

course
Understanding Data Engineering
2 hours
230.1K
Get your team access to the full DataCamp library, with centralized reporting, assignments, projects and more
When your friend tells you a statistic you don’t trust, you can ask to know the source of the statistic to verify its accuracy. Tracing information back to its source is crucial in establishing trust. This same principle applies to data.
Data lineage is a complete history of your data, from its source, through each transformation, to its final endpoint. This record provides a clear picture of the data's journey.
A data lineage offers complete transparency by documenting each step in the data pipeline, from its initial collection to its final analysis. This visibility is crucial in building trust, allowing interested parties to see exactly how your data has been processed and transformed.
You can think of this as showing your work in math class. In class, showing your work allows the teacher to see each step in your problem-solving process and proves that you didn’t cheat off your neighbor. A data lineage is like showing your work for your pipeline.
Showing your work on your math homework also helps the teacher (and you) understand where you made a mistake if you ended up with the wrong answer. This can help you correct the mistake and improve your understanding of the subject going forward.
Similarly, showing your work in a data lineage can help you find mistakes in a pipeline. Tracing errors back to their source is often a daunting task when errors occur in data. A comprehensive data lineage simplifies this process by allowing you to follow the data’s path to find where things went wrong. With this faster debugging process, you will have better data quality, which fosters trust.
You can learn more about ensuring data quality in this Introduction to Data Quality course.
Data provenance is a metadata record of the lineage of the data. Many industries have regulations that require proof of data provenance, especially those that handle sensitive information, like healthcare and finance.
Showing proof of data provenance involves demonstrating where data originated and how it has been handled. Data lineage provides an audit trail that meets these requirements, showing the entire data lifecycle. In addition to fostering trust, an audit trail can demonstrate your data’s adherence to data privacy laws, governance policies, and other regulations.
A complete data lineage records the path data takes at every step. Here’s an example of how data can flow from its source to a visualization.
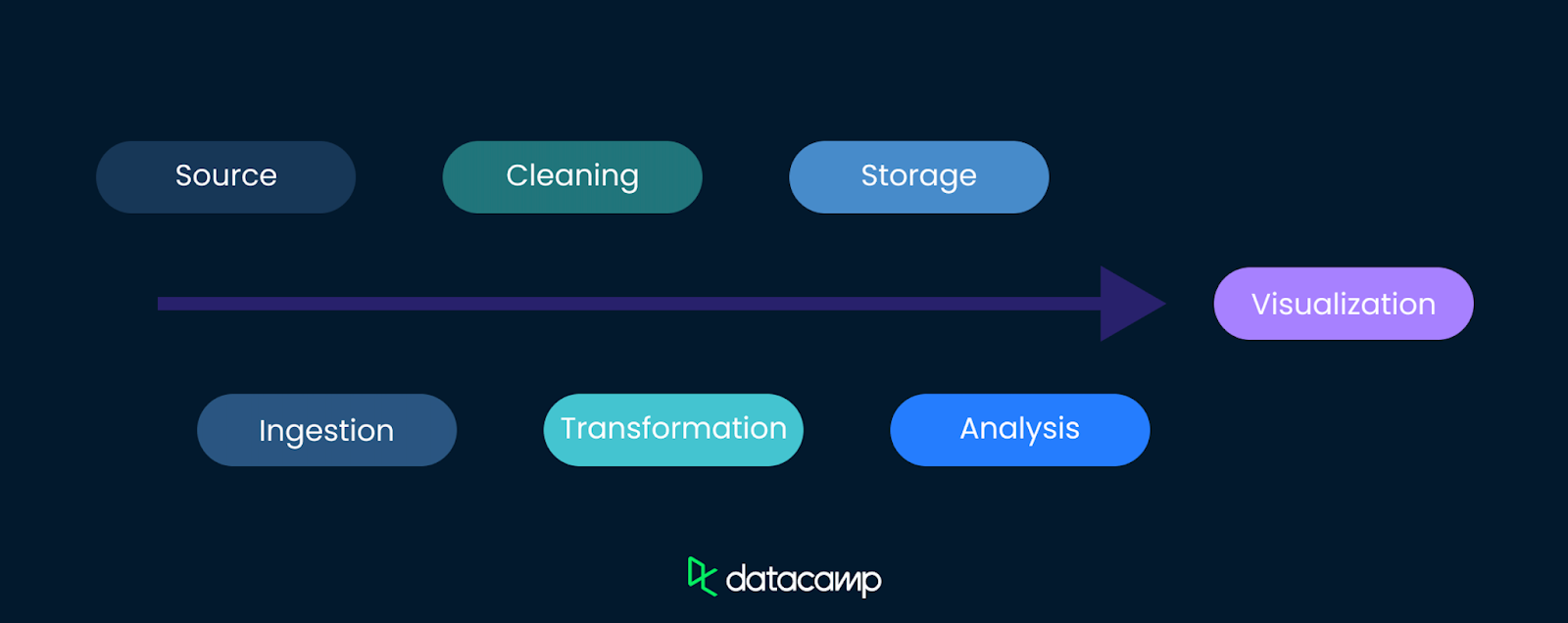
Data lineage starts at the source, which can include databases, APIs, sensors, surveys, or other data collection points. Understanding where data originates is the first and most important step in tracking its journey.
The source of the data provides context and background to the data. It can also give a hint about any biases and limitations in the data’s collection.
