

track
AI Business Fundamentals
11hrs hours
Train your finance team with DataCamp for Business. Comprehensive data and AI training resources and detailed performance insights to support your goals.
From calculating capital reserves to evaluating marketing strategies, statistical analysis informs nearly every decision at a bank. Many people, including data scientists, analysts, managers, business leads, and regulators, will often need to look at the analysis or reports based on it.
Machine learning and statistical models' predictions can be an important part of this analysis. However, using them in this way would not be considered AI.
AI is when a model is used to automate a decision. Its predictions are fed into a system. The system contains rules based on the prediction and other variables that lead to a decision. We call these “AI systems.”
The team I worked on was primarily involved in developing these to automatically sanction new loans. The most important model driving these systems is called a credit risk model.
When you request a loan from a bank, you’ll undergo a credit risk assessment. This can involve calculating the expected loss in the case of a default or the probability that you'll default—that is, the probability you won't be able to repay the loan due to financial hardship. It’s this latter prediction that usually drives the decision to sanction (give you) a loan.
Since before the invention of computers, banks have been doing credit risk assessments. This was primarily done using a “credit scorecard.”
As seen below, it’ll consider various features of a potential borrower. You’ll get a score based on what group you fall into for a given feature, and they are all summed up to get a final score. The higher your score, the less likely you are to default.
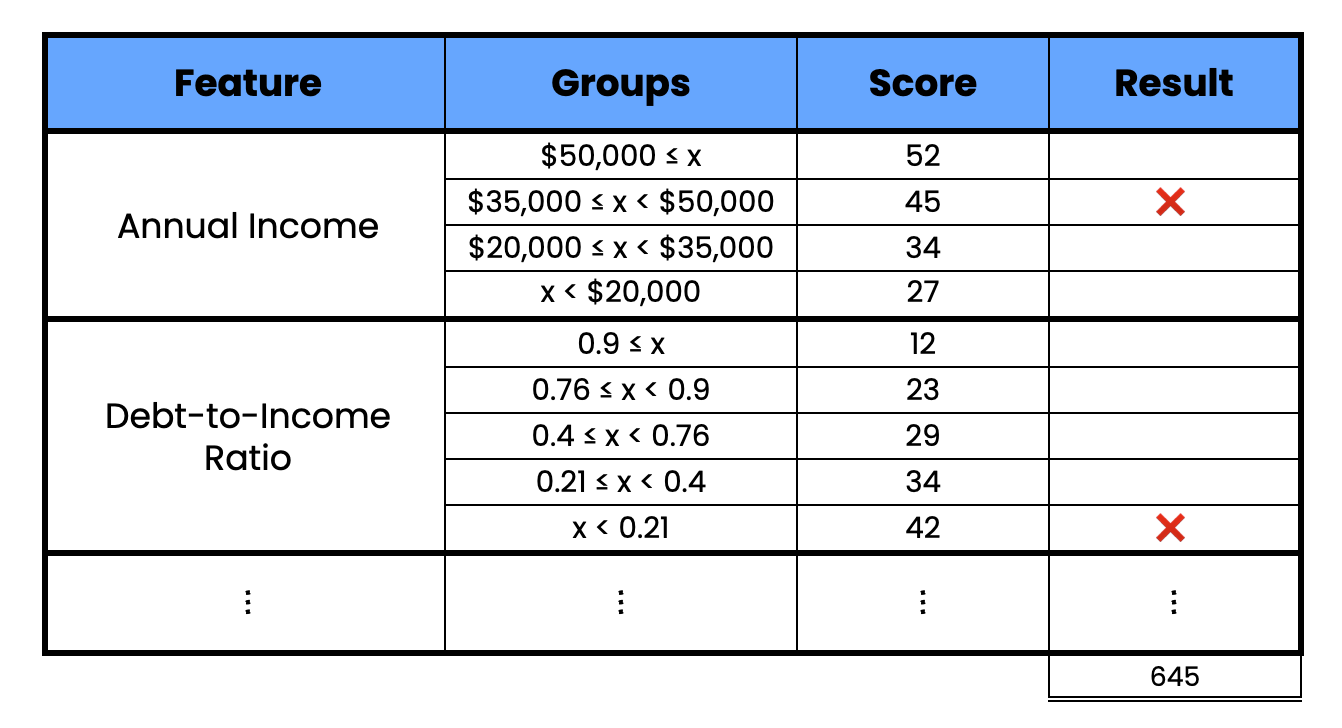
Example of a credit scorecard (source: author)
In the past, these were primarily created through “expert judgment.” This is another way of saying some person in a suit decided on the values. And, yes, this was as biased as it sounds. Now, banks have access to vast amounts of data and computational power to create statistically optimal scorecards. As we discuss later, this can also produce fairer results.
In terms of data, there is a lot to work with. Internally, a bank has access to all of your transaction history and past debt behavior. Externally, most countries will have public records on past debts and defaults across all credit institutions.
All of these sources can be used to make model features. Some banks may even go as far as using device data like your geolocation. Although, at that point, they may start running into some regulatory and ethical considerations.
