curso
Machine Learning with PySpark
4 horas
22.2K
En este artículo, hemos esbozado algunas de las preguntas más comunes de las entrevistas sobre aprendizaje automático que puede encontrar al solicitar un puesto en el sector o entrevistar a un candidato. Practicar estas preguntas y preparar las respuestas puede ayudarle a que la entrevista transcurra sin contratiempos.
Las preguntas básicas están relacionadas con terminologías, algoritmos y metodologías. Los entrevistadores formulan estas preguntas para evaluar los conocimientos técnicos del candidato.
El aprendizaje semisupervisado es una mezcla de aprendizaje supervisado y no supervisado. El algoritmo se entrena con una mezcla de datos etiquetados y no etiquetados. Generalmente, se utiliza cuando tenemos un conjunto de datos etiquetados muy pequeño y un gran conjunto de datos sin etiquetar.
En términos sencillos, el algoritmo no supervisado se utiliza para crear clústeres y mediante el uso de datos etiquetados existentes para etiquetar el resto de los datos no etiquetados. Un algoritmo semisupervisado asume la asunción de continuidad, la asunción de cluster y la asunción de manifold.
Suele utilizarse para ahorrar el coste de adquisición de datos etiquetados. Por ejemplo, la clasificación de secuencias de proteínas, el reconocimiento automático del habla y los coches autónomos.
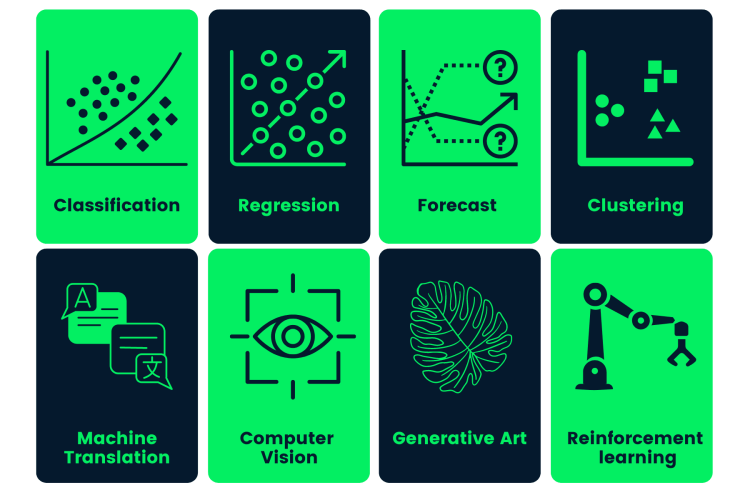
Además del conjunto de datos, necesita un caso de uso empresarial o los requisitos de la aplicación. Puede aplicar el aprendizaje supervisado y no supervisado a los mismos datos.
Generalmente:
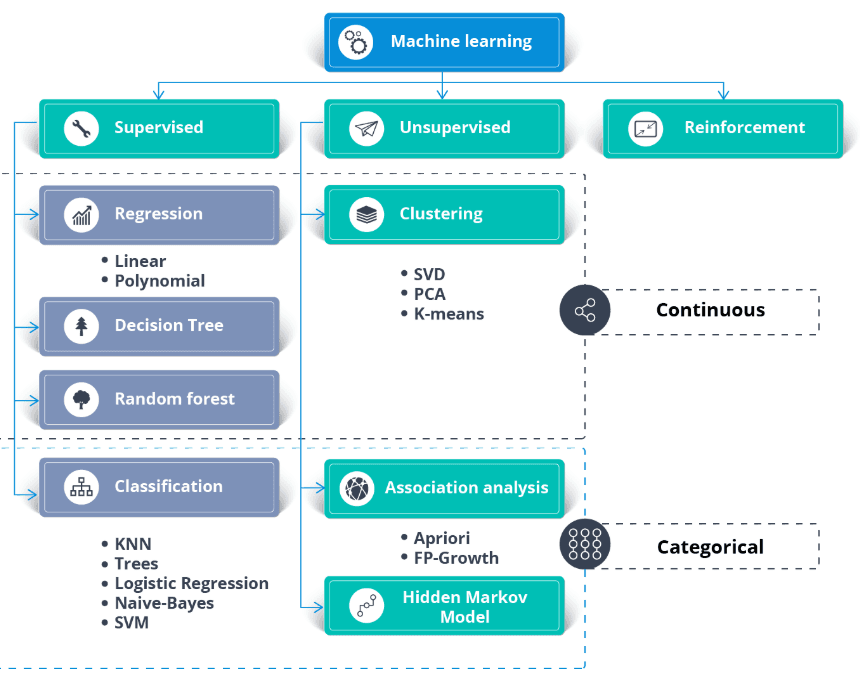
Imagen de thecleverprogrammer
Aprenda los fundamentos del aprendizaje automático siguiendo nuestro curso.
El K Nearest Neighbor (KNN) es un clasificador de aprendizaje supervisado. Utiliza la proximidad para clasificar etiquetas o predecir la agrupación de puntos de datos individuales. Podemos utilizarlo para la regresión y la clasificación. El algoritmo KNN es no paramétrico, lo que significa que no hace una suposición subyacente de la distribución de los datos.
