Introduction to Unsupervised Learning

Unsupervised learning, a fundamental type of machine learning, continues to evolve. This approach, which focuses on input vectors without corresponding target values, has seen remarkable developments in its ability to group and interpret information based on similarities, patterns, and differences. The latest advancements in deep unsupervised learning models have enhanced this capability, enabling more nuanced understanding of complex datasets.
In 2024, unsupervised learning algorithms, which traditionally do not rely on input-to-output mappings, have become even more autonomous and efficient in discovering the underlying structures of unlabeled data. This independence from 'a teacher' has been strengthened by the advent of sophisticated self-supervised learning techniques, significantly reducing the dependency on labeled data.
Furthermore, the field has made strides in the integration of unsupervised learning with other AI disciplines, such as reinforcement learning, leading to more adaptive and intelligent systems. These systems excel in identifying patterns and anomalies in data, paving the way for innovative applications across various sectors. This article explores unsupervised learning in more detail, exploring the various different types and what they're used for.
Supervised vs Unsupervised Learning
In the table below, we’ve compared some of the key differences between unsupervised and supervised learning:
|
Supervised Learning |
Unsupervised learning |
|
|
Objective |
To approximate a function that maps inputs to outputs based out example input-output pairs. |
To build a concise representation of the data and generate imaginative content from it. |
|
Accuracy |
Highly accurate and reliable. |
Less accurate and reliable. |
|
Complexity |
Simpler method. |
Computationally complex. |
|
Classes |
Number of classes is known. |
Number of classes is unknown. |
|
Output |
A desired output value (also called the supervisory signal). |
No corresponding output values. |
Types of Unsupervised Learning
In the introduction, we mentioned that unsupervised learning is a method we use to group data when no labels are present. Since no labels are present, unsupervised learning methods are typically applied to build a concise representation of the data so we can derive imaginative content from it.
For example, if we were releasing a new product, we can use unsupervised learning methods to identify who the target market for the new product will be: this is because there is no historical information about who the target customer is and their demographics.
But unsupervised learning can be broken down into three main tasks:
- Clustering
- Association rules
- Dimensionality reduction.
Let’s delve deeper into each one:
Clustering
From a theoretical standpoint, instances within the same group tend to have similar properties. You can observe this phenomenon in the periodic table. Members of the same group, separated by eighteen columns, have the same number of electrons in the outermost shells of their atoms and form bonds of the same type.
This is the idea that’s at play in clustering algorithms; Clustering methods involve grouping untagged data based on their similarities and differences. When two instances appear in different groups, we can infer they have dissimilar properties.
Clustering is a popular type of unsupervised learning approach. You can even break it down further into different types of clustering; for example:
- Exlcusive clustering: Data is grouped such that a single data point exclusively belongs to one cluster.
- Overlapping clustering: A soft cluster in which a single data point may belong to multiple clusters with varying degrees of membership.
- Hierarchical clustering: A type of clustering in which groups are created such that similar instances are within the same group and different objects are in other groups.
- Probalistic clustering: Clusters are created using probability distribution.
Association Rule Mining
