The Top 5 Vector Databases

The landscape of vector databases (Image Source)
In the realm of Artificial Intelligence (AI), vast amounts of data require efficient handling and processing. As we delve into more advanced applications of AI, such as image recognition, voice search, or recommendation engines, the nature of data becomes more intricate. Here's where vector databases come into play. Unlike traditional databases that store scalar values, vector databases are uniquely designed to handle multi-dimensional data points, often termed vectors. These vectors, representing data in numerous dimensions, can be thought of as arrows pointing in a particular direction and magnitude in space.
As the digital age propels us into an era dominated by AI and machine learning, vector databases have emerged as indispensable tools for storing, searching, and analyzing high-dimensional data vectors. This blog aims to provide a comprehensive understanding of vector databases, their ever-growing importance in AI, and a deep dive into the best vector databases available in 2023.
Develop AI Applications
Learn to build AI applications using the OpenAI API.

What is a Vector Database?
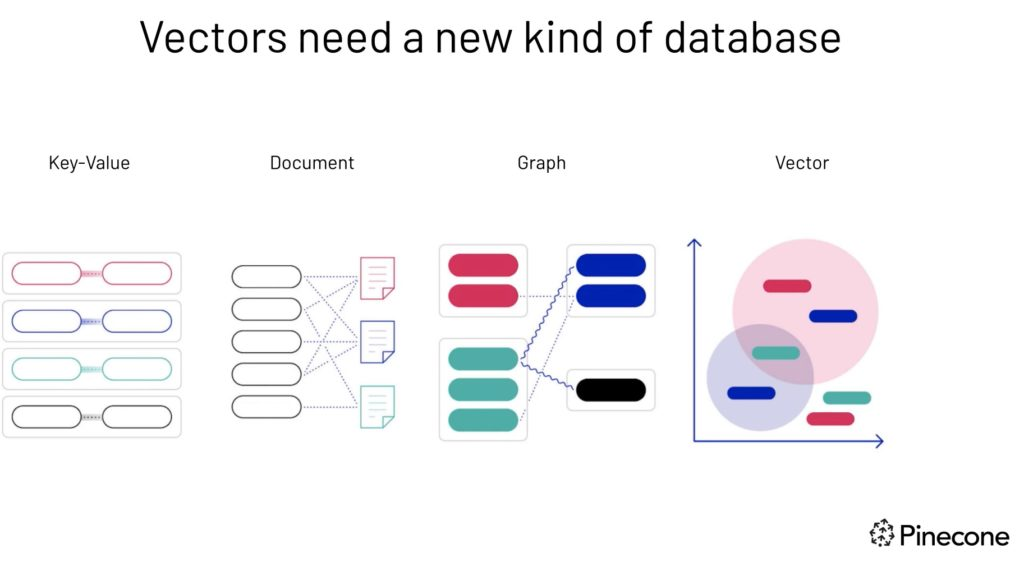
Vectors need a new kind of database (Image Source)
A vector database is a specific kind of database that saves information in the form of multi-dimensional vectors representing certain characteristics or qualities.
The number of dimensions in each vector can vary widely, from just a few to several thousand, based on the data's intricacy and detail. This data, which could include text, images, audio, and video, is transformed into vectors using various processes like machine learning models, word embeddings, or feature extraction techniques.
The primary benefit of a vector database is its ability to swiftly and precisely locate and retrieve data according to their vector proximity or resemblance. This allows for searches rooted in semantic or contextual relevance rather than relying solely on exact matches or set criteria as with conventional databases.
For instance, with a vector database, you can:
- Search for songs that resonate with a particular tune based on melody and rhythm.
- Discover articles that align with another specific article in theme and perspective.
- Identify gadgets that mirror the characteristics and reviews of a certain device.
How Does a Vector Database Work?