The process of building these scorecards has changed a lot, but the final product looks the same. Model features are discretized. This is done using the Weight of Evidence (WOE) to maximize the difference in default rates with each feature group. We can then assign a score based on how much a group changes the probability of default. So, just as before, the final score can be used to assess how likely the borrower is to default on a loan.
These credit scorecards form the basis of an AI system used to automatically sanction loans. In its simplest form, it’s a strict cutoff. If the score is below this cutoff, then the loan is denied.
Additional rules can also be based on the bank’s strategy, regulation, or other features like the customer's age. As we discuss in the next section, more complex systems can use predictions from multiple models.
In practice, these AI systems are used to sanction personal or small business loans. Larger amounts like mortgages or corporate loans are not fully automated. These cases can be too unique or the amount of money too large to sanction without a human making the final decision. Often the decision will still be made with the help of a scorecard.
With all the advancements in data collection and automation, you may expect the underlying models to be complex. You’d be wrong.
Logistic regression is used to calculate probabilities of default and create scorecards. We discuss a few reasons for this in the challenges section. They have to do with the interpretability of the model, regulation, and fairness. However, the main reason is that logistic regression is accurate enough.
The default we’ve spoken about occurs when someone comes into financial trouble due to poor decisions or events outside of their control. The important point is that these people do not want to default. This means underlying relationships that drive credit risk move slowly. This gives us time to craft linear features that capture these relationships in an interpretable way. However, there are other types of defaults which are not as simple.
In medicine, machine learning predicts complex things, such as whether a tumor is benign or malignant. Now, imagine if the tumor was conscious and could change its appearance to avoid detection. This suddenly becomes a much harder problem to solve. Similarly, this is why fraud detection is so hard.
There are many types of fraud. In the context of automated loan sanctioning, fraud occurs when the borrower never intended to make repayments. Their goal is to get the loan and disappear with the money. The borrower could have overstated their monthly income, hidden the fact that they have other debt to repay, or even stolen someone’s identity to make the application. Whatever way they manage to do it, we would consider this default due to fraud.
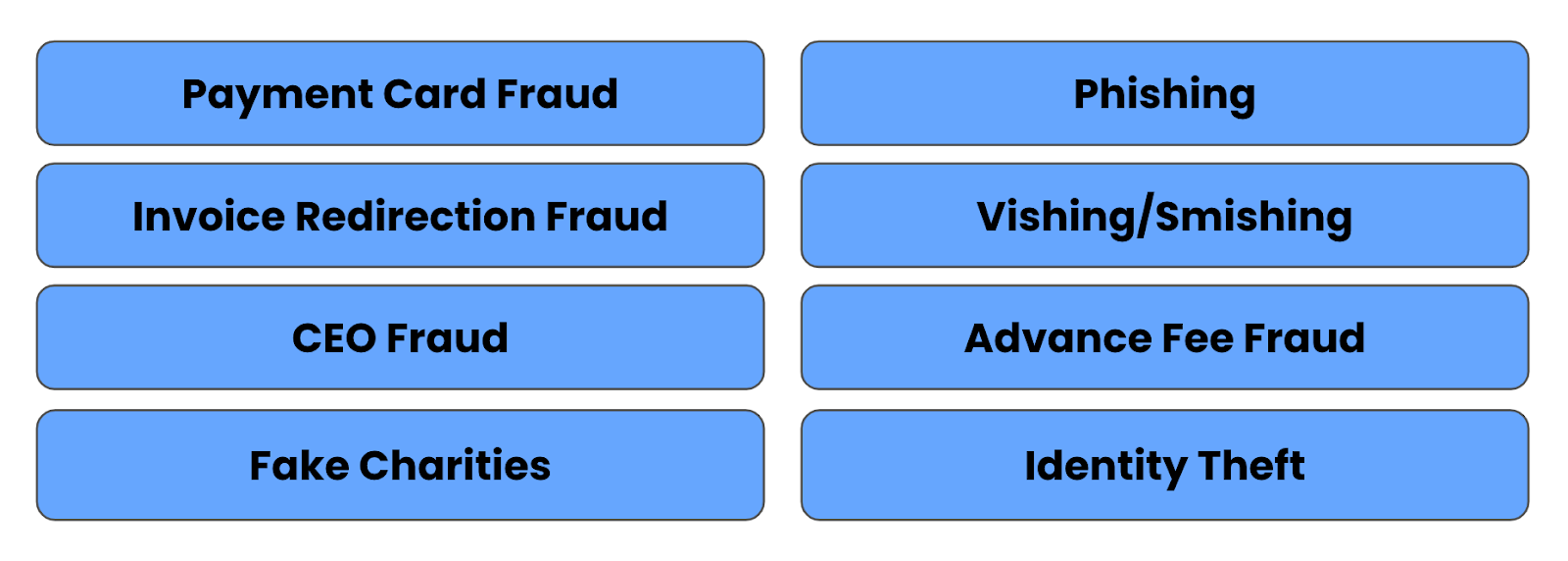
Types of fraud (source: author)
The nature of credit risk default means we can aggregate transactions to get a general sense of the person's behavior. For fraud, individual transactions may be important. We also look at a more diverse set of data sources like device data and communication history.