To demonstrate the importance of the data source, consider these hypothetical datasets and their sources.
|
Dataset |
Source |
Potential Biases/Limitations |
|
Hydration needs |
Company that sells bottled water |
May overestimate hydration needs to promote product sales. |
|
Blood pressure data in patients on different diets |
World-renowned research hospital |
Less likely to have significant bias, but potential for funding bias or selection bias in patient samples. |
|
Internet usage data in rural areas of developing countries |
Small NGO with limited resources |
May lack resources for comprehensive data collection, potentially leading to sampling bias or limited geographic coverage. |
|
Energy consumption and environmental impact of renewable energy |
Large oil company |
May downplay the benefits of renewable energy or overstate challenges to protect existing business interests. |
|
Prevalence of cardiovascular diseases |
Centers for Disease Control and Prevention (CDC) |
Reputable source, but potential for limitations in data collection methodologies or underreporting in certain demographics. |
|
Safety and efficiency of a new line of electric cars |
Car manufacturer producing the electric vehicles |
May overstate safety and efficiency to promote sales, potential lack of transparency in testing methodologies. |
|
Effectiveness of a new drug |
Independent watchdog organization |
Less likely to have significant bias, but potential for funding bias or conflicts of interest if ties to pharmaceutical companies exist. |
|
Customer satisfaction rates with a new smartphone |
Smartphone manufacturing company |
May inflate satisfaction rates to promote sales, potential for biased survey design or selective sampling. |
When a friend of mine from the United States visited Australia, she told the locals that it was currently over 100° in her hometown. They were more shocked than she expected until everyone realized that the US uses Fahrenheit and Australia uses Celsius. They thought she meant 100 °C, which is 212 °F! But she meant 100 °F, which is about 37 °C.
Thankfully, this misunderstanding was quickly resolved in person, but imagine a similar scenario within a dataset. Imagine a dataset containing temperature transformed from Fahrenheit to Celsius, but the unit label wasn’t changed, so it still said Fahrenheit. That could give you some really weird results!
This demonstrates why documenting data transformations is an important part of a data lineage. If an end user of the data, like a data analyst, sees results in their analyses that don’t make sense (like a city regularly experiencing boiling air temperatures), they can easily look back at the data lineage, see the transformation that wasn’t labeled, and correct the problem.
As data moves from its source to its final destination, it often undergoes numerous transformations, including cleaning, filtering, and aggregation processes that shape the data for its intended use. However, each of these transformations also changes the way the data is interpreted and needs to be documented.