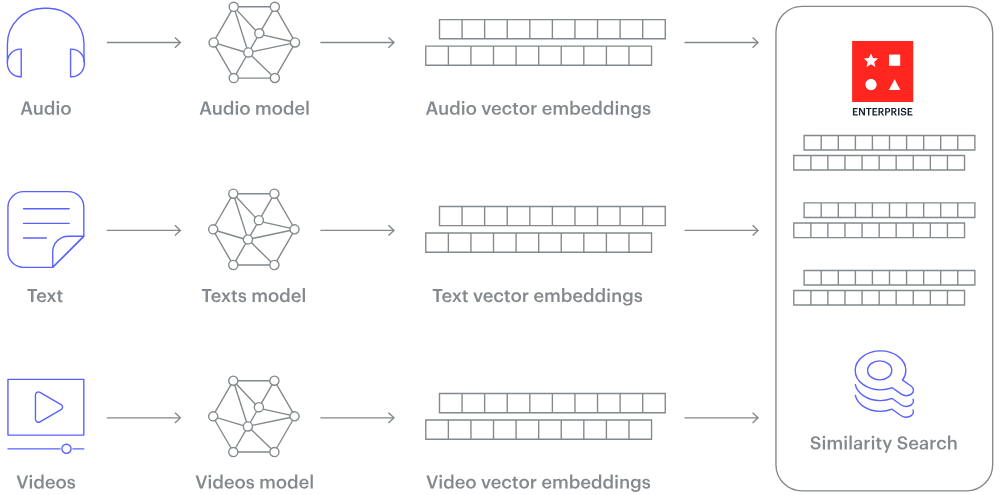
How does a vector database work? (Image Source)
Traditional databases store simple data like words and numbers in a table format. Vector databases, however, work with complex data called vectors and use unique methods for searching.
While regular databases search for exact data matches, vector databases look for the closest match using specific measures of similarity.
Vector databases use special search techniques known as Approximate Nearest Neighbor (ANN) search, which includes methods like hashing and graph-based searches.
To really understand how vector databases work and how it is different from traditional relational databases like SQL, we have to first understand the concept of embeddings.
Unstructured data, such as text, images, and audio, lacks a predefined format, posing challenges for traditional databases. To leverage this data in artificial intelligence and machine learning applications, it's transformed into numerical representations using embeddings.
Embedding is like giving each item, whether it's a word, image, or something else, a unique code that captures its meaning or essence. This code helps computers understand and compare these items in a more efficient and meaningful way. Think of it as turning a complicated book into a short summary that still captures the main points.
This embedding process is typically achieved using a special kind of neural network designed for the task. For example, word embeddings convert words into vectors in such a way that words with similar meanings are closer in the vector space.
This transformation allows algorithms to understand relationships and similarities between items.
Essentially, embeddings serve as a bridge, converting non-numeric data into a form that machine learning models can work with, enabling them to discern patterns and relationships in the data more effectively.
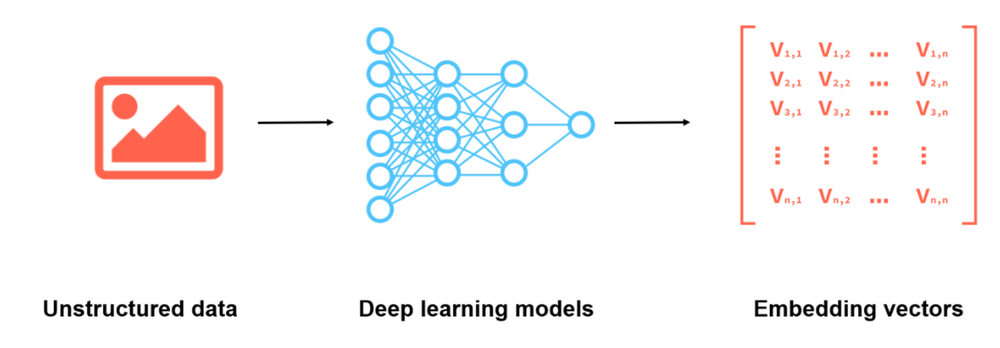
Embeddings uses deep learning model to convert unstructured data into vectors (Image Source)
Examples of Vector Database
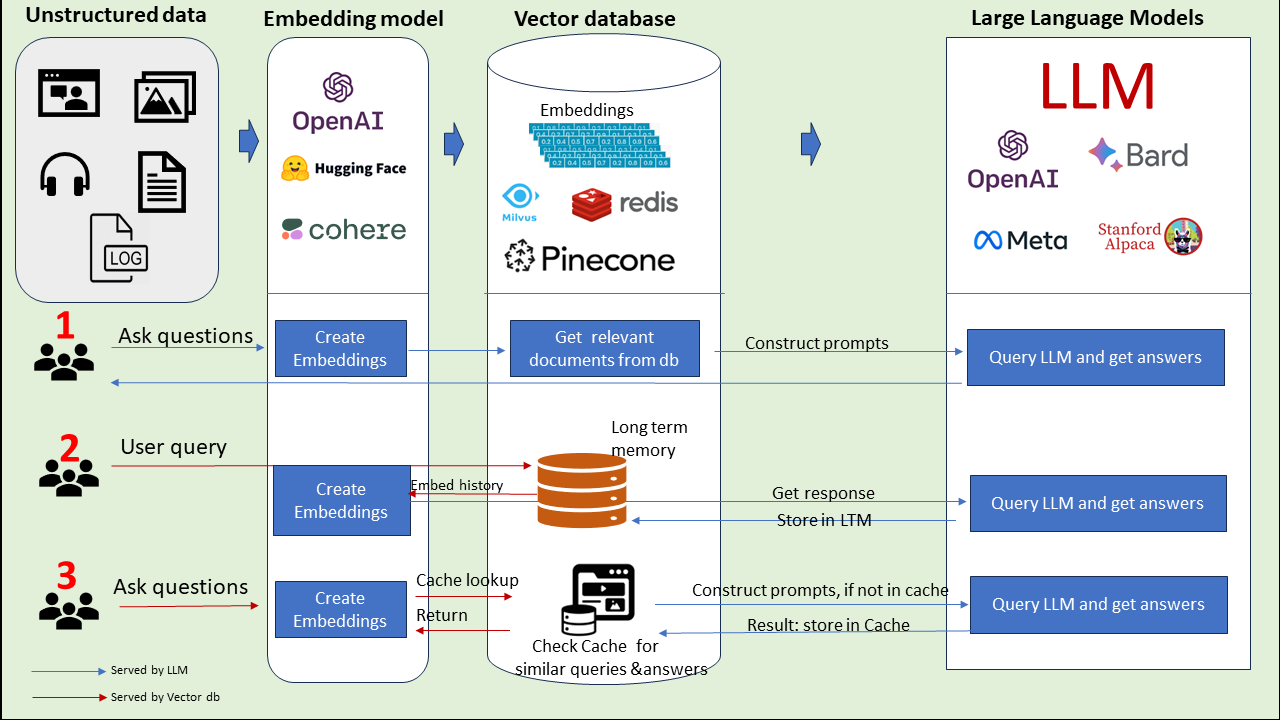
Use-cases of vector database in LLM applications (Image Source)
Vector databases, with their unique capabilities, are carving out niches in a multitude of industries due to their efficiency in implementing "similarity search." Here's a deeper dive into their diverse applications:
1. Enhancing retail experiences
In the bustling retail sector, vector databases are reshaping how consumers shop. They enable the creation of advanced recommendation systems, curating personalized shopping experiences. For instance, an online shopper may receive product suggestions not just based on past purchases, but also by analyzing the similarities in product attributes, user behavior, and preferences.
