How to Train a LLM with PyTorch
Large Language Models (LLMs) are major components of modern artificial intelligence applications, especially for natural language processing. They have the potential to efficiently process and understand human language, with applications ranging from virtual assistants and machine translation to text summarization and question-answering.
Libraries like LangChain facilitate the implementation of end-to-end AI applications such as those mentioned above. Our tutorial Introduction to LangChain for Data Engineering & Data Applications provides an overview of what you can do with Langchain, including the problems that LangChain solves, along with examples of data use cases.
This article will explain all the process of training a large language model, from setting up the workspace to the final implementation using Pytorch 2.0.1, a dynamic and flexible deep learning framework that allows an easy and clear model implementation.
Prerequisites
To get the most out of this content, it is important to be comfortable with Python programming, have a basic understanding of deep learning concepts and transformers, and be familiar with the Pytorch framework. The complete source code will be available on GitHub.
Before diving into the core implementation, we need to install and import the relevant libraries. Also, it is important to note that the training script is inspired by this repository from Hugging Face.
Library installation
The installation process is detailed below:
First of all, we use the %%bash statement to run the install commands in a single cell as a bash command in the Jupyter Notebook.
- Trl: used to train transformer language models with reinforcement learning.
- Peft uses the parameter-efficient fine-tuning (PEFT) methods to enable efficient adaptation of the pre-trained model.
- Torch: a widely-used open-source machine learning library.
- Datasets: used to assist in downloading and loading many common machine learning datasets.
Transformers: a library developed by Hugging Face and comes with thousands of pre-trained models for a variety of text-based tasks such as classification, summarization, and translation.
%%bash
pip -q install trl
pip -q install peft
pip -q install torch
pip -q install datasets
pip -q install transformers
Now, those modules can be imported as follows:
import torch
from trl import SFTTrainer
from datasets import load_dataset
from peft import LoraConfig, get_peft_model, prepare_model_for_int8_training
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArgumentsData Loading and Preparation
The alpaca dataset, freely available on Hugging Face, will be used for this illustration. The dataset has three main columns: instructions, input, and output. These columns are combined to generate a final text column.
The instruction to load the dataset is given below by providing the name of the dataset of interest, which is tatsu-lab/alpaca:
train_dataset = load_dataset("tatsu-lab/alpaca", split="train")
print(train_dataset)We can see that the resulting data is in a dictionary of two keys:
- Features: containing the main columns of the data
- Num_rows: corresponding to the total number of rows in the data

Structure of the train_dataset
The first five rows can be displayed with the following instruction. First, convert the dictionary into a pandas dataframe, then display the rows.
pandas_format = train_dataset.to_pandas()
display(pandas_format.head())
First five rows of the train_dataset
For better visualization, let’s print the information about the first three rows, but before that, we need to install the textwrap library to set the maximum number of words per line to 50. The first print statement separates each block by 15 dashes.
import textwrap
for index in range(3):
print("---"*15)
print("Instruction:
{}".format(textwrap.fill(pandas_format.iloc[index]["instruction"],
width=50)))
print("Output:
{}".format(textwrap.fill(pandas_format.iloc[index]["output"],
width=50)))
print("Text:
{}".format(textwrap.fill(pandas_format.iloc[index]["text"],
width=50)))
Details of the first three rows
Model Training
Before proceeding to train the model, we need to set up some prerequisites:
- Pre-trained Model: We will use the pre-trained model Salesforce/xgen-7b-8k-base, which is available on Hugging Face. Salesforce trained this series of 7B LLMs named XGen-7B with standard dense attention on up to 8K sequences for up to 1.5T tokens.
- Tokenizer: This is needed for tokenization tasks on the training data. The code to load the pre-trained model and tokenizer is as follows:
pretrained_model_name = "Salesforce/xgen-7b-8k-base"
model = AutoModelForCausalLM.from_pretrained(pretrained_model_name, torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name, trust_remote_code=True)Training configuration
The training requires some training arguments and configurations, and the two important configuration objects are defined below, an instance of the TrainingArguments, an instance of the LoraConfig model, and finally the SFTTrainer model.
TrainingArguments
This is used to define the parameters for model training.
In this specific scenario, we start by defining the destination where the trained model will be stored using the output_dir attribute before defining additional hyperparameters, such as the optimization method, the learning rate, the number of epochs, and more.
model_training_args = TrainingArguments(
output_dir="xgen-7b-8k-base-fine-tuned",
per_device_train_batch_size=4,
optim="adamw_torch",
logging_steps=80,
learning_rate=2e-4,
warmup_ratio=0.1,
lr_scheduler_type="linear",
num_train_epochs=1,
save_strategy="epoch"
)LoRAConfig
The main arguments used for this scenario are the rank of the low-rank transformation matrix in LoRA, which is set to 16. Then, the scaling factor for the additional parameters in LoRA is set to 32.
Furthermore, the dropout ratio is 0.05, meaning that 5% of the input units will be ignored during the training. Finally, since we are dealing with a causual language modeling, the task is hence initialized with the CAUSAL_LM attribute.
SFTTrainer
This aims to train the model using the training data, the tokenizer, and additional information such as the above models.
Since we are using the text field from the training data, it is important to have a look at the distribution in order to help in setting the maximum number of tokens in a given sequence.
import matplotlib.pyplot as plt
pandas_format['text_length'] = pandas_format['text'].apply(len)
plt.figure(figsize=(10,6))
plt.hist(pandas_format['text_length'], bins=50, alpha=0.5, color='g')
plt.title('Distribution of Length of Text')
plt.xlabel('Length of Text')
plt.ylabel('Frequency')
plt.grid(True)
plt.show()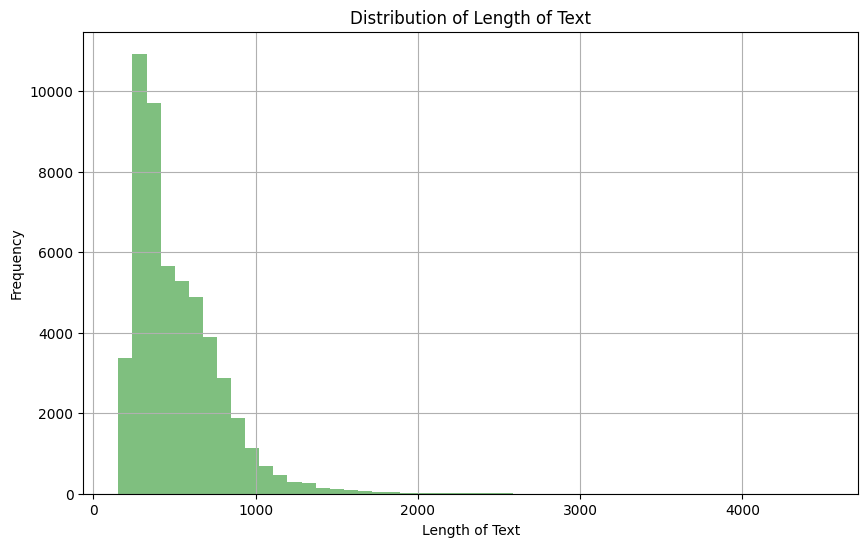
Distribution of the length of the text column
Based on the above observation, we can see that the majority of text has a length between 0 and 1000. Also, we can see below that only 4.5% percent of the text documents have a length greater than 1024.
mask = pandas_format['text_length'] > 1024
percentage = (mask.sum() / pandas_format['text_length'].count()) * 100
print(f"The percentage of text documents with a length greater than 1024 is: {percentage}%")