A clear data lineage documents these transformations, ensuring that every change is recorded and can be traced back, enhancing transparency. This increases trust in your data and makes debugging easier.
The final stage in your data flow is where the data is stored and used. This can be in data warehouses, reporting tools, or other analytical platforms. Data lineage tracks the data all the way to these endpoints, providing a complete picture of its journey and ensuring that stakeholders can trust the data they are seeing.
Documenting the destination of your data is also important for security purposes, as it provides a record of who has access to which data.
Setting up data lineage might seem straightforward—just track where data comes from and what’s done to it. However, several challenges can complicate this process. Let’s consider a few.
One of the primary challenges in creating a data lineage is the size and complexity of many modern data pipelines. Modern data environments often involve intricate data flows that span multiple systems and platforms. Keeping track of these detailed pathways requires robust tools and careful planning.
A simple pipeline with one input source and limited transformations may be relatively simple to make a data lineage for. But if you have a complex pipeline with multiple inputs, many transformations, and perhaps several destinations, keeping track of it all in a data lineage becomes more complicated. But it also becomes more necessary.
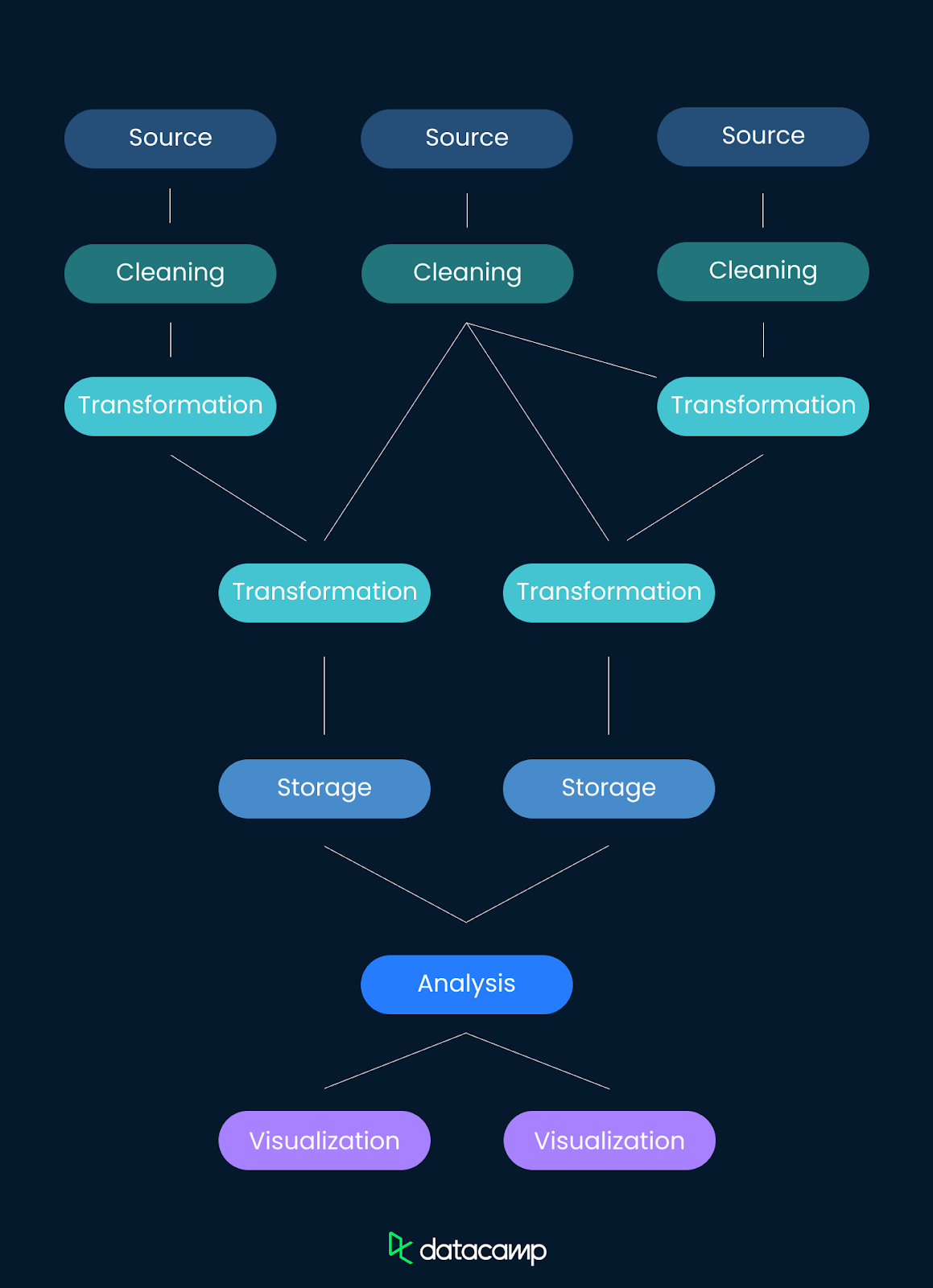
Data lineage can be documented manually or automatically. Manual documentation of data lineage can be time-consuming and error-prone. Manually tracking data movements and transformations, especially in a large operation, is not only inefficient but also increases the risk of inaccuracies, undermining the trust that data lineage aims to build.
For very small pipelines completely controlled by one person, manual data lineage may be sufficient. But as things get more complicated, the data lineage documentation should be more automated. In the next section, we’ll go over some resources to help you do that.
If data lineage wasn't initially incorporated into a data pipeline, integrating it retroactively can be time-consuming and resource-intensive. Adapting current infrastructure to support comprehensive data lineage tracking often requires significant changes, which may be a barrier for some organizations. This is one reason why it’s important to integrate data lineage solutions from the beginning.