2. Financial data analysis
The financial sector is awash with intricate patterns and trends. Vector databases excel in analyzing this dense data, helping financial analysts detect patterns crucial for investment strategies. By recognizing subtle similarities or deviations, they can forecast market movements and devise more informed investment blueprints.
3. Healthcare
In the realm of healthcare, personalization is paramount. By analyzing genomic sequences, vector databases enable more tailored medical treatments, ensuring that medical solutions align more closely with individual genetic makeup.
4. Enhancing natural language processing (NLP) applications
The digital world is seeing a surge in chatbots and virtual assistants. These AI-driven entities rely heavily on understanding human language. By converting vast text data into vectors, these systems can more accurately comprehend and respond to human queries. For example, companies like Talkmap utilize real-time natural language understanding, enabling smoother customer-agent interactions.
5. Media analysis
From medical scans to surveillance footage, the capacity to accurately compare and understand images is crucial. Vector databases streamline this by focusing on the essential features of images, filtering out noise and distortions. For instance, in traffic management, images from video feeds can be swiftly analyzed to optimize traffic flow and enhance public safety.
6. Anomaly detection
Spotting outliers is as essential as recognizing similarities. Especially in sectors like finance and security, detecting anomalies can mean preventing fraud or preempting a potential security breach. Vector databases offer enhanced capabilities in this domain, making the detection process faster and more precise.
Features of a Good Vector Database
Vector databases have emerged as powerful tools to navigate the vast terrain of unstructured data, like images, videos, and texts, without relying heavily on human-generated labels or tags. Their capabilities, when integrated with advanced machine learning models, hold the potential to revolutionize numerous sectors, from e-commerce to pharmaceuticals. Here are some of the standout features that make vector databases a game-changer:
1. Scalability and adaptability
A robust vector database ensures that as data grows - reaching millions or even billions of elements - it can effortlessly scale across multiple nodes. The best vector databases offer adaptability, allowing users to tune the system based on variations in insertion rate, query rate, and underlying hardware.