En el clasificador KNN:
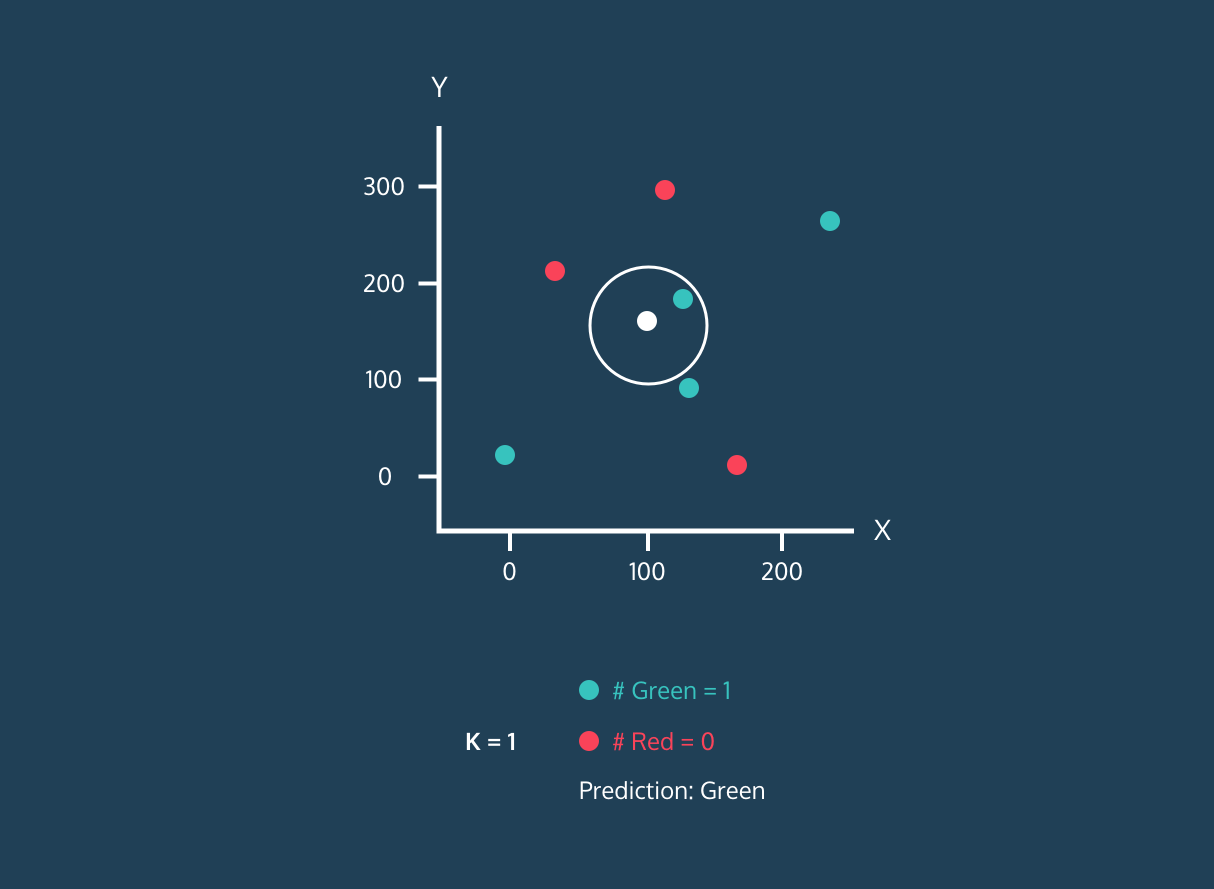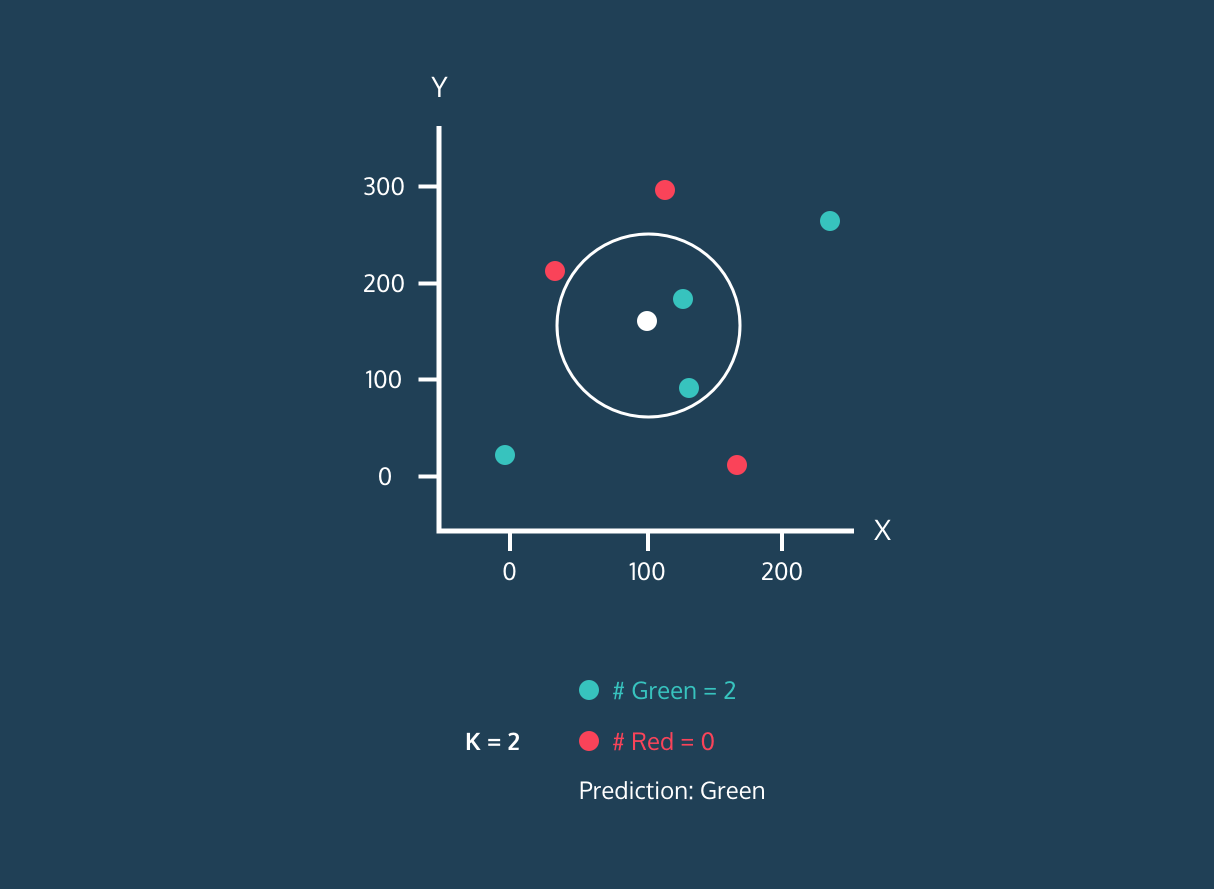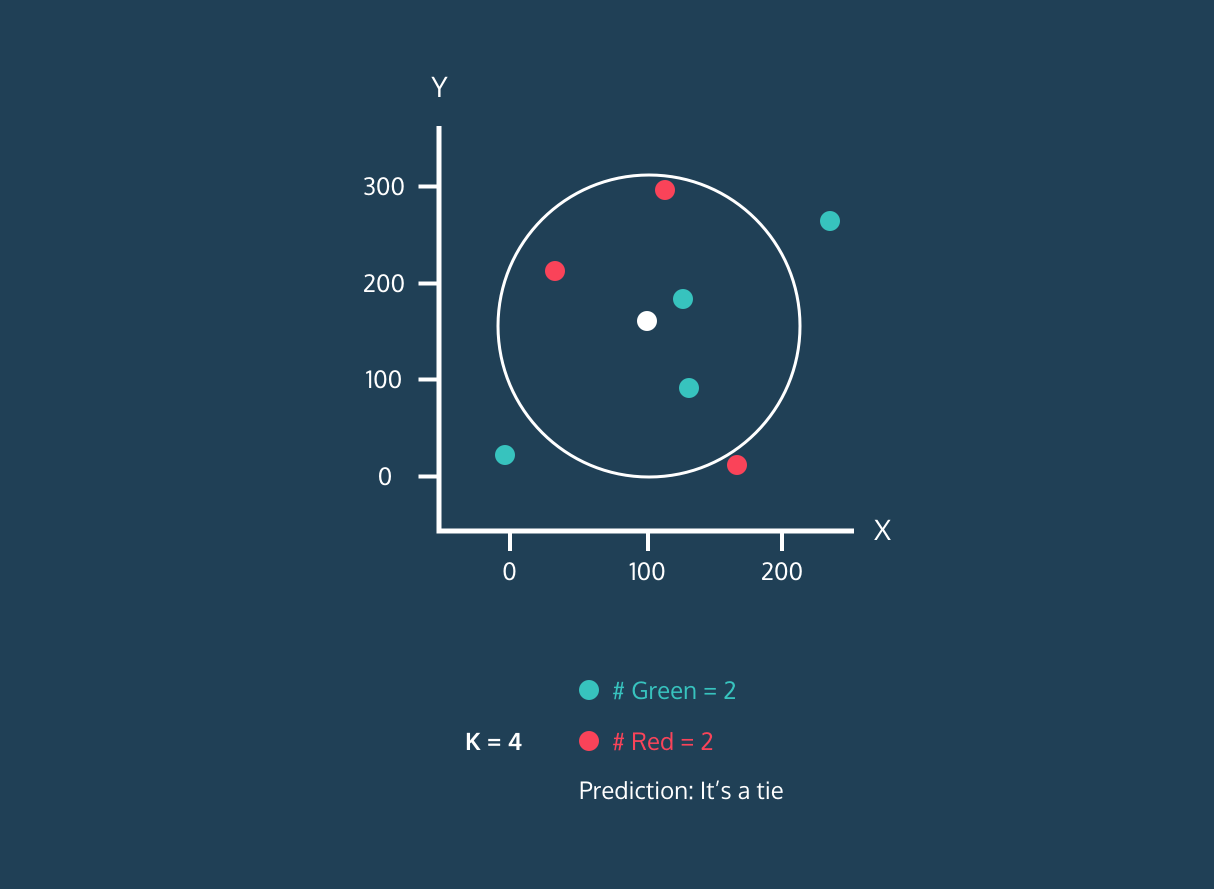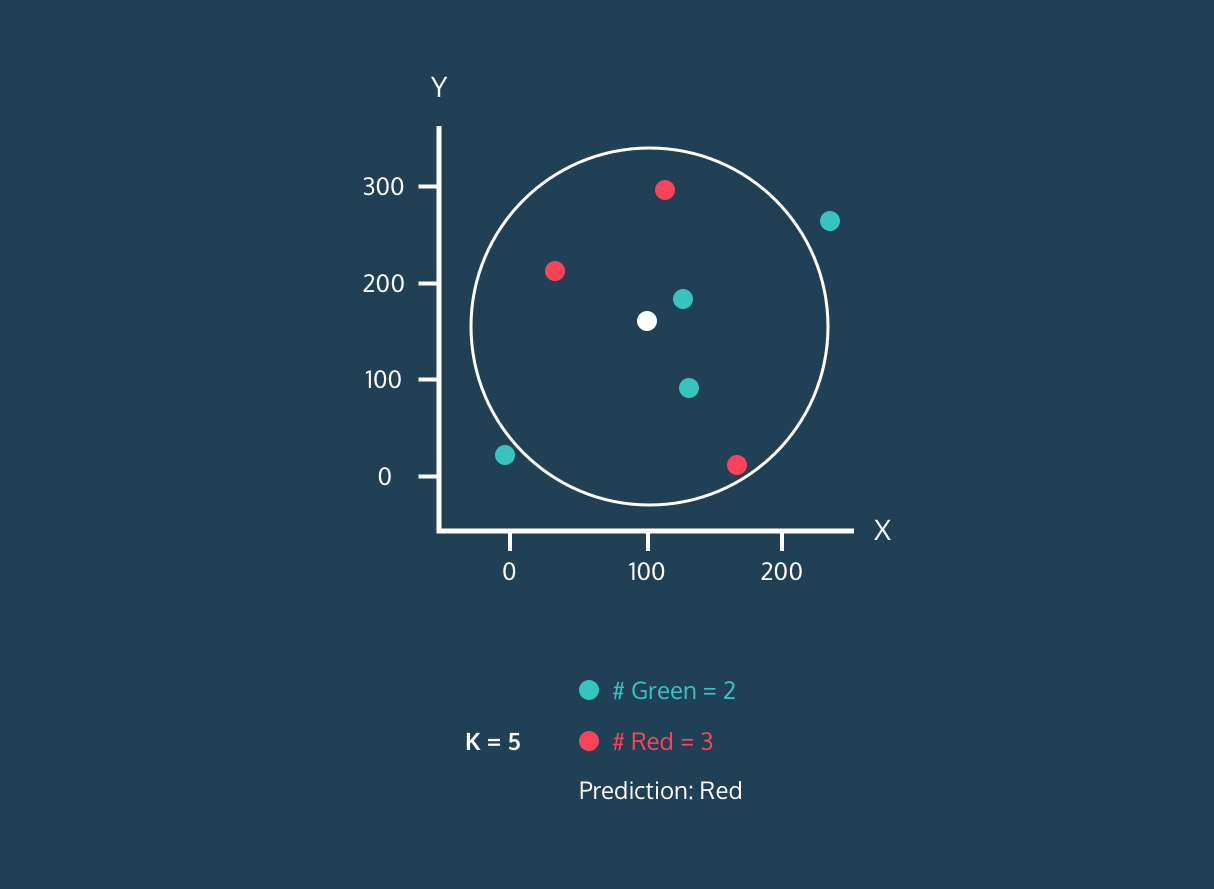
Imagen de Codesigner's Dev Story
Aprenda todo sobre los modelos de clasificación y regresión de aprendizaje supervisado realizando un breve curso.
La importancia de las características se refiere a las técnicas que asignan una puntuación a las características de entrada en función de su utilidad para predecir una variable objetivo. Desempeña un papel fundamental para comprender la estructura subyacente de los datos, el comportamiento del modelo y hacerlo más interpretable.
Existen varios métodos para determinar la importancia de una característica:
Comprender la importancia de las características es crucial para optimizar el modelo, reducir el sobreajuste eliminando las características no informativas y mejorar la interpretabilidad del modelo, especialmente en ámbitos en los que es fundamental comprender el proceso de decisión del modelo.
