course
Introduction to Deep Learning with PyTorch
4 hours
20K
Language is crucial to human communication, and automating it can bring immense benefits. Natural language processing (NLP) models struggled for years to effectively capture the nuances of human language until a breakthrough happened — the attention mechanism.
The attention mechanism was introduced in 2017 in the paper Attention Is All You Need. Unlike traditional methods that treat words in isolation, attention assigns weights to each word based on its relevance to the current task. This enables the model to capture long-range dependencies, analyze both local and global contexts simultaneously, and resolve ambiguities by attending to informative parts of the sentence.
Consider the following sentence: "Miami, coined the 'magic city,' has beautiful white-sand beaches." Traditional models would process each word in order. The attention mechanism, however, acts more like our brain. It assigns a score to each word based on its relevance to understanding the current focus. Words like "Miami" and "beaches" become more important when considering location, so they'd receive higher scores.
In this article, we’ll provide an intuitive explanation of the attention mechanism. You can also find a more technical approach in this tutorial on how transformers work. Let’s dive right in!
Let’s start our journey in understanding the attention mechanism by considering the larger context of language models.
Language models process language by trying to understand grammatical structure (syntax) and meaning (semantics). The goal is to output language with the correct syntax and semantics that are relevant to the input.
Language models rely on a series of techniques to break down and understand text:
While traditional language models paved the way for advances in NLP, they faced challenges in fully grasping the complexities of natural language:
Unlike traditional models that treat words in isolation, attention allows language models to consider context. Let’s see what this is about!
The game-changer for the NLP field came in 2017 when the paper Attention Is All You Need introduced the attention mechanism.
This paper proposed a new architecture called a transformer. Unlike older methods like recurrent neural networks (RNNs) and convolutional neural networks (CNNs), transformers use attention mechanisms.
By solving many of the problems of traditional models, transformers (and attention) have become the foundation for many of today's most popular large language models (LLMs), like OpenAI's GPT-4 and ChatGPT.
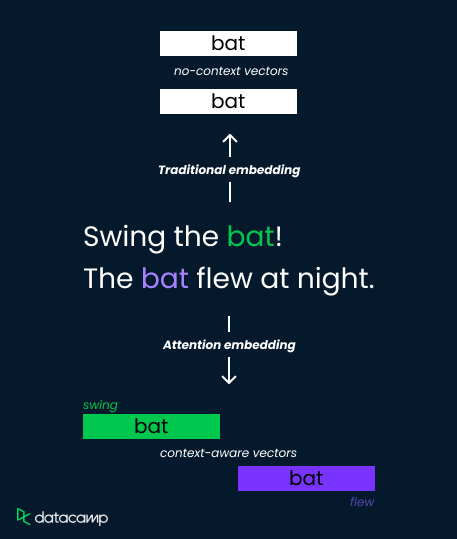
Let’s consider the word “bat” in these two sentences:
Traditional embedding methods assign a single vector representation to “bat,” limiting their ability to distinguish meaning. Attention mechanisms, however, address this by computing context-dependent weights.
They analyze surrounding words ("swing" versus "flew") and calculate attention scores that determine relevance. These scores are then used to weight the embedding vectors, resulting in distinct representations for "bat" as a sports tool (high weight on "swing") or a flying creature (high weight on "flew").
This allows the model to capture semantic nuances and improve comprehension.
Let’s now build on our intuitive understanding of attention and learn how the mechanism goes beyond traditional word embeddings to enhance language comprehension. We’ll also look at a few real-world applications of attention.
Traditional word embedding techniques, such as Word2Vec and GloVe, represent words as fixed-dimensional vectors in a semantic space based on co-occurrence statistics in a large corpus of text.
While these embeddings capture some semantic relationships between words, they lack context sensitivity. This means the same word will have the same embedding regardless of its context within a sentence or document.
This limitation poses challenges in tasks requiring a nuanced understanding of language — especially when words carry different contextual meanings. The attention mechanism solves this problem by enabling models to selectively focus on relevant parts of input sequences, thereby incorporating context sensitivity into the representation learning process.