Then we set the maximum number of tokens in the sequence to 1024 so that any text longer than this get truncated.
SFT_trainer = SFTTrainer(
model=model,
train_dataset=train_dataset,
dataset_text_field="text",
max_seq_length=1024,
tokenizer=tokenizer,
args=model_training_args,
packing=True,
peft_config=lora_peft_config,
)Training execution
With all the prerequisites in place, we can now run the training process of the model as follows:
tokenizer.pad_token = tokenizer.eos_token
model.resize_token_embeddings(len(tokenizer))
model = prepare_model_for_int8_training(model)
model = get_peft_model(model, lora_peft_config)
training_args = model_training_args
trainer = SFT_trainer
trainer.train()It is important to mention that this training is being performed on a cloud environment with a GPU, which makes the overall training process faster. However, training on a local computer would require more time to complete.
Our blog, Pros and Cons of Using LLMs in the Cloud Versus Running LLMs Locally, provides key considerations for selecting the optimal deployment strategy for LLMs
Let’s understand what is happening in the above code snippet:
- tokenizer.pad_token = tokenizer.eos_token: Sets padding token to be the same as the end-of-sentence token.
- model.resize_token_embeddings(len(tokenizer)): Resizes the token embedding layer of the model to match the length of the tokenizer vocabulary.
- model = prepare_model_for_int8_training(model): Prepares the model for training with INT8 precision, likely performing quantization.
- model = get_peft_model(model, lora_peft_config): Adjusts the given model according to the PEFT configuration.
- training_args = model_training_args: Assigns predefined training arguments to training_args.
- trainer = SFT_trainer: Assigns the SFTTrainer instance to the variable trainer.
- trainer.train(): Triggers the training process of the model according to the provided specifications.
Conclusion
This article has provided a clear guide on training a large language model using PyTorch. Starting with the dataset preparation, it walked through the steps of preparing the prerequisites, setting up the trainer, and finally, running the training process.
Although it used a specific dataset and pre-trained model, the process should be largely the same for any other compatible options. Now that you understand how to train an LLM, you can leverage this knowledge to train other sophisticated models for various NLP tasks.
Check out our guide on how to build LLM applications with LangChain to further explore the power of large language models. Or, if you still need to explore large language model concepts, check out our course to further your learning.



blog
What is Llama 3? The Experts' View on The Next Generation of Open Source LLMs

Richie Cotton
5 min

blog
Attention Mechanism in LLMs: An Intuitive Explanation

Yesha Shastri
8 min

blog
Top 13 ChatGPT Wrappers to Maximize Functionality and Efficiency

Bex Tuychiev
5 min

podcast
How Walmart Leverages Data & AI with Swati Kirti, Sr Director of Data Science at Walmart
Richie Cotton
31 min

podcast
Creating an AI-First Culture with Sanjay Srivastava, Chief Digital Strategist at Genpact
Richie Cotton
36 min

podcast
How a Chief AI Officer Works with Philipp Herzig, Chief AI Officer at SAP
Richie Cotton
32 min