En la entrevista técnica se evalúan más sus conocimientos sobre los procesos y su capacidad para gestionar la incertidumbre. El responsable de contratación formulará preguntas de aprendizaje automático en la entrevista sobre procesamiento de datos, formación y validación de modelos y algoritmos avanzados.
Sí. La mayoría de los algoritmos utilizan la distancia euclídea entre puntos de datos, y si el valor de la característica varía mucho, los resultados serán muy diferentes. En la mayoría de los casos, los valores atípicos hacen que los modelos de aprendizaje automático funcionen peor en el conjunto de datos de prueba.
También utilizamos el escalado de características para reducir el tiempo de convergencia. El descenso de gradiente tardará más en alcanzar los mínimos locales si las características no están normalizadas.
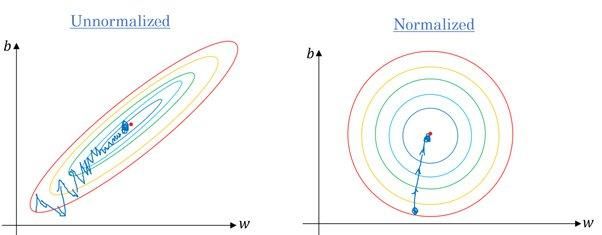
Gradiente sin y con escala | Quora
Los conocimientos de ingeniería de funciones están muy solicitados. Puedes aprenderlo todo sobre el tema realizando un curso de DataCamp, como el de Feature Engineering for Machine Learning in Python.