2. Multi-user support and data privacy
Accommodating multiple users is a standard expectation for databases. However, merely creating a new vector database for each user isn't efficient. Vector databases prioritize data isolation, ensuring that any changes made to one data collection remain unseen to the rest unless shared intentionally by the owner. This not only supports multi-tenancy but also ensures the privacy and security of data.
3. Comprehensive API suite
A genuine and effective database offers a full set of APIs and SDKs. This ensures that the system can interact with diverse applications and can be managed effectively. Leading vector databases, like Pinecone, provide SDKs in various programming languages such as Python, Node, Go, and Java, ensuring flexibility in development and management.
4. User-friendly interfaces
Reducing the steep learning curve associated with new technologies, user-friendly interfaces in vector databases play a pivotal role. These interfaces offer a visual overview, easy navigation, and accessibility to features that might otherwise remain obscured.
5 of the Best Vector Databases in 2023
The list is in no particular order - each displays many of the qualities outlined in the section above.
1. Chroma
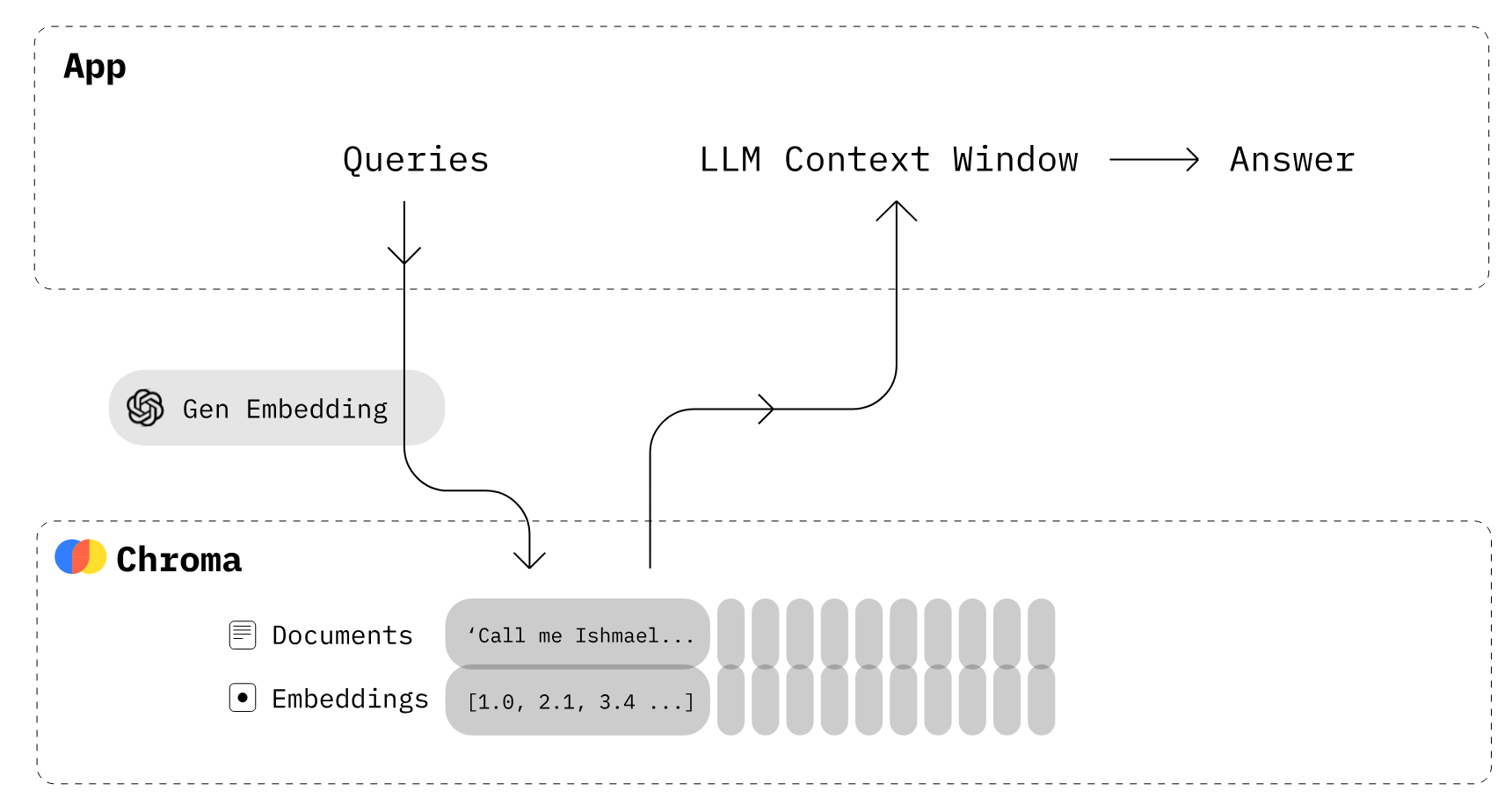
Building LLM Apps using ChromaDB (Image Source)
Chroma is the open-source embedding database. Chroma makes it easy to build LLM apps by making knowledge, facts, and skills pluggable for LLMs. As we explore in our Chroma DB tutorial, you can easily manage text documents, convert text to embeddings, and do similarity searches.
