curso
Pandas Joins for Spreadsheet Users
4 horas
3.7K
pandas es una biblioteca de Python muy utilizada para la ciencia de datos, el análisis y el machine learning, que ofrece una forma flexible e intuitiva de manejar conjuntos de datos de todos los tamaños. Una de las funcionalidades más importantes de pandas son las herramientas que proporciona para leer y escribir datos. Para los datos disponibles en formato tabular y almacenados como archivo CSV, puedes utilizar pandas para leerlos en memoria mediante la función read_csv(), que devuelve un DataFrame de pandas. Pero también hay otras funcionalidades. Por ejemplo, puedes utilizar pandas para realizar operaciones de fusión, remodelación, unión y concatenación.
En este artículo, aprenderás sobre la función read_csv() y cómo puedes modificar los parámetros para personalizar la salida que recibes una vez ejecutada la función. También cubriremos los diferentes métodos disponibles para un objeto dataframe de pandas, incluyendo cómo escribir dataframe de pandas en un archivo CSV y cómo aprender rápidamente más sobre tus datos a través de varios métodos y atributos.
Practica las funciones pandas con ejercicios prácticos de nuestro curso de Python Intermedio.
Nota: Consulta este DataCamp Workspace para seguir el código.
Antes de leer un archivo CSV en un dataframe de pandas, debes tener alguna idea de lo que contienen los datos. Por tanto, es recomendable que hojees el archivo antes de intentar cargarlo en la memoria: esto te dará una idea más clara de qué columnas son necesarias y cuáles pueden descartarse.
Escribamos un código para importar un archivo utilizando read_csv(). Entonces podremos hablar de lo que ocurre y de cómo podemos personalizar la salida que recibimos al leer los datos en la memoria.
import pandas as pd
# Read the CSV file
airbnb_data = pd.read_csv("data/listings_austin.csv")
# View the first 5 rows
airbnb_data.head()
Todo lo que ha pasado en el código anterior:
read_csv para que lea los datos en memoria como un dataframe de pandas. Pero hay mucho más en la función read_csv() .
El comportamiento por defecto de pandas es añadir un índice inicial al marco de datos devuelto por el archivo CSV que ha cargado en memoria. Sin embargo, puedes especificar explícitamente qué columna hacer como índice de la función read_csv configurando el parámetro index_col.
Ten en cuenta que el valor que asignes a index_col puede ser un nombre de cadena, un índice de columna o una secuencia de nombres de cadena o índices de columna. Asignar al parámetro una secuencia dará como resultado un multiIndex (una agrupación de datos por varios niveles).
Leamos de nuevo los datos y establezcamos la columna id como índice.
# Setting the id column as the index
airbnb_data = pd.read_csv("data/listings_austin.csv", index_col="id")
# airbnb_data = pd.read_csv("data/listings_austing.csv", index_col=0)
# Preview first 5 rows
airbnb_data.head()
¿Y si sólo quieres leer en memoria determinadas columnas porque no todas son importantes? Este es un escenario común que se da en el mundo real. Utilizando la función read_csv, puedes seleccionar sólo las columnas que necesites después de cargar el archivo, pero esto significa que debes saber qué columnas necesitas antes de cargar los datos si quieres realizar esta operación desde la función read_csv.
Si conoces las columnas que necesitas, estás de suerte; puedes ahorrar tiempo y memoria pasando un objeto tipo lista al parámetro usecols de la función read_csv.
# Defining the columns to read
usecols = ["id", "name", "host_id", "neighbourhood", "room_type", "price", "minimum_nights"]
# Read data with subset of columns
airbnb_data = pd.read_csv("data/listings_austin.csv", index_col="id", usecols=usecols)
# Preview first 5 rows
airbnb_data.head()
Apenas hemos arañado la superficie de las distintas formas de personalizar la salida de la función read_csv, pero profundizar más sería sin duda una sobrecarga de información.
Te recomendamos que marques como favorita la hoja de trucos Importación de datos en Python y que consultes Introducción a la importación de datos en Python para obtener más información. Si eso te parece demasiado fácil, también está el curso interactivo intermedio Importar datos en Python.
Una vez que sepas cómo leer un archivo CSV del almacenamiento local a la memoria, leer datos de otras fuentes es pan comido. En definitiva, es el mismo proceso, salvo que ya no pasas una ruta de archivo.
Supongamos que hay datos que quieres de una página web concreta; ¿cómo los leerías en memoria?
Utilizaremos como ejemplo el conjunto de datos Iris del repositorio de la UCI:
# Webpage URL
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
# Define the column names
col_names = ["sepal_length_in_cm",
"sepal_width_in_cm",
"petal_length_in_cm",
"petal_width_in_cm",
"class"]
# Read data from URL
iris_data = pd.read_csv(url, names=col_names)
iris_data.head() 
¡Voilà!
Te habrás dado cuenta de que hemos asignado una lista de cadenas al parámetro names de la función read_csv. Esto es sólo para que podamos renombrar las cabeceras de las columnas mientras leemos los datos en memoria.
El objeto más común de la biblioteca pandas es, con diferencia, el objeto dataframe. Es una estructura de datos bidimensional etiquetada, formada por filas y columnas que pueden ser de distintos tipos de datos (es decir, flotantes, numéricos, categóricos, etc.).
Conceptualmente, puedes pensar en un dataframe de pandas como en una hoja de cálculo, una tabla SQL o un diccionario de objetos de series, lo que te resulte más familiar. Lo bueno del dataframe de pandas es que viene con muchos métodos que te facilitan familiarizarte con tus datos lo más rápidamente posible.