El sesgo bajo se produce cuando el modelo predice valores cercanos al valor real. Imita el conjunto de datos de entrenamiento. El modelo no tiene generalización, lo que significa que si se prueba con datos no observados, dará malos resultados.
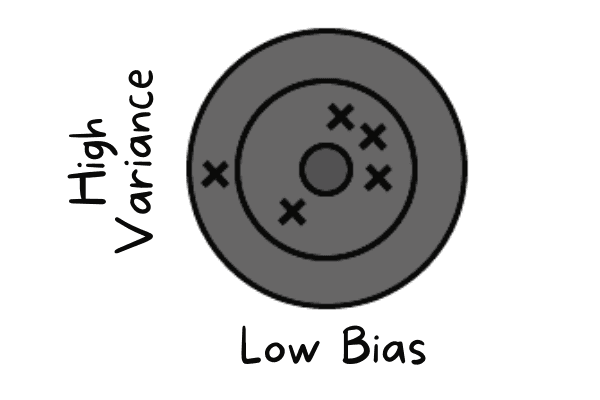
Bajo sesgo y alta varianza | Autor
Para solucionar estos problemas, utilizaremos algoritmos de bagging, ya que dividen un conjunto de datos en subconjuntos mediante un muestreo aleatorio. A continuación, generamos conjuntos de modelos utilizando estas muestras con un único algoritmo. Después, combinamos la predicción del modelo mediante clasificación por votación o promediado.
Para una varianza elevada, podemos utilizar técnicas de regularización. Penalizaba los coeficientes más altos del modelo para reducir su complejidad. Además, podemos seleccionar las características más importantes del gráfico de importancia de características y entrenar el modelo.
La validación cruzada se utiliza para evaluar el rendimiento del modelo con solidez y evitar el sobreajuste. Por lo general, las técnicas de validación cruzada eligen muestras aleatorias de los datos y las dividen en conjuntos de datos de entrenamiento y de prueba. El número de divisiones se basa en el valor K.
Por ejemplo, si K = 5, habrá cuatro pliegues para el tren y uno para la prueba. Se repetirá cinco veces para medir el modelo realizado en pliegues separados.
No podemos hacerlo con un conjunto de datos de series temporales porque no tiene sentido utilizar el valor del futuro para predecir el valor del pasado. Existe una dependencia temporal entre las observaciones, y sólo podemos dividir los datos en una dirección, de modo que los valores del conjunto de datos de prueba sean posteriores al conjunto de datos de entrenamiento.
El diagrama muestra que la división en pliegues k de los datos de series temporales es unidireccional. Los puntos azules son el conjunto de entrenamiento, los rojos son el conjunto de prueba y los blancos son datos no utilizados. Como podemos observar con cada iteración, vamos avanzando con el conjunto de entrenamiento mientras que el conjunto de prueba permanece delante del conjunto de entrenamiento, no seleccionado aleatoriamente.
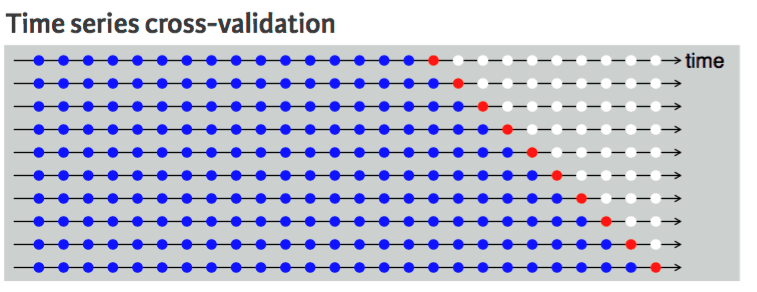
Validación cruzada de series temporales | Guía de programación en R de UC Business Analytics
Aprenda sobre manipulación, análisis, visualización y modelado de datos de series temporales cursando Series Temporales con Python.
La mayoría de los puestos de aprendizaje automático que se ofrecen en LinkedIn, Glassdoor y Indeed son específicos de una función. Por ello, durante la entrevista, se centrarán en preguntas específicas sobre el puesto. Para el puesto de ingeniero de visión por ordenador, el responsable de contratación se centrará en cuestiones de procesamiento de imágenes.
Imagine una imagen de 250 X 250 y una primera capa oculta totalmente conectada con 1000 unidades ocultas. Para esta imagen, las características de entrada son 250 X 250 X 3 = 187.500, y la matriz de pesos en la primera capa oculta será una matriz de 187.500 X 1000 dimensiones. Estos números son enormes para el almacenamiento y el cálculo, y para combatir este problema, utilizamos operaciones de convolución.
Aprenda procesamiento de imágenes con un breve curso de Procesamiento de imágenes en Python
Si no dispone de datos suficientes para entrenar una red neuronal convolucional, puede utilizar el aprendizaje por transferencia para entrenar su modelo y obtener resultados de última generación. Necesita un modelo preentrenado que se haya entrenado en un conjunto de datos general pero más amplio. Después, lo afinarás con datos más recientes entrenando las últimas capas de los modelos.
El aprendizaje por transferencia permite a los científicos de datos entrenar modelos en datos más pequeños utilizando menos recursos, computación y almacenamiento. Puede encontrar fácilmente modelos preentrenados de código abierto para diversos casos de uso, y la mayoría de ellos tienen licencia comercial, lo que significa que puede utilizarlos para crear su aplicación.