Key Features:
- Feature-rich: queries, filtering, density estimates, and many other features
- LangChain (Python and JavScript), LlamaIndex, support available
- The same API that runs in Python notebook scales to the production cluster
2. Pinecone
|
OPEN-SOURCE: ❎ |
GITHUB STARS: N/A⭐ |

Pinecone vector database (Image Source)
Pinecone is a managed vector database platform that has been purpose-built to tackle the unique challenges associated with high-dimensional data. Equipped with cutting-edge indexing and search capabilities, Pinecone empowers data engineers and data scientists to construct and implement large-scale machine learning applications that effectively process and analyze high-dimensional data. Key features of Pinecone include :
- Fully managed service
- Highly scalable
- Real-time data ingestion
- Low-latency search
- Integration with LangChain
To learn more about Pinecone, check out this Mastering Vector Databases with Pinecone Tutorial by Moez Ali on Data Camp.
3. Weaviate
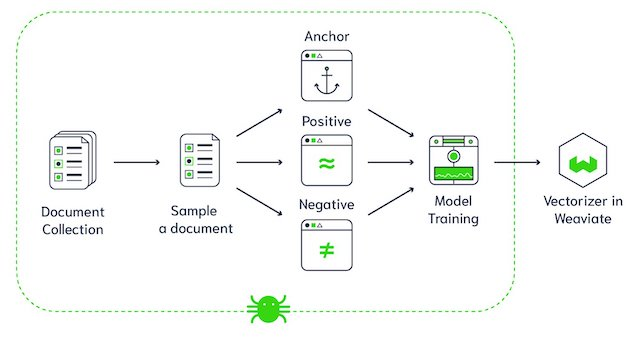
Weaviate vector database architecture (Image Source)
Weaviate is an open-source vector database. It allows you to store data objects and vector embeddings from your favorite ML models and scale seamlessly into billions of data objects. Some of the key features of Weaviate are:
- Speed. Weaviate can quickly search ten nearest neighbors from millions of objects in just a few milliseconds.
- Flexibility. With Weaviate, either vectorize data during import or upload your own, leveraging modules that integrate with platforms like OpenAI, Cohere, HuggingFace, and more.
- Production-ready. From prototypes to large-scale production, Weaviate emphasizes scalability, replication, and security.
- Beyond search: Apart from fast vector searches, Weaviate offers recommendations, summarizations, and neural search framework integrations.
If you are interested in learning more about Weaviate, check out our Vector Databases for Data Science with Weaviate in Python webinar on DataCamp.
4. Faiss
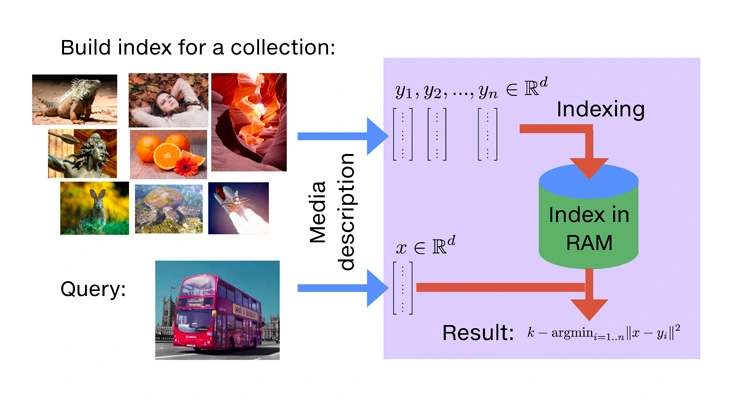
Faiss is an open-source library for vector search created by Facebook (Image Source)
Faiss is an open-source library for the swift search of similarities and the clustering of dense vectors. It houses algorithms capable of searching within vector sets of varying sizes, even those that might exceed RAM capacity. Additionally, Faiss offers auxiliary code for assessment and adjusting parameters.
