course
Introduction to Data Engineering
4 hours
110.9K

The role of data engineer is rapidly gaining ground in the data science ecosystem. According to the 2020 DICE Tech Job Report, data engineering was the fastest-growing tech-oriented occupation in 2019. The job also appeared in the 2020 LinkedIn U.S. Emerging Jobs Report among the 15 most outstanding emerging jobs of the last five years, with a hiring growth rate that has increased by 35% since 2015. LinkedIn also ranked it 13th in the UK's Jobs on the Rise 2023 report.
A similar report from 2021 shows that although some data science roles are slowing down, data engineering interviews increased by 40% year on year. Similarly, another report found that the projected data engineer job growth rate is 21% from 2018-2028.
The data engineering market in India is expected to grow at a compound annual growth rate of 33.8% over the next 5 years, increasing from $29 billion in 2023 to $124 billion by 2028, driven in part by the rise of generative AI and large language models.
You can find out about some of the other top analytics careers in a separate article.
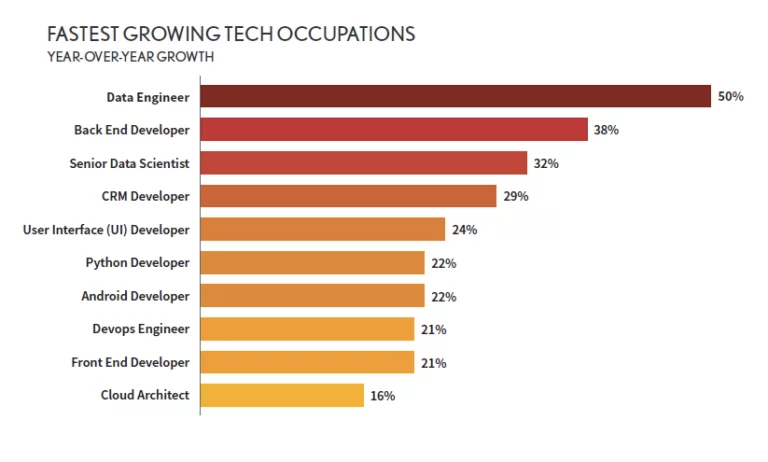
Source: DICE
If you are considering becoming a data engineer, this blog post has everything you need to know. We’ll explore what a data engineer is, what the roles and responsibilities are in their daily work, and why working as a data engineer is such a great option today. We will also look at the skills and qualifications you need to become a data engineer and provide you with some tips to help you land your first position in the industry.
However, at a glance, the technical data engineer learning path is as follows:
We’ll cover many of these points in detail in this post, as we explore how to become a data engineer.
Data engineers are responsible for laying the foundations for the acquisition, storage, transformation, and management of data in an organization. They manage the design, creation, and maintenance of database architecture and data processing systems, ensuring that the subsequent work of analysis, visualization, and machine learning model development can be carried out seamlessly, continuously, securely, and effectively.
In short, data engineers are the most technical profiles in the field of data science, playing a critical bridging role between software and application developers and traditional data science positions.
Data engineers are responsible for the first stage of the traditional data science workflow: the process of data collection and storage. They ensure that the large volume of data collected from different sources becomes accessible raw material for other data science specialists, such as data analysts and data scientists.
On one hand, this entails developing and maintaining scalable data infrastructures with high availability, performance, and capability to integrate new technologies. On the other hand, data engineers are also tasked with monitoring the movement and status of data throughout these systems.