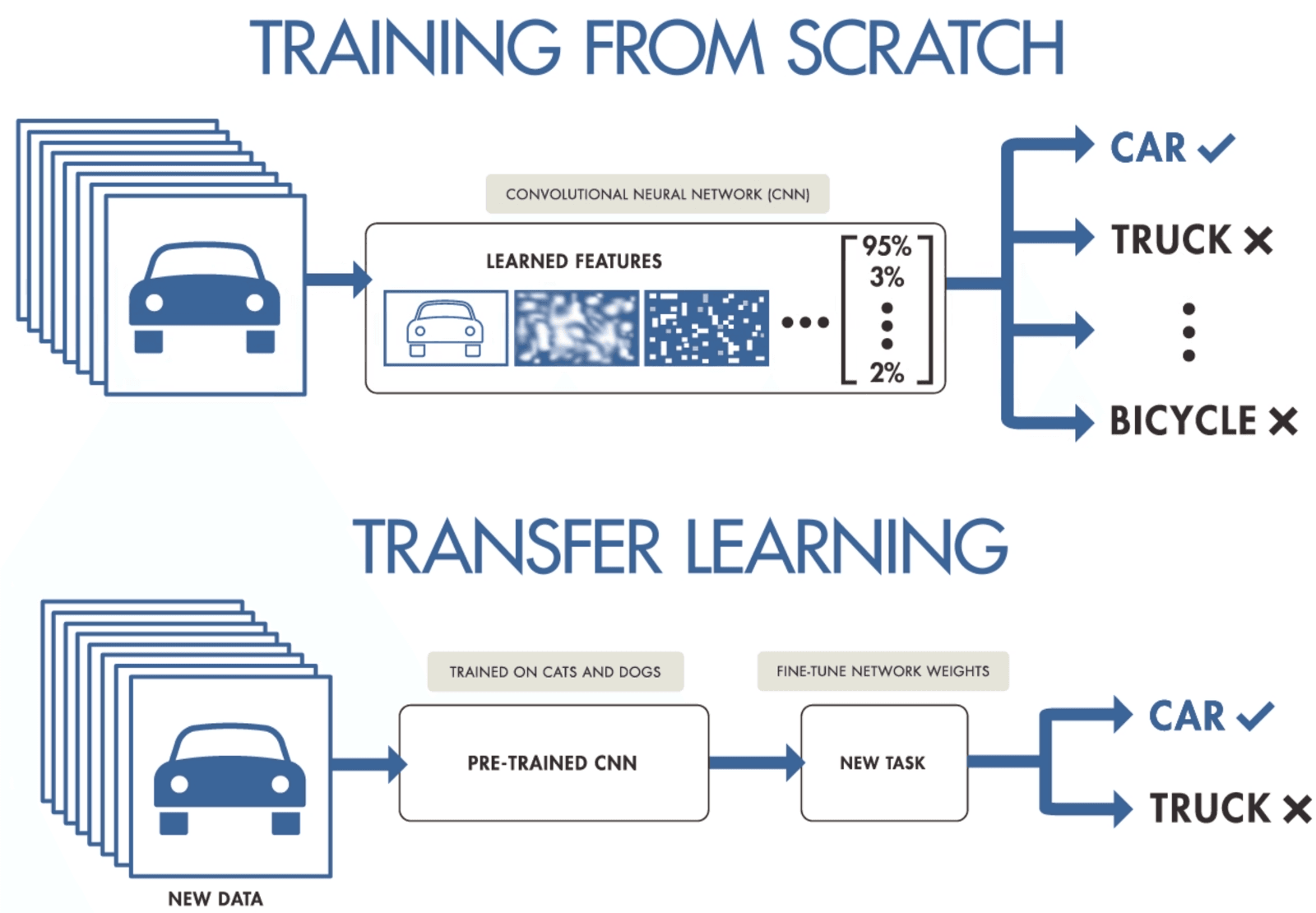
Aprendizaje por transferencia de purnasai gudikandula
YOLO es un algoritmo de detección de objetos basado en redes neuronales convolucionales, y puede proporcionar resultados en tiempo real. El algoritmo YOLO requiere una única pasada hacia delante a través de la CNN para reconocer el objeto. Predice tanto varias probabilidades de clase como casillas límite.
El modelo se entrenó para detectar diversos objetos, y las empresas están utilizando el aprendizaje por transferencia para perfeccionarlo con nuevos datos para aplicaciones modernas como la conducción autónoma, la conservación de la fauna y la seguridad.
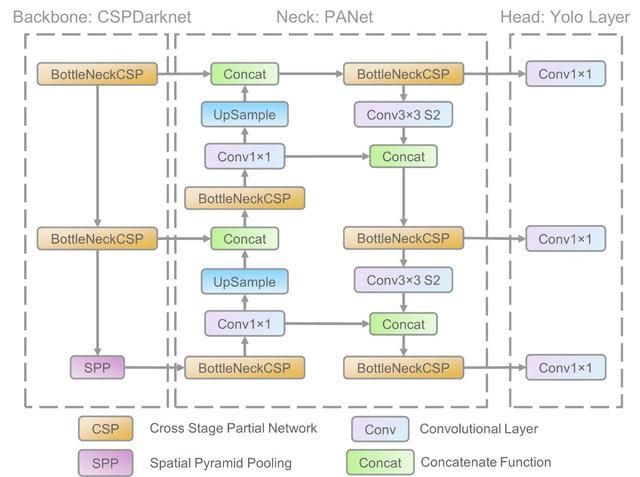
Arquitectura del modelo YOLO V5 | researchgate
El análisis sintáctico, también conocido como análisis sintáctico o análisis sintáctico, es un análisis de texto que nos indica el significado lógico de la frase o parte de la frase. Se centra en la relación entre las palabras y la estructura gramatical de las frases. También se puede decir que es el procesamiento de análisis del lenguaje natural mediante el uso de reglas gramaticales.
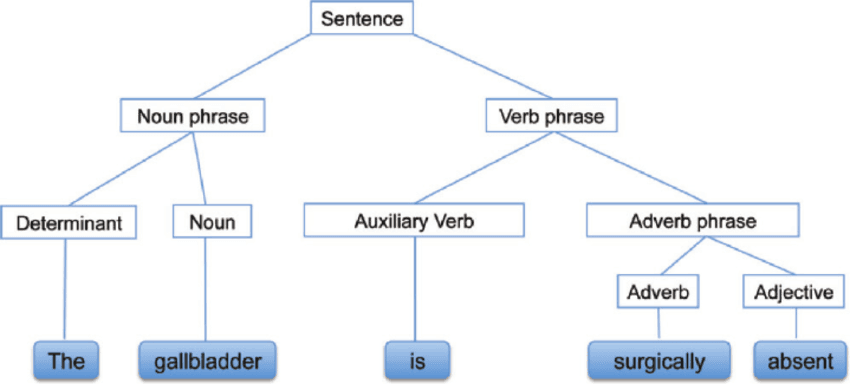
Análisis sintáctico | researchgate
El stemming y la lematización son técnicas de normalización utilizadas para minimizar la variación estructural de las palabras de una frase.
El despunte elimina los afijos añadidos a la palabra y la deja en su forma base. Por ejemplo, Cambiar a Chang.
Es ampliamente utilizado por los motores de búsqueda para la optimización del almacenamiento. En lugar de almacenar todas las formas de las palabras, sólo almacena las raíces.
La lematización convierte la palabra en su forma lema. La salida es la palabra raíz en lugar de la palabra raíz. Tras la lematización, obtenemos la palabra válida que significa algo. Por ejemplo, Cambiar para cambiar.

Stemming vs. Lemmatización | Autor
Es responsabilidad de los ingenieros de aprendizaje automático optimizar la inferencia del modelo. Debido al gran tamaño de los modelos lingüísticos, cada vez es más difícil desplegar modelos en producción y reducir el tiempo de inferencia a microsegundos.
Para mejorar el tiempo de inferencia, podemos utilizar:
Aprenda los fundamentos de la PNL completando el curso de habilidades de Procesamiento del Lenguaje Natural en Python .
El aprendizaje por refuerzo utiliza el método de ensayo y error para alcanzar objetivos. Es un algoritmo orientado a objetivos y aprende del entorno dando los pasos correctos para maximizar la recompensa acumulada.
