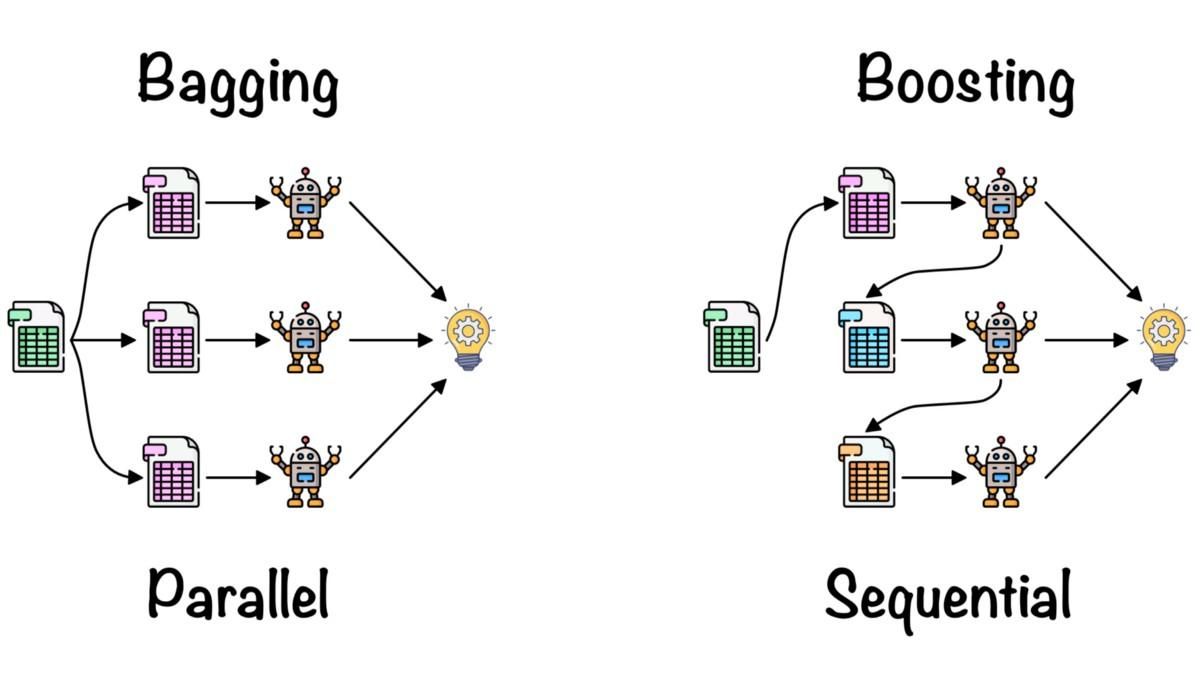
Bagging and Boosting by Fernando López
Learn more about averaging, bagging, stacking, and boosting by completing the Ensemble Methods in Python course.
It is important to know about the company you are applying to and the role. Make sure you review the job description and prepare accordingly. Most of the job applications will include tools, technologies, methodologies, and skills. Use this information and talk about them during the technical and non-technical interview stages.
Practicing Python, solving coding challenges, and making sure you are timing your practice. The interviewer won’t let you use all the time to come up with a solution. You can also use platforms like Leetcode, Code wars, and DataCamp to practice coding challenges.
Most hiring managers prepare questions from your previous project using GitHub repositories, resume, and portfolio. They will ask you to explain how you can overcome certain issues in a specific project. Don’t get overwhelmed; just review your portfolio projects. Don’t forget, you can use DataLab to showcase your projects.
You need to learn how to handle structured and unstructured tabular data, sound files, and image data. Learn various ways to augment, clean, and process the data. Learn to adjust the size of data based on the deep neural network architecture.
Reviewing mock machine learning interview questions is the best way to prepare for an interview. You need to review behavioral and situational, basic machine learning, coding, role-specific, and machine learning operations questions.
During the interview, you will be asked about the latest tools, technologies, models, and methodologies. Companies are looking for individuals who are in tune with the industry and who are eager to learn. You need to read blogs, research papers, and follow social media groups to understand the trend and get informed.
Machine learning is an ever-changing landscape. Every week you will see new state-of-the-art technology. Currently, it is a stable-diffusion text-to-image diffusion model.
In the latter part of the interview, you will be asked about system design. Explain how you will gather the data, process it, and build a machine learning solution. For example: How would you build a restaurant recommendation on Facebook?
It is always good to prepare yourself to answer these questions by reading about various machine learning systems on the internet. You don’t have to go deep; just learn about the steps or how to handle complex data.
As we conclude our exploration of essential machine learning interview questions, it's evident that succeeding in such interviews requires a blend of theoretical knowledge, practical skills, and an awareness of the latest trends and technologies in the field. From understanding the basic concepts like semi-supervised learning and algorithm selection, to delving into the complexities of specific algorithms like KNN, and grappling with role-specific challenges in NLP, computer vision, or reinforcement learning, the scope is vast.
It's crucial to remember that machine learning is not just about algorithms and models, but also about understanding and solving real-world problems. This means not only being adept at technical aspects but also being able to communicate your ideas effectively, understanding the business context, and staying curious and continuously learning.
Whether you are a beginner looking to break into the field or an experienced practitioner aiming to advance further, continuous learning and practice are key. DataCamp offers a comprehensive Machine Learning Scientist with Python track that provides a structured and in-depth way to enhance your skills. This track covers everything from the fundamentals to more advanced topics, helping you to stay updated and ready for any challenge that comes your way in an interview or in your professional career.
Machine Learning Courses
Course
Course
Course
Adel Nehme
15 min
Abid Ali Awan
15 min
Richmond Alake
13 min
Kurtis Pykes
9 min
Moez Ali
11 min
Abid Ali Awan