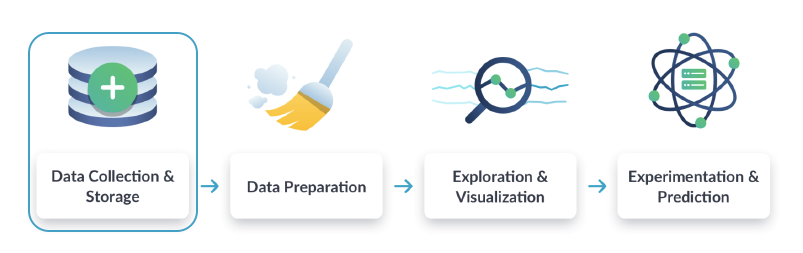
Data Science Workflow
Data engineers are key players in the development and maintenance of any company's data architecture. They are specialists in preparing large datasets for analysts to use. When an analyst needs to interpret information, the data engineer creates programs and routines to prepare data in a suitable layout.
As a result, the data engineer’s day-to-day runs fundamentally between three processes:
However, the process of data collection and storage can be extremely complex. There may be different data sources involved, and these data sources may have different types of data. As the volume, variety, and velocity of the data at hand increase, so does the complexity of the data engineer’s work.
Data engineers develop so-called data pipelines to ensure that the tasks performed are timely, robust, and scalable. A data pipeline moves data into defined stages, one example of which is loading data from an on-premise database to a cloud service.
A key feature is that pipelines automate this movement. Instead of asking a data engineer to manually run a program every time new data is created, they could schedule the task to be triggered hourly, daily, or following a certain event.
Since the process is automated, data pipelines need to be monitored. Luckily, alerts can be generated automatically. Data pipelines aren't necessary for all data science projects, but they are when working with a lot of data from different sources, as is normally the case in data-driven companies. If you are interested in learning how data pipelines work in practice, we recommend you check out our course Building Data Engineering Pipelines in Python.
Still wondering what a data engineer does? Check out our full article to find out more.
Below, we’ve outlined the steps you need to take to pursue a career as a data engineer. You’ll find that the exact steps depend somewhat on your current skills and experience, but this process can guide you through becoming a data engineer from scratch.
Data engineering is an emerging job. As such, only a few universities and colleges offer data engineering degrees. Data engineers typically have a background in Data Science, Software Engineering, Math, or a business-related field.
Depending on their job or industry, most data engineers get their first entry-level job after earning their bachelor’s degrees. However, given the highly specialized skill set required to conduct the tasks of data engineers, in many cases, knowledge and competencies prevail over education.
Hence, if you want to pursue a formal education, make sure to choose a degree that includes system architecture, programming, and database configuration in the curriculum.
You can also pursue options such as the DataCamp Data Engineer with Python track, which will teach you all of the fundamentals you need to build an effective data architecture, streamline data processing, and maintain large-scale data systems.
Data engineers require a significant set of technical skills to address their highly complex tasks. However, it’s very difficult to make a detailed and comprehensive list of skills and knowledge needed to succeed in any data engineering role; in the end, the data science ecosystem is rapidly evolving, and new technologies and systems are constantly appearing. This means that data engineers must constantly learn to keep pace with technological breakthroughs.
Notwithstanding this, here is a non-exhaustive list of skills you’ll need to develop to become a data engineer:
Data engineers spend a considerable part of their daily work operating databases, either to collect, store, transfer, clean, or just consult data. Hence, data engineers must have a good knowledge of database management. This means being fluent with SQL (Structured Query Language), the basic language to interact with databases, and having expertise with some of the most popular SQL dialects, including MySQL, SQL Server, and PostgreSQL.
In addition to relational databases, data engineers need to be familiar with NoSQL (“Not only SQL”) databases, which are rapidly becoming the go-to systems for Big Data and real-time applications.
Therefore, although the number of NoSQL engines is on the rise, data engineers should at least understand the difference between NoSQL database types and the use cases for each of them. If you are confused about NoSQL and how it differs from SQL, our course NoSQL Concepts is a great place to gain clarity.
As in other data science roles, coding is a mandatory skill for data engineers. Besides SQL, data engineers use other programming languages for a wide range of tasks. There are many programming languages that can be used in data engineering, but Python is certainly one of the best options.
Python is a lingua franca in data science, and it’s perfect for executing ETL jobs and writing data pipelines. You can read more about what Python is used for in a separate post.