While it's primarily coded in C++, it fully supports Python/NumPy integration. Some of its key algorithms are also available for GPU execution. The primary development of Faiss is undertaken by the Fundamental AI Research group at Meta.
5. Qdrant
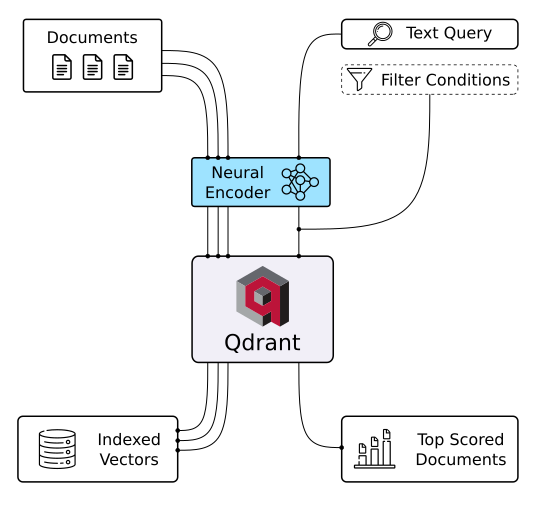
Qdrant vector database (Image Source)
Qdrant is a vector database and a tool for conducting vector similarity searches. It operates as an API service, enabling searches for the closest high-dimensional vectors. Using Qdrant, you can transform embeddings or neural network encoders into comprehensive applications for tasks like matching, searching, making recommendations, and much more. Here are some key features of Qdrant:
- Versatile API. Offers OpenAPI v3 specs and ready-made clients for various languages.
- Speed and precision. Uses a custom HNSW algorithm for rapid and accurate searches.
- Advanced filtering. Allows results filtering based on associated vector payloads.
- Diverse data types. Supports string matching, numerical ranges, geo-locations, and more.
- Scalability. Cloud-native design with horizontal scaling capabilities.
- Efficiency. Built-in Rust, optimizing resource use with dynamic query planning.
The rise of AI and the Impact of Vector Database
Vector databases specialize in storing high-dimensional vectors, enabling fast and accurate similarity searches. As AI models, especially those in the domain of natural language processing and computer vision, generate and work with these vectors, the need for efficient storage and retrieval systems has become paramount. This is where vector databases come into play, providing a highly optimized environment for these AI-driven applications.
A prime example of this relationship between AI and vector databases is observed in the emergence of Large Language Models (LLMs) like GPT-3.
These models are designed to understand and generate human-like text by processing vast amounts of data, transforming them into high-dimensional vectors. A
pplications built on GPT-3 and similar models rely heavily on vector databases to manage and query these vectors efficiently. The reason for this reliance lies in the sheer volume and complexity of data these models handle. For instance, GPT-3, with its 175 billion parameters, results in a tremendous amount of vectorized data, which conventional databases struggle to process effectively.
Conclusion
The ever-evolving landscape of artificial intelligence and machine learning underscores the indispensability of vector databases in today's data-centric world. These databases, with their unique ability to store, search, and analyze multi-dimensional data vectors, are proving instrumental in powering AI-driven applications, from recommendation systems to genomic analysis.
We’ve recently seen an impressive array of vector databases, such as Chroma, Pinecone, Weaviate, Faiss, and Qdrant, each offering distinct capabilities and innovations. As AI continues its ascent, the role of vector databases in shaping the future of data retrieval, processing, and analysis will undoubtedly grow, promising more sophisticated, efficient, and personalized solutions across various sectors.
Learn to master vector databases with our Pinecone tutorial, or sign up for our Deep Learning in Python skill track to improve your AI skills and keep up-to-date with the latest developments.



blog
Types of Databases: Relational, NoSQL, Cloud, Vector
Moez Ali
15 min

podcast
The Power of Vector Databases and Semantic Search with Elan Dekel, VP of Product at Pinecone

Richie Cotton
36 min
tutorial
An Introduction to Vector Databases For Machine Learning: A Hands-On Guide With Examples

Gary Alway
8 min
tutorial
Mastering Vector Databases with Pinecone Tutorial: A Comprehensive Guide
Moez Ali
11 min
tutorial
Weaviate Tutorial: Unlocking the Power of Vector Search
Moez Ali
11 min
code-along
Vector Databases for Data Science with Weaviate in Python

JP Hwang