If you are not planning to document your data lineage manually, you’ll need a few key components to create one: you’ll need to collect metadata about your datasets and have a catalog for that metadata.
Metadata is essentially data about data. It refers to information such as your data's origin, structure, transformations, and usage. Effective metadata management involves collecting metadata from various sources, tracking data transformations, and documenting data movements. This collection and management is often automated, ensuring every change is recorded and traceable. This provides a comprehensive view of your data lineage.
Data catalogs are comprehensive repositories that store metadata about an organization’s data assets, including their origins, transformations, and destinations. They often automate the discovery, description, and organization of data assets, making it easier to manage data lineage, foster trust, and ensure compliance with data governance policies.
There are many off-the-shelf tools available to help you track your data lineage. Here’s a short list of popular tools.
|
Tool Name |
Type |
Key Features |
|
Paid |
Centralized metadata management, data flow visualization, supports wide range of data sources |
|
|
Paid |
Detailed views of data movement and transformation, ensures data quality and compliance |
|
|
Paid |
Advanced lineage visualization, interactive diagrams, data governance integration |
|
|
Paid |
Data integration and integrity tools, detailed tracking of data transformations |
|
|
Open Source |
Metadata management, captures data lineage, designed for Hadoop systems |
|
|
Open Source |
Automates data flows, built-in lineage tracking features, monitors data movements |
|
|
Open Source |
Metadata service for collecting and visualizing data lineage, integrates with various systems |
|
|
Open Source |
Machine learning algorithms for automatic data flow detection and documentation |
In addition to the tools listed above, many ETL/ELT tools, data visualization tools, and data governance platforms include lineage features. These tools automate the documentation of data extraction, transformation, and loading processes and help visualize data flows across systems.
For example, did you know you can see your data lineage in PowerBI? Check out the tools you currently use in your data pipelines and see how much of your data lineage is already being tracked!
Sometimes, an off-the-shelf solution is not practical, and a more custom-built solution is preferred. If that is the case for you, here are a few options you can explore to set up a data lineage for your pipeline.