This type of unsupervised machine learning takes a rule-based approach to discovering interesting relationships between features in a given dataset. It works by using a measure of interest to identify strong rules found within a dataset.
We typically see association rule mining used for market basket analysis: this is a data mining technique retailers use to gain a better understanding of customer purchasing patterns based on the relationships between various products.
The most widely used algorithm for association rule learning is the Apriori algorithm. However, other algorithms are used for this type of unsupervised learning, such as the Eclat and FP-growth algorithms.
Dimensionality Reduction
Popular algorithms used for dimensionality reduction include principal component analysis (PCA) and Singular Value Decomposition (SVD). These algorithms seek to transform data from high-dimensional spaces to low-dimensional spaces without compromising meaningful properties in the original data. These techniques are typically deployed during exploratory data analysis (EDA) or data processing to prepare the data for modeling.
It’s helpful to reduce the dimensionality of a dataset during EDA to help visualize data: this is because visualizing data in more than three dimensions is difficult. From a data processing perspective, reducing the dimensionality of the data simplifies the modeling problem.
When more input features are being fed into the model, the model must learn a more complex approximation function. This phenomenon can be summed up by a saying called the “curse of dimensionality.”
Unsupervised Learning Applications
Most executives would have no problem identifying use cases for supervised machine learning tasks; the same cannot be said for unsupervised learning.
One reason this may be is down to the simple nature of risk. Unsupervised learning introduces much more risk than unsupervised learning since there’s no clear way to measure results against ground truth in an offline manner, and it may be too risky to conduct an online evaluation.
Nonetheless, there are several valuable unsupervised learning use cases at the enterprise level. Beyond using unsupervised techniques to explore data, some common use cases in the real-world include:
- Natural language processing (NLP). Google News is known to leverage unsupervised learning to categorize articles based on the same story from various news outlets. For instance, the results of the football transfer window can all be categorized under football.
- Image and video analysis. Visual Perception tasks such as object recognition leverage unsupervised learning.
- Anomaly detection. Unsupervised learning is used to identify data points, events, and/or observations that deviate from a dataset's normal behavior.
- Customer segmentation. Interesting buyer persona profiles can be created using unsupervised learning. This helps businesses to understand their customers' common traits and purchasing habits, thus, enabling them to align their products more accordingly.
- Recommendation Engines. Past purchase behavior coupled with unsupervised learning can be used to help businesses discover data trends that they could use to develop effective cross-selling strategies.
Unsupervised Learning Example in Python
Principal component analysis (PCA) is the process of computing the principal components then using them to perform a change of basis on the data. In other words, PCA is an unsupervised learning dimensionality reduction technique.
It’s useful to reduce the dimensionality of a dataset for two main reasons:
- When there are too many dimensions in a dataset to visualize
- To identify the most predictive n dimensions for feature selection when building a predictive model.
In this section, we will implement the PCA algorithm in Python on the Iris dataset and then visualize it using matplotlib. Check out this DataLab workbook to follow along with the code used in this tutorial.
Let’s start by importing the necessary libraries and the data.
from sklearn.datasets import load_iris # Dataset
from sklearn.decomposition import PCA # Algorithm
import matplotlib.pyplot as plt # Visualization
# Load the data
iris_data = load_iris(as_frame=True)