Another reason to use Python is its great integration with tools and frameworks that are critical in data engineering, such as Apache Airflow and Apache Spark. Many of these open-source frameworks run on the Java Virtual Machine. If your company works with these frameworks, you will probably also need to learn Java or Scala.
In recent years, distributed systems have become ubiquitous in data science. A distributed system is a computing environment in which various components are spread across multiple computers (also known as a cluster) on a network.
Distributed systems split up the work across the cluster, coordinating the efforts to complete the job more efficiently. Distributed computing frameworks, such as Apache Hadoop and Apache Spark, are designed for the processing of massive amounts of data and provide the foundations for some of the most impressive Big Data applications. Expertise in one of these frameworks is a must for any aspiring data engineer.
Cloud computing is one of the hottest topics in data science. The demand for cloud-based solutions is rapidly changing the landscape. Today, being a data engineer entails, to a great extent, connecting your company’s business systems to cloud-based systems.
With the rise of services like Amazon Web Services (AWS), Azure, and Google Cloud, the whole data workflow can take place within the Cloud. Therefore, a good data engineer must know and have experience using cloud services, their advantages, disadvantages, and their application in Big Data projects. You should at least be familiar with a platform like AWS or Azure, as they are the most widespread.
To gain first hands-on experience with cloud data warehouses, try our Exploring London’s Travel Network Project. It offers a great opportunity to work with Amazon Redshift, Google BigQuery, and Snowflake directly in your browser.
One of the main roles of data engineers is to create data pipelines with ETL technologies and orchestration frameworks. In this section, we could list many technologies, but the data engineer should know or be comfortable with some of the best-known ones, such as Apache Airflow and Apache NiFi. Airflow is an orchestration framework. It’s an open-source tool for planning, generating, and tracking data pipelines. NiFi is perfect for a basic, repeatable big data ETL process.
Some of the most innovative data science applications use real-time data. As a result, the demand for candidates familiar with stream processing frameworks is on the rise. That’s why learning how to use streaming processing tools like Flink, Kafka Streams, or Spark Streaming is a smooth move for data engineers willing to take their careers to the next level.
Most of the jobs and routines of the Cloud and other Big Data tools and frameworks are executed using shell commands and scripts. Data engineers must be comfortable with the terminal to edit files, run commands, and navigate the system. Learn more with our bash script tutorial.
Last but not least, data engineers also need communication skills to work across departments and understand the needs of data analysts, data scientists, and business leaders. Depending on the organization, data engineers may also need to know how to develop dashboards, reports, and other visualizations to communicate with stakeholders.
The next step to becoming a data engineer is to work on some projects that will demonstrate your skills and understanding of core subjects. You can check out our full guide on building a data science portfolio for some inspiration.
You’ll want to demonstrate the skills we’ve already outlined to impress potential employers, which means working on a variety of projects. DataLab provides a collaborative cloud-based notebook that allows you to work on your own projects, meaning you can analyze data, collaborate with others, and share insights.
You can also apply your knowledge to various data science projects, allowing you to solve real-world problems from your browser while also contributing to your data engineering portfolio.
When you feel ready to explore a specific business area of your choice, you may start focusing on gaining domain knowledge and working on individual projects related to that particular sphere.
Data engineering is one of the most in-demand positions in the data science industry. From Silicon Valley big tech to small data-drive startups across sectors, businesses are looking to hire data engineers to help them scale and make the most of their data resources. At the same time, companies are having trouble finding the right candidates, given the broad and highly specialized skill set required to meet an organization's needs.
Given this particular context, there is no perfect formula to land your first data engineering job. In many cases, data engineers arrive in their position following a transition from other data science roles within the same company, such as data scientist or database administrator.
Instead, if you are looking for data engineering opportunities in job portals, an important thing to keep in mind is that there are many job openings that include to the title “data engineer”, including cloud data engineer, big data engineer, and data architect. The specific skills and requirements will vary from position to position, so the key is to find a closer match between what you know and what the company needs.
