How to Write A Data Engineer Job Description
Data science is booming, but not every role in the industry is growing at the same pace. Data engineering is rapidly gaining momentum. According to the DICE’s 2020 Tech Report, data engineering was the fastest-growing tech job, beating other traditional data positions, such as data scientists or cloud-related roles. The job was also featured in the 2020 LinkedIn U.S. Emerging Jobs Report among the 15 most outstanding emerging jobs of the last five years.
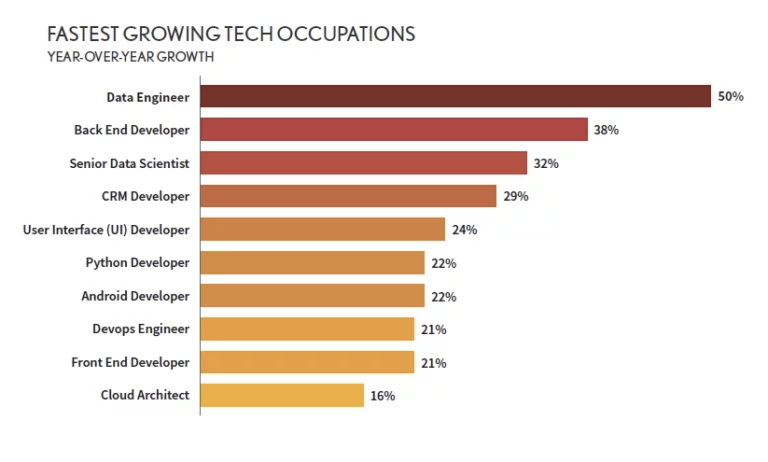
Source: DICE
But this increasing demand translates into fierce competition between companies to attract talented candidates. Data engineers are relatively new positions and are still scarce in the job market.
How to ensure your company hires a strong candidate? Job descriptions can make a big difference. A well-written job description will establish a sound set of expectations for employers to communicate to their candidates, thereby increasing the chances of finding a match.
Read on for a comprehensive guide on best practices for writing a data engineer job description that’s going to make an impact. Whether you’re trying to find the right candidate or hoping to become a data engineer, this article will help you understand what’s required in this role.
Data Engineer Roles and Responsibilities
Data engineers are responsible for laying the foundations for the acquisition, storage, transformation, and management of data in an organization. They are in charge of developing and maintaining the database architecture and data processing systems. This infrastructure is key to ensure that the development of high-level data applications, such as data visualization, and the deployment of machine learning models is carried out in a seamless, secure, and effective way.
Because of the complexity of these tasks, data engineers are highly technical data professionals, working at the interplay of data science and software development. We’ve created an entire article outlining what data engineers do, but we’ve included some brief notes here.
While the responsibilities and technologies used by data engineers vary across companies, their work run fundamentally between the following tasks:
- ETL processes. ETL involves a set of processes and routines to extract, transform, and load data from multiple sources, and move it between different environments. Data engineers ensure that the large volume of data collected from different sources becomes accessible raw material for other data science professionals, such as data analysts and data scientists. ETL processes are often performed through the so-called data pipelines, which allow us to automate, schedule, and scale the different tasks.
- Data cleaning. Generally, the likelihood of errors in data increases with the number of data sources required by a company for its activities. As a result, it’s not surprising that data engineers spend most of their time cleaning data, that is, fixing or removing incorrect, corrupted, incorrectly formatted, duplicate, or incomplete data.
- Data monitoring. Between the conception phase and the production phase of a machine learning model, there is a long way full of potential obstacles. Data engineers are also tasked with the monitoring and optimization of the data architecture and data processing systems.
If you’re interested in becoming a data engineer, a great way to get started is our Data Engineer With Python Track.
What to include in Data Engineer Job Description
In this section, we will have a look at the elements you should include in each of the different parts of a data engineer job description.
Description
This section provides an introduction to the position. You should include a brief description of the company and the reason why it’s looking for a new data engineer. You should also add the kinds of tasks and projects the successful candidate will deal with, as well as some of the technical requirements of the job. Finally, in this section, you should provide the level of experience your company is looking for. This will help job seekers rapidly decide whether to invest more time and energy in preparing a formal application.
Data Engineer Responsibilities
A data engineer is one of the most technical profiles in the data science industry, combining knowledge and skills from data science, software development, and database management.
While the specific responsibilities may vary depending on the job, there are certain tasks that every data engineer should be capable of performing. Below you can find the most important:
- Architecture design. While designing a company's data architecture is sometimes the work of a data architect, in many cases, the data engineer is the person in charge. This involves being fluent with different types of databases, warehouses, and analytical systems.
