Supervised Machine Learning Cheat Sheet
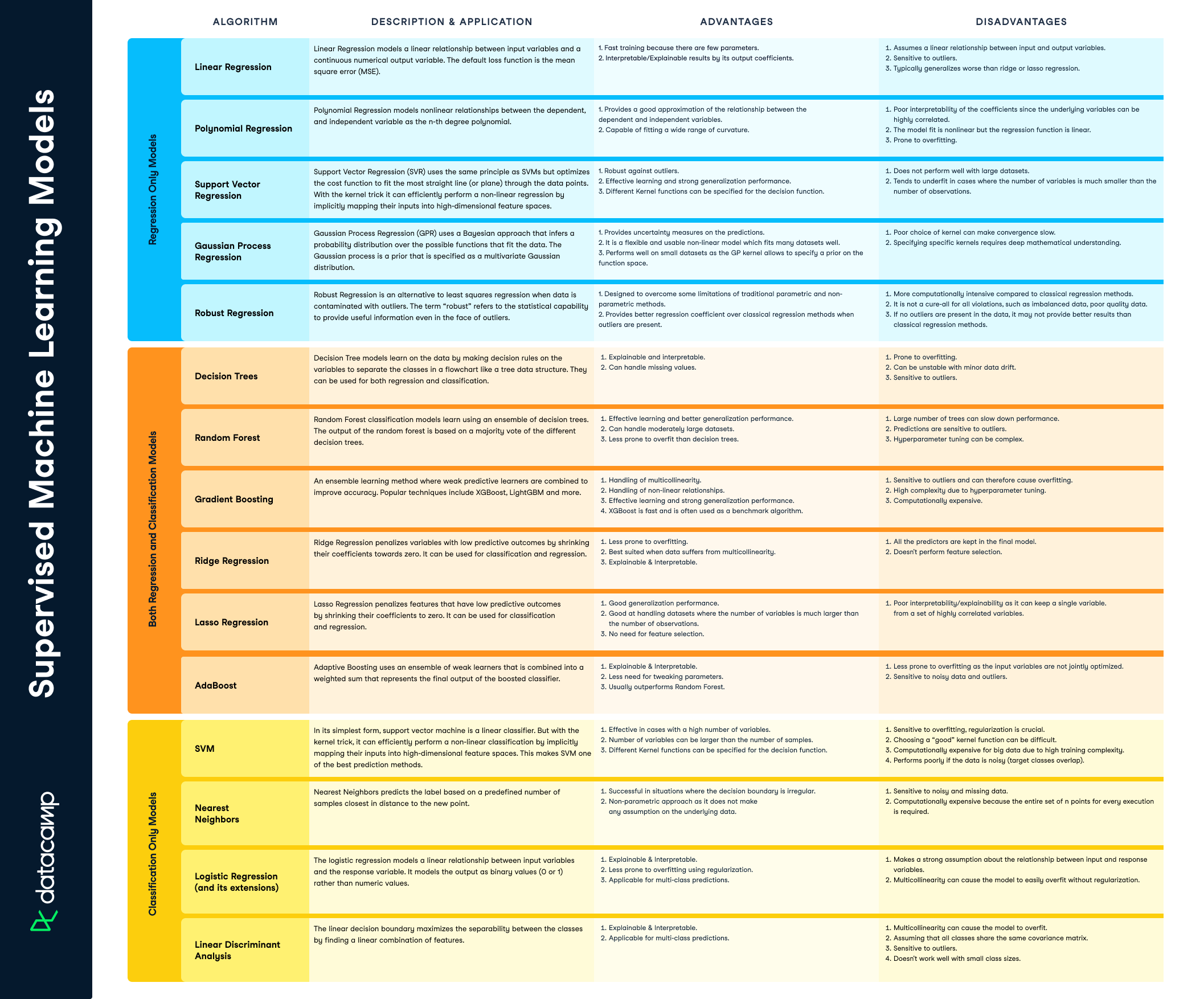
In this cheat sheet, you'll have a guide around the top supervised machine learning algorithms, their advantages and disadvantages, and use-cases.
Dec 2022 · 5 min read
When working with machine learning models, it's easy to try them all out without understanding what each model does and when to use them. In this cheat sheet, you'll find a handy guide describing the most widely used supervised machine learning models, their advantages, disadvantages, and some key use cases.
Have this cheat sheet at your fingertips
Download PDFHave this cheat sheet at your fingertips
Download PDFTopics
RelatedSee MoreSee More
blog
Supervised Machine Learning
Discover what supervised machine learning is, how it compares to unsupervised machine learning and how some essential supervised machine learning algorithms work

Moez Ali
8 min
blog
10 Top Machine Learning Algorithms & Their Use-Cases
Machine learning is arguably responsible for data science and artificial intelligence’s most prominent and visible use cases. In this article, learn about machine learning, some of its prominent use cases and algorithms, and how you can get started.

Vidhi Chugh
15 min
cheat sheet
Unsupervised Machine Learning Cheat Sheet
In this cheat sheet, you'll have a guide around the top unsupervised machine learning algorithms, their advantages and disadvantages and use cases.

Richie Cotton
9 min
cheat sheet
Machine Learning Cheat Sheet
In this cheat sheet, you'll have a guide around the top machine learning algorithms, their advantages and disadvantages, and use-cases.
Richie Cotton
8 min
cheat sheet
Scikit-Learn Cheat Sheet: Python Machine Learning
A handy scikit-learn cheat sheet to machine learning with Python, including some code examples.

Karlijn Willems
4 min
tutorial
Support Vector Machines with Scikit-learn Tutorial
In this tutorial, you'll learn about Support Vector Machines, one of the most popular and widely used supervised machine learning algorithms.

Avinash Navlani
15 min