First, try to manually document the data flows and transformations in your system by creating detailed records of data origins, processes, and destinations. This method may be sufficient for smaller datasets or simpler data environments managed by a single person or a small team.
However, if your data landscape is larger or more complex, you may only want to manually document a high-level view of your pipeline for your own use so you can pinpoint where to add automated lineage tracking. Manual documentation allows for a high degree of customization but can be labor-intensive for large systems.
You can develop custom scripts using programming languages like Python to capture and log data transformations and movements. These scripts can be integrated into data processing pipelines to automate parts of the documentation process. This approach is useful for organizations with specific requirements not fully met by existing tools or those with moderate data complexity.
Implementing database triggers to automatically log changes and movements of data within databases is another technique you can implement. These triggers can log any insert, update, or delete operations executed on a database, providing a log of data evolution over time. This technique is ideal for organizations with large, complex data landscapes where real-time tracking of data changes is crucial.
You may be familiar with version control as a way of tracking the lineage of code versions. Similar version control practices can also be used for data. By keeping track of versions of datasets and documenting changes between those versions, you can track data lineage over time. Tools like Git can be adapted for data versioning. This method is particularly beneficial for organizations that need to maintain historical data integrity and track changes over long periods.
You can create custom visualizations to map out data lineage using network visualization libraries like networkx in Python. With these libraries, you can generate diagrams representing data flows and transformations, making it easier to understand and track data lineage. This approach suits organizations that require highly tailored visualizations and have the technical expertise to develop these custom solutions.
If you are tracking a lot of metadata, it makes sense to set up a centralized metadata repository to store all the metadata related to your data assets. This repository can be built using relational databases or NoSQL solutions and should be designed to easily integrate with data processing systems to keep metadata up to date.
This approach is ideal for organizations with extensive and diverse data assets that need a scalable and flexible solution for metadata management. To get started, check out OpenMetadata for some open-source tools.
I write a lot about the importance of documentation in code, and for good reason. Documentation is a critical part of good coding practice. Data lineage is important for many of the same reasons as code documentation. In many respects, you can think of data lineage the same way you think of documentation—it’s a trail of evidence documenting every step your data took.
Unlike code documentation, though, data lineages often rely on metadata and automation for their creation. While documentation is often manual (or done by AI these days), data lineage is often too complex and bulky to be done manually.
Documentation is also often seen in the form of within-code comments, along with a README file. Data lineage is often visualized through diagrams and automated reports in order to understand the flow of data in your system.
Data lineage and data governance are closely related concepts in data management. Data lineage traces data's journey through transformations and systems, providing a historical record that ensures transparency and traceability. Meanwhile, data governance encompasses broader policies and standards for data quality, security, and compliance. Data lineages may support the enforcement of data governance policies.
Organizations can enhance governance efforts by leveraging data lineage tools and techniques, ensuring data integrity and compliance with regulatory requirements. Together, data lineage and governance create a comprehensive approach to managing and securing data.