You can check out our full guide on applying for data science jobs to learn how to set yourself apart from other candidates. You’ll likely need a fairly thorough portfolio demonstrating a range of skills. You can also find some useful info about what hiring managers want in our article on how to write a data engineer job description.
The answer is simple: keep learning. There are many pathways to deepen your expertise and broaden your data engineering toolkit.
You could also opt for further formal education, whether it’s a bachelor’s degree in data science or computer science, a closely related field, or a master’s degree in data engineering.
In addition to education, practice is the key to success. Employers in the field are looking for candidates with unique skills and a strong command of software and programming languages. The more you train your coding skills in personal projects and try big data tools and frameworks, the more chances you will have to stand out in the application process. To prove your expertise, a good option is to get certified in data engineering.
Finally, if you are having difficulties finding your first job as a data engineer, consider applying for other entry-level data science positions. In the end, data science is a collaborative field with many topics and skills that are transversal across data roles. These positions will provide you with valuable insights and experience that will help you land your dream data engineering position.
Data engineering interviews are normally broken down into technical and non-technical parts. You can check out our full guide exploring the top data engineering interview questions and answers.
However, in brief, you can expect questions related to four topics:
Recruiters will want to know about your experiences related to the data engineering position. Make sure to highlight your previous work in data science positions and projects in your resume and prepare to provide full details about them, as this information is critical for recruiters to assess your technical skills, problem-solving, communication, and project management.
This is probably the most stressful part of a data science interview. Generally, you will be asked to resolve a problem in a few lines of code within a short time using Python or a data framework like Spark.
For example, your exercise might consist of making a simple data pipeline to load and clean data. While the problem should not be very complex, the tension of the moment can negatively affect your performance. If you are not familiar with this kind of test, you could try practicing with some coding questions beforehand.
You will not go far in your data engineering career without solid expertise in SQL. That’s why, in addition to the programming test, you may be asked to solve a problem that involves using SQL. Typically, the exercise will consist of writing efficient queries to process some data in databases.
This is the most conceptual part of the technical interview and probably the most difficult. Designing data architectures is one of the most impactful tasks of data engineers. In this part, you will be asked to design a data solution from end to end, which normally comprises three aspects: data storage, data processing, and data modeling.
Given the rapidly growing scope of data science ecosystems, the options for design are endless. You need to be ready to discuss the pros and cons and the possible trade-offs of your choices.
Once you have completed the technical part, the last step of the data engineering interview will consist of a personal interview with one or more of your prospective team members. The goal? To discover who you are and how you would fit in the team.
But remember, the data engineer interview is a two-sided conversation, meaning that you should also pose questions to them to determine whether you could see yourself as a part of the team.
Data engineering is an emerging job, and it’s not always easy for recruiters to find the right candidates. Competition for this difficult-to-find talent is high among companies, which translates into some of the highest salaries among data science roles.
According to most job portals, the average salary for data engineers in the U.S. is $114,564. However, these figures will differ depending on where in the country you’re working. For example, according to Glassdoor, the average base data analyst salary in New York is $120,637, while in California, it’s $113,610, and in Houston, it’s $94,416.
You can learn more about data engineer salaries worldwide in our separate article. You can also find out more about the various data science salaries.
Data engineering is one of the most in-demand jobs in the data science landscape and is certainly a great career choice for aspiring data professionals. If you are determined to become a data engineer but don’t know how to get started, we highly recommend you to follow our career track Data Engineer with Python, which will give you the solid and practical knowledge you’ll need to become a data engineering expert.
Learn more about data engineering with these courses!
course
track
track
blog
Elena Kosourova
20 min
blog
Joleen Bothma
11 min
blog
Jose Jorge Rodriguez Salgado
12 min
blog
Joleen Bothma
10 min
blog
Abid Ali Awan
16 min
tutorial
Karlijn Willems
3 min