En el típico aprendizaje por refuerzo:
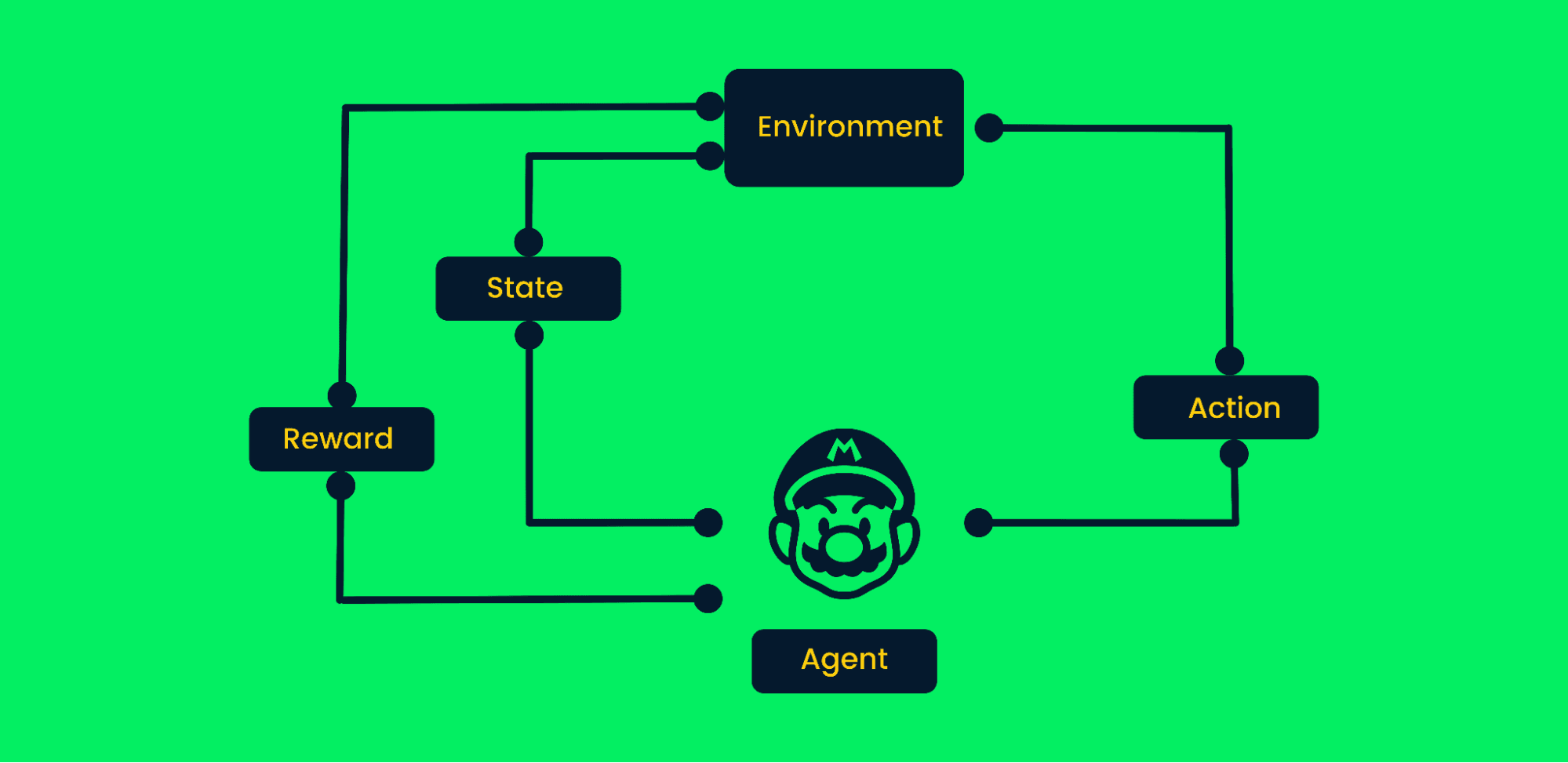
Marco de aprendizaje por refuerzo | Autor
Los algoritmos de aprendizaje On-Policy evalúan y mejoran la misma política para actuar y actualizarla. En otras palabras, la política que se utiliza para actualizar y la política que se utiliza para actuar son la misma.
Política de objetivos == Política de comportamiento
Los algoritmos sobre políticas son Sarsa, Monte Carlo para políticas, Iteración de valores e Iteración de políticas.
Los algoritmos de aprendizaje fuera de política son completamente diferentes, ya que la política actualizada es distinta de la política de comportamiento. Por ejemplo, en el aprendizaje Q, el agente aprende de una política óptima con la ayuda de una política codiciosa y actúa utilizando otras políticas.
Política de objetivos = Política de comportamiento
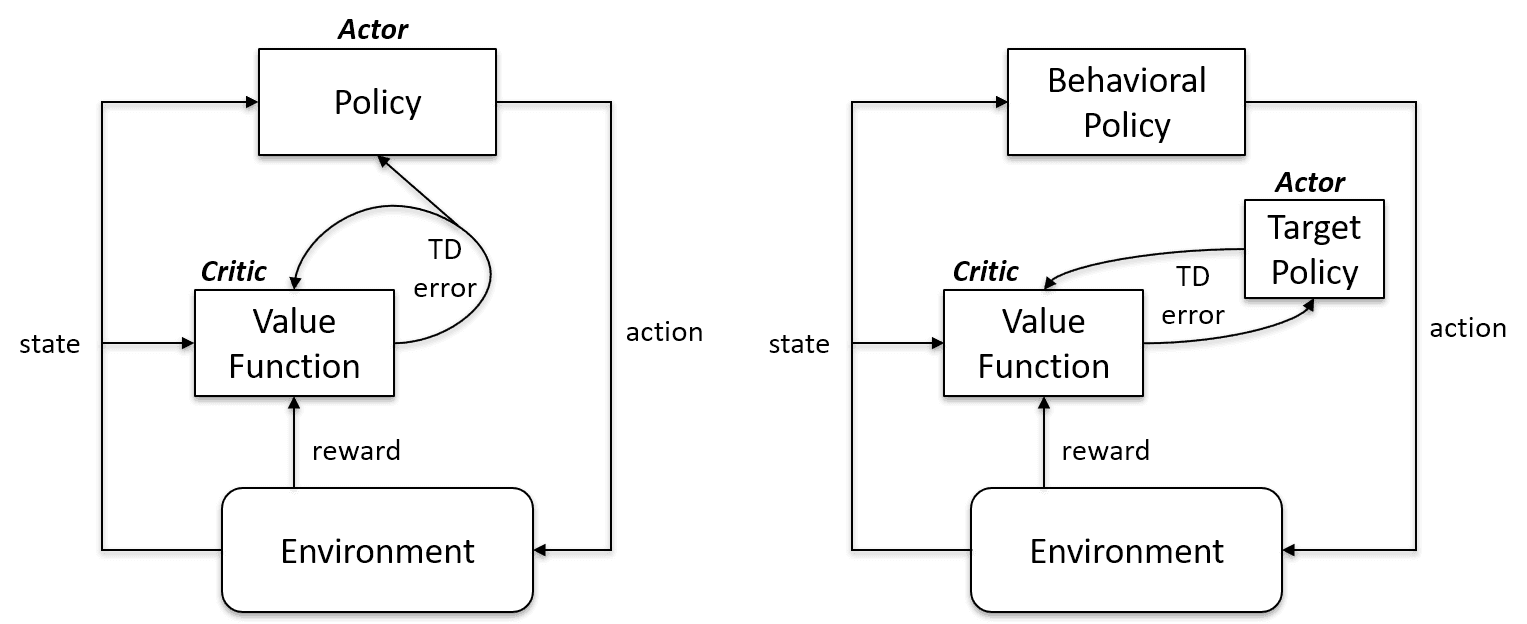
Política frente a política Inteligencia Artificial Stack Exchange
El aprendizaje Q simple es genial. Resuelve el problema a menor escala, pero a mayor escala, fracasa.