Ya has visto uno de esos métodos: iris_data.head() que muestra las n primeras filas (por defecto son 5). El método "opuesto" a head() es tail(), que muestra las últimas n (5 por defecto) filas del objeto dataframe. Por ejemplo:
iris_data.tail()
Puedes descubrir rápidamente los nombres de las columnas utilizando el atributo columns de tu objeto dataframe:
# Discover the column names
iris_data.columns
"""
Index(['sepal_length_in_cm', 'sepal_width_in_cm', 'petal_length_in_cm',
'petal_width_in_cm', 'class'],
dtype='object')
"""Otro método importante que puedes utilizar en tu objeto dataframe es info(). Este método imprime un resumen conciso del marco de datos, incluyendo información sobre el índice, los tipos de datos, las columnas, los valores no nulos y el uso de memoria.
# Get summary information of the dataframe
iris_data.info()
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 150 entries, 0 to 149
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 sepal_length_in_cm 150 non-null float64
1 sepal_width_in_cm 150 non-null float64
2 petal_length_in_cm 150 non-null float64
3 petal_width_in_cm 150 non-null float64
4 class 150 non-null object
dtypes: float64(4), object(1)
memory usage: 6.0+ KB
"""DataFrame.describe() genera estadísticas descriptivas, incluidas las que resumen la tendencia central, la dispersión y la forma de la distribución del conjunto de datos. Si tus datos tienen valores perdidos, no te preocupes; no se incluyen en las estadísticas descriptivas.
Llamemos al método describir sobre el conjunto de datos Iris:
# Get descriptive statistics
iris_data.describe()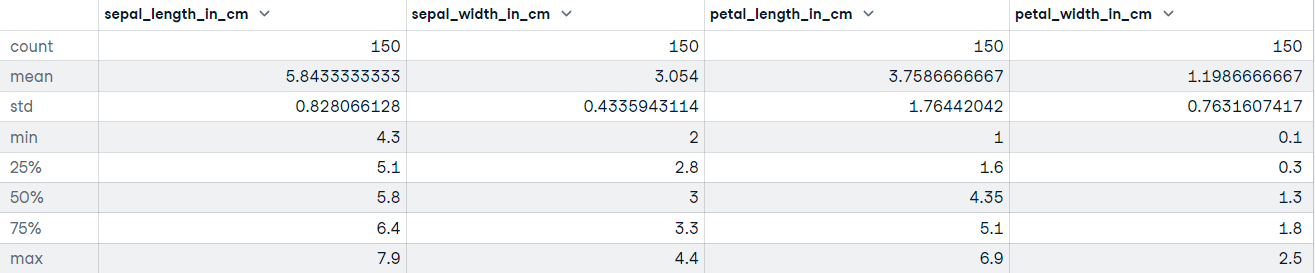
Otro método disponible para los objetos dataframe de pandas es to_csv(). Cuando hayas limpiado y preprocesado tus datos, el siguiente paso puede ser exportar el dataframe a un archivo; esto es bastante sencillo:
# Export the file to the current working directory
iris_data.to_csv("cleaned_iris_data.csv")Al ejecutar este código se creará un CSV en el directorio de trabajo actual llamado cleaned_iris_data.csv.
Pero, ¿y si quieres utilizar un delimitador diferente para marcar el principio y el final de una unidad de datos o quieres especificar cómo deben representarse los valores que faltan? Quizá no quieras que las cabeceras se exporten al archivo.
Pues bien, puedes ajustar los parámetros del método to_csv() para adaptarlos a los datos que quieras exportar.
Veamos algunos ejemplos de cómo puedes ajustar la salida de to_csv():
# Change the delimiter to a tab
iris_data.to_csv("tab_seperated_iris_data.csv", sep="\t")# Export data without the index
iris_data.to_csv("tab_seperated_iris_data.csv", sep="\t")
# If you get UnicodeEncodeError use this...
# iris_data.to_csv("tab_seperated_iris_data.csv", sep="\t", index=False, encoding='utf-8')# Replace missing values with "Unknown"
iris_data.to_csv("tab_seperated_iris_data.csv", sep="\t", na_rep="Unknown")# Do not include headers when exporting the data
iris_data.to_csv("tab_seperated_iris_data.csv", sep="\t", na_rep="Unknown", header=False)Recapitulemos lo que hemos tratado en este tutorial; has aprendido a:
read_csv() de la biblioteca pandas. read_csv().pandas.read_csv() to_csv(). En este tutorial, nos hemos centrado únicamente en la importación y exportación de datos desde la perspectiva de un archivo CSV; ahora ya tienes una buena idea de lo útil que es pandas a la hora de importar y exportar archivos CSV. CSV es uno de los formatos de almacenamiento de datos más comunes, pero no es el único. Existen otros formatos de archivo utilizados en la ciencia de datos, como parquet, JSON y excel.
En la web se alojan muchos conjuntos de datos útiles y de alta calidad, a los que puedes acceder mediante API, por ejemplo. Si quieres entender cómo manejar la carga de datos en Python con más detalle, el curso Introducción a la importación de datos en Python de DataCamp te enseñará todas las mejores prácticas.
También hay tutoriales sobre cómo importar datos JSON y HTML en pandas y una guía definitiva para principiantes sobre pandas. No dejes de consultarlos para profundizar en el framework de pandas.
Más información sobre Python y pandas
curso
curso
curso
tutorial
Karlijn Willems
20 min
tutorial
DataCamp Team
7 min
tutorial
Vidhi Chugh
15 min
tutorial
Natassha Selvaraj
30 min
tutorial
Abid Ali Awan
20 min
tutorial
DataCamp Team
19 min