- ETL processes. Collecting data from different sources, processing it, and storing it in a ready-to-use format in the company’s data warehouse are some of the most common activities of data engineers.
- Data pipeline management. Data pipelines are data engineers’ best friends. The ultimate goal of data engineers is automating as many data processes as possible, and here data pipelines are key. Data engineers need to be fluent in developing, maintaining, testing, and optimizing data pipelines.
- Machine learning model deployment. While data scientists are responsible for developing machine learning models, data engineers are responsible for putting them into production.
- Cloud management. Cloud-based services are rapidly becoming a go-to option for many companies that want to make the most out of their data infrastructure. As an increasing number of data activities take place in the cloud, data engineers have to be able to work with cloud tools hosted in cloud providers, such as AWS, Azure, and Google Cloud.
- Data monitoring. Ensuring data quality is crucial to make every data process work smoothly. Data engineers are responsible for monitoring every process and routines and optimizing their performance.
Experience
Data engineering is a relatively new role in data science. As such, only a few universities and colleges offer pure data engineering degrees. Data engineers typically have a background in data science, software engineering, math, or a business-related field.
To increase the pool of applicants, you could also consider allowing candidates who, despite having a different educational background, can prove their competencies with several years of relevant working experience.
Minimum Qualifications
As a highly technical role, data engineers must be fluent in many tools. However, making a detailed and comprehensive list of tools and technologies to succeed in any data engineering role is very difficult because the data science ecosystem is rapidly evolving, and new technologies and systems are constantly appearing.
Since knowing all of them is impossible, you should only include the software, technologies, and tools required for the job or planned to be adopted in the future.When preparing this section of the data engineer job description, make sure to frame the qualifications specifically for data engineers rather than listing general data science skills. To do so, you should consult the team members the successful candidate will work with.
In addition to technical skills, in this section, you should also include the soft skills required for the role.
Here is a list non-exhaustive list of qualifications and skills you should include in your job description:
- Advanced SQL skills and relational database management
- Object-oriented programming languages, like Python, Java, and Scala.
- Experience with distributed computing frameworks, such as Hadoop or Spark
- Data pipelines and workflow management tools (e.g. Airflow)
- Cloud-based solutions (e.g. AWS, Azure, Google Cloud)
- Strong project management and organizational skills.
- Excellent problem-solving, communication, and organizational skills.
- Proven ability to work independently and with a team.
Extra Tips for Writing a Compelling Data Engineer Job Description
Even with a perfectly curated set of job descriptions and expectations, the sheer volume of job ads can bury your ad out of candidates’ sight. To keep your job descriptions compelling and clickable, consider the following:
- Include the salary range. A study by SMART Recruit Online found that when job ads include a salary range in them, they get over 30% more applicants. Provide a data engineer salary range that matches the requirements and seniority to bag your ideal candidate.
- Include benefits. Candidates are becoming more discerning with labor conditions and work-life balance. Make sure to include them to make the job opening more attractive.
- Give insight into workplace culture. Share details about the team, cultures, and values of the workplace. This will help candidates to envision themselves working with you and check if they align with your culture.
- Define the hiring process with human resources. Candidates are keen to know what the hiring process will involve so they can prepare for interviews and meetings.
Hire job-ready data scientists
Get access to our pool of DataCamp certified professionals for free for 15 days.
What skills and knowledge are required for a data engineer?
What are some common responsibilities of a data engineer?
What is the difference between a data engineer and a data scientist?
blog
How to Write a Data Scientist Job Description in 2024

Matt Crabtree
12 min
blog
How to Write a Data Analyst Job Description

Chloe Lubin
11 min
blog
5 Essential Data Engineering Skills

Joleen Bothma
11 min
blog
What Does a Data Engineer Do?
Joleen Bothma
9 min
blog
How to Craft an Impactful Data Engineer Cover Letter (With Examples)
Eva Chan
14 min


blog
How to Become a Data Engineer in 2024: 5 Steps for Career Success

Javier Canales Luna
18 min