Another consideration is the shifting nature of fraud means we need to get the models out faster. This all means linear models are often not up to the challenge.
This is why it’s common to use non-linear models like Random Forests and XGBoost. Neural networks can also help if we want to incorporate text data. With these models, less emphasis is put on feature engineering, saving valuable time and allowing us to model behaviors that aren’t completely understood.
The downside is that these are all still predictive models. We want to catch new cases of fraud before they happen. With predictive models, we need a training dataset of labeled fraud cases. In other words, we first need to wait for fraud to happen!
This is why we can also assess potential fraud cases using unsupervised methods like clustering algorithms or single-class models like Isolation Forest. These can help identify customers with unique behaviors or, in more general terms, outliers.
With fraud, we also have to worry about attackers targeting the models themselves. This is why fraud models overlap with an important branch of artificial intelligence: adversarial machine learning.
This field aims to find hidden weaknesses in models that can be exploited by attackers. Someone could trick the model into making incorrect predictions or giving away sensitive information. Poisoning attacks involve injecting fake data into the training process to corrupt models without us knowing.
In terms of loan automation, the former is the most prominent. Essentially, a fraudster will try to make themselves look like a good customer. They will aim to find ways to decrease their perceived credit risk. This could be by artificially increasing their income or lying on their application. Fraud models are used to cover these potential weaknesses in credit risk models. Yet, they themselves must also be assessed for potential adversarial attacks.
Ultimately, the many types and nature of fraud mean we often have to rely on more complex models. In some cases, these models can flag potential cases of fraud, which can then be more thoroughly reviewed by a human.
Regarding AI, fraud models will often run alongside credit risk models in systems used to sanction loans automatically. They complement each other as they aim to predict default for different reasons.
Both fraud detection and credit risk assessment are about acquiring new customers. The right customers. Once they have them, banks face another problem. How do they keep them? The next two sections will explore some of the ways AI can help.
Banks use similar AI-powered strategies to predict if a customer will leave. This could mean closing their bank account or changing mortgage providers. They could also reduce their business without leaving by removing an overdraft, cancelling a credit card, or transferring a large amount of funds to a different bank.
Banks want to step in before these events happen. They will try to persuade dissatisfied customers to use lower interest rates, discounts, or other special benefits. Much of this can be a fully automated process.
Banks use models to predict if a person or business will likely miss future payments (i.e., go into arrears) or default completely. Again, the bank will want to step in before this happens. They may offer financial advice or the opportunity to restructure their debt. Even a simple automated message reminding them of future payments can be effective.
Another area where automation can help is when customers actively seek support from the bank. They may need advice on setting up a savings account or making online payments. Many of these queries will be repetitive, and an AI-powered chatbot can handle them. It can provide answers faster and leave the more complex tasks to humans.
This is also an area where the most advanced AI can be applied. Many companies are updating their chatbots to use LLMs and generative AI. These powerful models have supercharged a bank's chatbot, allowing it to handle more complex queries and even provide personal advice. However, we should be wary of the latter. This has to do with the highly regulated environment in which banks operate.
The real challenges faced by AI in banking are often not technical. Problems around data management and model development have largely been solved. The issues facing the adoption of advanced AI methods come from the environment in which banks operate, established procedures, and a low tolerance to risk.
Since the 2008 financial crisis, well, let's say banks are not given as much leeway to make their own decisions. They face a much stricter regulatory environment which determines the amount they need to keep in capital reserves, the level of risk they can take on and even the types of technology they can implement. The latter means that only certain types of models can be applied to some tasks. For example, capital reserves may have to be calculated with a linear model and predefined features.
There is often a need to clarify and justify the process for making lending decisions. This means explaining how models make predictions to a regulator. Although this does not necessarily restrict the type of models we can use, it does provide some resistance. As mentioned, this is one of the reasons why linear models are used for credit risk modeling. Any improvement in performance from using non-linear models is outweighed by the increased burden of explaining them.
Consider Cynthia Rudin's insights on this topic:
Rather than trying to create models that are inherently interpretable, there has been a recent explosion of work on “Explainable ML,” where a second (posthoc) model is created to explain the first black box model. This is problematic. Explanations are often not reliable and can be misleading, as we discuss below. If we instead use models that are inherently interpretable, they provide their own explanations, which are faithful to what the model actually computes.
Cynthia Rudin, Duke University, Durham, NC, USA
Transform your business by empowering your team with advanced AI skills through DataCamp for Business. Achieve better insights and efficiency.
Learn more about AI!
track
course
course
blog
DataCamp Team
5 min
blog
Nahla Davies
16 min
blog
DataCamp Team
5 min
blog
Shawn Plummer
8 min
blog
Elena Kosourova
11 min
blog
Kurtis Pykes
9 min