Attention enables models to understand nuances and ambiguities in language, making them more effective in processing complex texts. Some of its key benefits are:
The impact of attention-based language models has been tremendous. Thousands of people use applications built on top of attention-based models. Some of the most popular applications are:
Now that we’ve become more acquainted with how attention works, let’s look at self-attention and multi-head attention.
Self-attention enables a model to attend to different positions of its input sequence to compute a representation of that sequence. It allows the model to weigh the importance of each word in the sequence relative to others, capturing dependencies between different words in the input. The mechanism has three main elements:
Attention scores can be calculated by doing a scaled dot product between the query and the key vectors. Ultimately, these scores are multiplied with the value vectors to output a weighted sum of values.
Multi-head attention is an extension of the self-attention mechanism. It enhances the model's ability to capture diverse contextual information by simultaneously attending to different parts of the input sequence. It achieves this by performing multiple parallel self-attention operations, each with its own set of learned query, key, and value transformations.
Multi-head attention leads to finer contextual understanding, increased robustness, and expressivity.
Although implementing the attention mechanism has several benefits, it also comes with its own set of challenges, which ongoing research can potentially address.
Attention mechanisms involve computing pairwise similarities between all tokens in the input sequence, resulting in quadratic complexity with respect to sequence length. This can be computationally expensive, especially for long sequences.
Various techniques have been proposed to mitigate computational complexity, such as sparse attention mechanisms, approximate attention methods, and efficient attention mechanisms like the Reformer model's locality-sensitive hashing.
Attention mechanisms may overfit noisy or irrelevant information in the input sequence, leading to suboptimal performance on unseen data.
Regularization techniques, such as dropout and layer normalization, can help prevent overfitting in attention-based models. Additionally, techniques like attention dropout and attention masking have been proposed to encourage the model to focus on relevant information.
Understanding how attention mechanisms operate and interpret their output can be challenging, particularly in complex models with multiple layers and attention heads. This raises concerns about the ethics of this new technology — you can learn more about AI ethics in our course, or by listening to this podcast with AI researcher Dr. Joy Buolamwini.
Methods for visualizing attention weights and interpreting their meaning have been developed to enhance the interpretability of attention-based models. Additionally, techniques like attention attribution aim to identify the contributions of individual tokens to the model's predictions, improving explainability.
Attention mechanisms consume significant memory and computational resources, making them challenging to scale to larger models and datasets.
Techniques for scaling attention-based models, such as hierarchical attention, memory-efficient attention, and sparse attention, aim to reduce memory consumption and computational overhead while maintaining model performance.
Let’s summarize what we’ve learned so far by focusing on the differences between traditional and attention-based models:
|
Feature |
Attention-Based Models |
Traditional NLP Models |
|
Word Representation |
Context-aware embedding vectors (dynamically weighted based on attention scores) |
Static embedding vectors (single vector per word, no context considered) |
|
Focus |
Considers surrounding words for meaning (looking at the broader context) |
Treats each word independently |
|
Strengths |
Captures long-range dependencies, resolves ambiguity, understands nuances |
Simpler, computationally cheaper |
|
Weaknesses |
Can be computationally expensive |
Limited ability to understand complex language, struggles with context |
|
Underlying Mechanism |
Encoder-decoder networks with attention (various architectures) |
Techniques like parsing, stemming, named entity recognition, word embeddings |
In this article, we explored the attention mechanism, an innovation that revolutionized NLP. Unlike prior methods, attention enables language models to focus on crucial parts of a sentence, considering context. This allows them to grasp complex language, long-range connections, and word ambiguity.
You can continue learning about the attention mechanism by:
Get started with Deep Learning!
course
course
course
blog
Javier Canales Luna
12 min
blog
Nisha Arya Ahmed
12 min
tutorial
DataCamp Team
13 min
tutorial
Josep Ferrer
12 min
tutorial
Zoumana Keita
8 min
code-along
Josh Reini