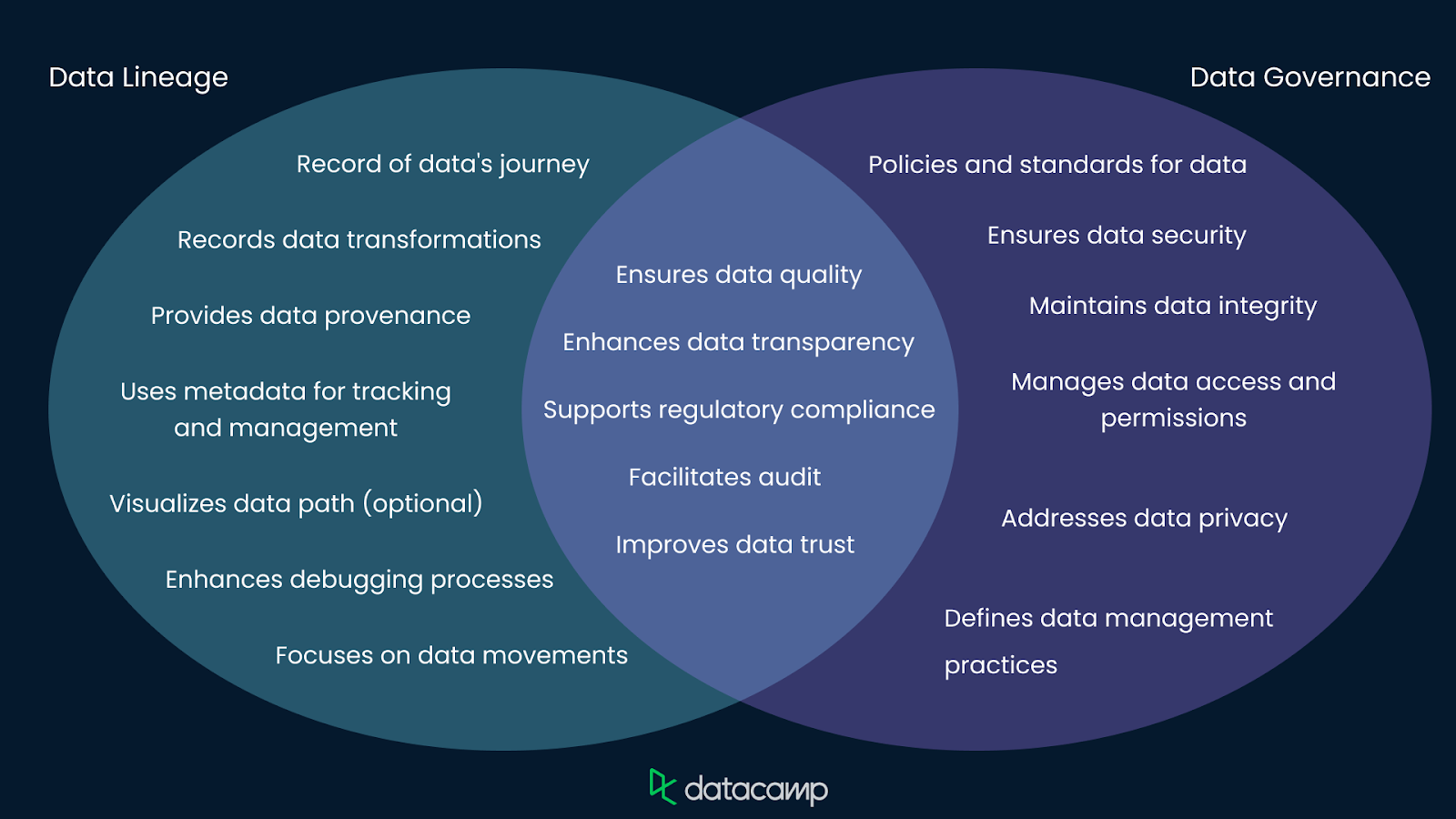
You can learn more about data governance in this course on Data Governance Concepts. You can also take a more advanced look at How Data Leaders Can Make Data Governance a Priority.
As data landscapes grow more complex, data lineages are becoming increasingly vital. They build trust by providing transparency, enabling faster debugging, and demonstrating data provenance.
With advancements in automation and visualization, the importance of data lineage tools will only continue to grow, supporting robust data governance and management practices.
If you’d like to learn more, try this course on Understanding Data Engineering. I also encourage you to check out Responsible AI Data Management and Making Data Governance Fun.
Get your team access to the full DataCamp library, with centralized reporting, assignments, projects and more
Learn data engineering with these courses!
course
track
track
blog
Kenneth Leung
8 min
blog
Amberle McKee
12 min
blog
Matt Crabtree
15 min
blog
Javeria Rahim
7 min
blog
Abid Ali Awan
6 min
tutorial
Amberle McKee
22 min