Imagina que el entorno tiene 1000 estados y 1000 acciones por estado. Necesitaremos una tabla Q de millones de celdas. El juego del ajedrez y del Go requerirá una mesa aún más grande. Aquí es donde Deep Q-learning viene al rescate.
Utiliza una red neuronal para aproximar la función de valor Q. Las redes neuronales recetan estados como entrada y emiten el valor Q de todas las acciones posibles.
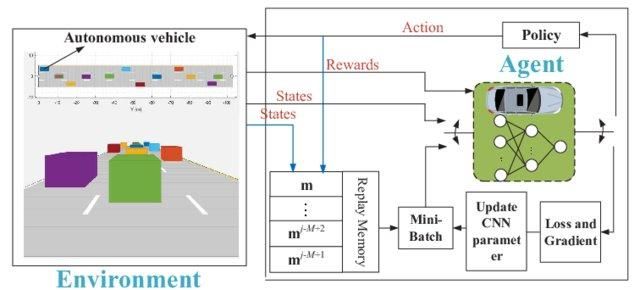
Redes Q profundas para la conducción autónoma | researchgate
A continuación te presentamos algunas de las posibles preguntas que podría hacerte el entrevistador en algunas de las principales empresas tecnológicas:
Las características operativas del receptor (ROC) muestran el equilibrio entre sensibilidad y especificidad.
La curva se traza utilizando la tasa de falsos positivos (FP/(TN + FP)) y la tasa de verdaderos positivos (TP/(TP + FN))
El área bajo la curva (AUC) muestra el rendimiento del modelo. Si el área bajo la curva ROC es 0,5, entonces nuestro modelo es completamente aleatorio. El modelo con AUC cercano a 1 es el mejor modelo.
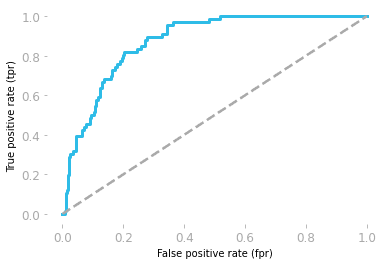
Curva ROC de Hadrien Jean
Para reducir la dimensionalidad, podemos utilizar métodos de selección o extracción de características.
La selección de características es un proceso que consiste en seleccionar las características óptimas y descartar las irrelevantes. Utilizamos los métodos Filter, Wrapper e Embedded para analizar la importancia de las características y eliminar las menos importantes para mejorar el rendimiento del modelo.
La extracción de características transforma el espacio con múltiples dimensiones en menos dimensiones. No se pierde información durante el proceso y utiliza menos recursos para procesar los datos. Las técnicas de extracción más comunes son el análisis discriminante lineal (LDA), el PCA de kernel y el análisis discriminante cuadrático.
En el caso de un clasificador de spam, un modelo de regresión logística devolverá la probabilidad. Utilizamos la probabilidad de 0,8999 o la convertimos en clase (Spam/Not Spam) utilizando un umbral.
Normalmente, el umbral de un clasificador es de 0,5, pero en algunos casos es necesario ajustarlo para mejorar la precisión. El umbral de 0,5 significa que si la probabilidad es igual o superior a 0,5, se trata de spam, y si es inferior, no.
Para encontrar el umbral, podemos utilizar curvas de Precisión-Recuperación y curvas ROC, búsqueda en cuadrícula y cambiando manualmente el valor para obtener un mejor CV.
Conviértase en un ingeniero de aprendizaje automático profesional completando la trayectoria profesional de Científico de aprendizaje automático con Python.
La regresión lineal se utiliza para comprender la relación entre las características (X) y el objetivo (y). Antes de entrenar el modelo, tenemos que cumplir algunos supuestos:
Nota: los residuos de la regresión lineal son la diferencia entre los valores reales y los previstos.
Durante las entrevistas de codificación, te preguntarán sobre problemas de aprendizaje automático, pero en algunos casos evaluarán tus conocimientos de Python haciéndote preguntas generales de codificación. Conviértete en un experto programador de Python cursando la carrera de Programador de Python.
Crear una función bigram es bastante fácil. Es necesario utilizar dos bucles con la función zip.
Es bastante fácil si desglosas el problema y utilizas funciones zip.
def bigram(text_list:list):
result = []
for ls in text_list:
words = ls.lower().split()
for bi in zip(words, words[1:]):
result.append(bi)
return result
text = ["Data drives everything", "Get the skills you need for the future of work"]
print(bigram(text))Resultados:
[('Data', 'drives'), ('drives', 'everything'), ('Get', 'the'), ('the', 'skills'), ('skills', 'you'), ('you', 'need'), ('need', 'for'), ('for', 'the'), ('the', 'future'), ('future', 'of'), ('of', 'work')]La función de activación es una transformación no lineal en las redes neuronales. Pasamos la entrada por la función de activación antes de pasarla a la capa siguiente.
El valor neto de entrada puede estar comprendido entre -inf y +inf, y la neurona no sabe cómo delimitar los valores, por lo que es incapaz de decidir el patrón de disparo. La función de activación decide si una neurona debe activarse o no para acotar los valores de entrada de la red.
Tipos más comunes de Funciones de Activación:
La respuesta depende totalmente de usted. Pero antes de responder, debe plantearse qué objetivo empresarial desea alcanzar para establecer una métrica de rendimiento y cómo va a adquirir los datos.
En el diseño típico de un sistema de aprendizaje automático:
Hay que asegurarse de centrarse en el diseño más que en la teoría o la arquitectura del modelo. Asegúrese de hablar de la inferencia de modelos y de cómo su mejora aumentará los ingresos globales.
Explique también por qué ha elegido una metodología u otra.
Aprenda más sobre la creación de sistemas de recomendación realizando un curso en DataCamp.
Resolver retos de cod ificación y trabajar tus conocimientos de Python mejorará tus posibilidades de superar la fase de la entrevista de codificación.
Antes de lanzarse a resolver un problema, hay que entender la pregunta. Basta con crear una función booleana que devuelva True si al desplazar los alfabetos de la cadena B, se obtiene la cadena A.
A = 'abid'
B = 'bida'
can_shift(A, B) == Truedef can_shift(a, b):
if len(a) != len(b):
return False
for i in range(len(a)):
mut_a = a[i:] + a[:i]
if mut_a == b:
return True
return False
A = 'abid'
B = 'bida'
print(can_shift(A, B))
>>> TrueEl aprendizaje conjunto se utiliza para combinar los conocimientos de varios modelos de aprendizaje automático con el fin de mejorar la precisión y las métricas de rendimiento.