# Preview
iris_data.data.head()|
sepal length (cm) |
sepal width (cm) |
petal length (cm) |
petal width (cm) |
|
|
0 |
5.1 |
3.5 |
1.4 |
0.2 |
|
1 |
4.9 |
3 |
1.4 |
0.2 |
|
2 |
4.7 |
3.2 |
1.3 |
0.2 |
|
3 |
4.6 |
3.1 |
1.5 |
0.2 |
|
4 |
5 |
3.6 |
1.4 |
0.2 |
The iris dataset has four features. Attempting to visualize data in four dimensions or more is impossible because we have no clue of how things in such a high dimension would look like. The next best thing we could do is to depict it in three dimensions, which is not impossible but still challenging.
For example:
"""
Credit: Rishikesh Kumar Rishi
Link: https://www.tutorialspoint.com/how-to-make-a-4d-plot-with-matplotlib-using-arbitrary-data
"""
plt.rcParams["figure.figsize"] = [7.00, 3.50]
plt.rcParams["figure.autolayout"] = True
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
sepal_length = iris_data.data["sepal length (cm)"]
sepal_width = iris_data.data["sepal width (cm)"]
petal_length = iris_data.data["petal length (cm)"]
petal_width = iris_data.data["petal width (cm)"]
ax.scatter(sepal_length, sepal_width, petal_length, c=petal_width)
plt.show()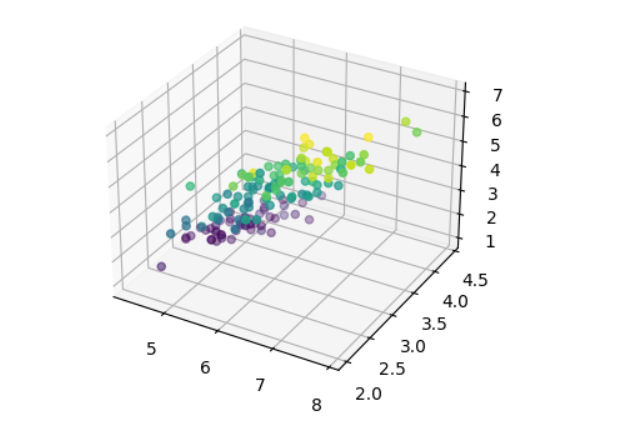
It’s quite difficult to get insights from this visualization because all of the inststances are jumbled together since we only have access to one viewpoint when we visualize data in three dimensions in this scenario.
With PCA, we can reduce the dimensions of the data down to two, which would then make it easier to visualize our data and tell apart the classes.
Note: Learn how to implement PCA in R in “Principal Component Analysis in R Tutorial.”
# Instantiate PCA with 2 components
pca = PCA(n_components=2)
# Train the model
pca.fit(iris_data.data)
iris_data_reduced = pca.fit_transform(iris_data.data)
# Plot data
plt.scatter(
iris_data_reduced[:,0],
iris_data_reduced[:,1],
c=iris_data.target
)
plt.show()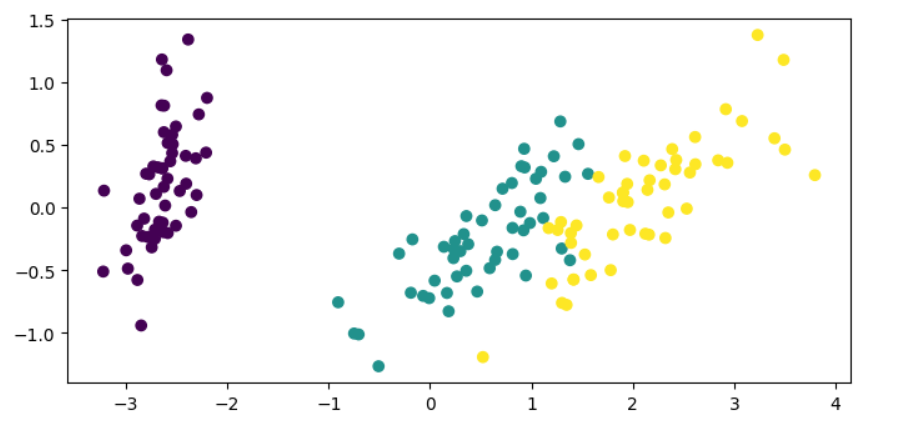
In the code above, we transform the iris dataset features, only keeping two components, and then plot the reduced data in a two-dimensional plane.
Now, it’s much easier for us to gather information about the data and how the classes are separated. We can use this insight to decide on the next steps to take if we were to fit a machine learning model onto our data.
Final thoughts
Unsupervised learning refers to a class of problems in machine learning where a model is used to characterize or extract relationships in data.
In contrast to supervised learning, unsupervised learning algorithms discover the underlying structure of a dataset using only input features. This means unsupervised learning models do not require a teacher to correct them, unlike in supervised learning.
In this article, you learned the three main types of unsupervised learning, which are association rule mining, clustering, and dimensionality reduction. You also learned several applications of unsupervised learning, and how to do dimensionality reduction using the PCA algorithm in Python.
Why not check out these resources to continue your education:
What is unsupervised learning in machine learning?
What are the main tasks of unsupervised learning?
What is clustering in unsupervised learning?
What is association rule mining in unsupervised learning?
What is dimensionality reduction in unsupervised learning?
What are some applications of unsupervised learning?
How can PCA be used for dimensionality reduction in unsupervised learning?
How has unsupervised learning evolved in recent years?
What are the differences between supervised, unsupervised, and semi-supervised learning?
What are generative models in unsupervised learning, and how are they used?
blog
Supervised Machine Learning

Moez Ali
8 min

blog
Clustering in Machine Learning: 5 Essential Clustering Algorithms
Moez Ali
15 min

blog
What is Similarity Learning? Definition, Use Cases & Methods

Abid Ali Awan
9 min

blog
Classification vs Clustering in Machine Learning: A Comprehensive Guide

Kurtis Pykes
12 min
cheat sheet
Unsupervised Machine Learning Cheat Sheet

Richie Cotton
9 min
tutorial
Hierarchical Clustering in R
DataCamp Team
15 min