Métodos de conjunto sencillos:
Métodos de ensemble avanzados:
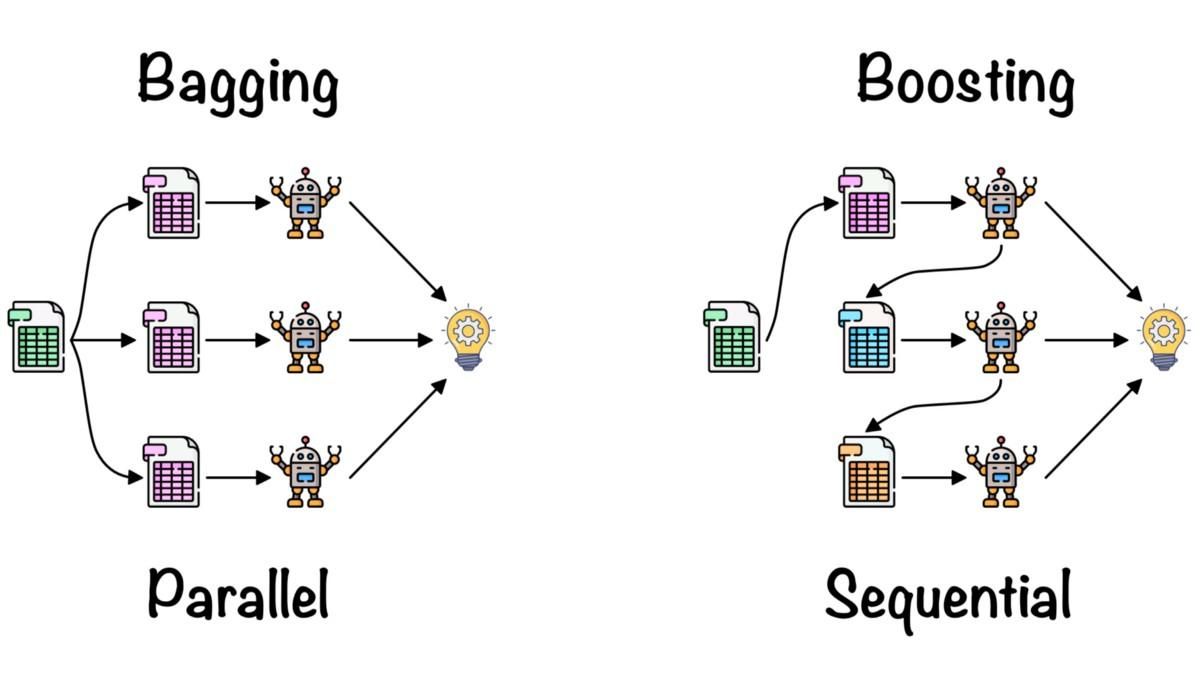
Bagging y Boosting por Fernando López
Aprenda más sobre promediado, bagging, stacking y boosting completando el curso Ensemble Methods in Python.
Es importante conocer la empresa a la que se presenta y el puesto. Asegúrate de revisar la descripción del puesto y prepárate en consecuencia. La mayoría de las solicitudes de empleo incluirán herramientas, tecnologías, metodologías y competencias. Utilice esta información y hable de ella durante las fases de entrevista técnica y no técnica.
Practicar Python, resolver retos de codificación y asegurarse de que está cronometrando su práctica. El entrevistador no te dejará emplear todo el tiempo en idear una solución. También puedes utilizar plataformas como Leetcode, Code wars y DataCamp para practicar retos de codificación.
La mayoría de los responsables de contratación preparan las preguntas a partir de tu proyecto anterior utilizando los repositorios de GitHub, el currículum y la cartera. Le pedirán que explique cómo puede superar determinados problemas en un proyecto concreto. No se agobie; limítese a revisar los proyectos de su cartera. No olvides que puedes utilizar DataLab para mostrar tus proyectos.
Hay que aprender a manejar datos tabulares estructurados y no estructurados, archivos de sonido y datos de imagen. Aprenda varias formas de aumentar, limpiar y procesar los datos. Aprende a ajustar el tamaño de los datos en función de la arquitectura de la red neuronal profunda.
La mejor manera de prepararse para una entrevista es repasar simulacros de preguntas de aprendizaje automático. Debe repasar preguntas sobre comportamiento y situaciones, aprendizaje automático básico, codificación, funciones específicas y operaciones de aprendizaje automático.
Durante la entrevista, le preguntarán sobre las últimas herramientas, tecnologías, modelos y metodologías. Las empresas buscan personas en sintonía con el sector y con ganas de aprender. Hay que leer blogs, artículos de investigación y seguir a los grupos de las redes sociales para entender la tendencia e informarse.
El aprendizaje automático es un paisaje en constante cambio. Cada semana verá nuevas tecnologías de vanguardia. Actualmente, se trata de un modelo de difusión texto-imagen de difusión estable.
En la última parte de la entrevista, se le preguntará por el diseño del sistema. Explique cómo recopilará los datos, los procesará y creará una solución de aprendizaje automático. Por ejemplo: ¿Cómo crearías una recomendación de restaurantes en Facebook?
Siempre es bueno prepararse para responder a estas preguntas leyendo en Internet sobre diversos sistemas de aprendizaje automático. No es necesario profundizar; basta con conocer los pasos o cómo manejar datos complejos.
A medida que concluimos nuestra exploración de las preguntas esenciales para una entrevista sobre aprendizaje automático, es evidente que para tener éxito en este tipo de entrevistas se requiere una mezcla de conocimientos teóricos, habilidades prácticas y un conocimiento de las últimas tendencias y tecnologías en este campo. Desde la comprensión de conceptos básicos como el aprendizaje semisupervisado y la selección de algoritmos, hasta la profundización en las complejidades de algoritmos específicos como KNN, pasando por la resolución de problemas específicos de la PNL, la visión por ordenador o el aprendizaje por refuerzo.
Es fundamental recordar que el aprendizaje automático no consiste únicamente en algoritmos y modelos, sino también en comprender y resolver problemas del mundo real. Esto significa no sólo ser experto en aspectos técnicos, sino también ser capaz de comunicar sus ideas con eficacia, comprender el contexto empresarial y mantener la curiosidad y el aprendizaje continuos.
Tanto si es un principiante que quiere introducirse en este campo como si es un profesional con experiencia que quiere seguir avanzando, el aprendizaje y la práctica continuos son fundamentales. DataCamp ofrece una pista completa de Machine Learning Scientist con Python que proporciona una forma estructurada y en profundidad para mejorar sus habilidades. Este tema abarca desde los fundamentos hasta temas más avanzados, ayudándole a mantenerse actualizado y preparado para cualquier reto que se le presente en una entrevista o en su carrera profesional.
Cursos de aprendizaje automático
curso
curso
curso
blog
Abid Ali Awan
23 min
blog
Javier Canales Luna
8 min
blog
Abid Ali Awan
16 min
blog
Chloe Lubin
17 min
blog
Abid Ali Awan
20 min
blog
Abid Ali Awan
23 min