Certification available
Course
Writing Efficient Python Code
4 hr
113K

In the general data engineering interview round, you will be questioned by the HR manager on your work experience and the value you bring to the company.
If the hiring manager selects you for a phone interview, they must have seen something they liked in your profile. So, you can be confident about this question and talk about your experience and career growth.
Reviewing a company’s profile and job description before sitting for an interview is important. Doing so will help you fill in the blanks of what the hiring manager is looking for. If they are looking for an individual who can design and manage data pipelines, make sure you talk specifically about it.
Generally, you can think about your skills, experience, and knowledge, and how these factors make you stand out from the crowd.
There is no absolute answer here, but you can share the experience of your last job and your responsibilities as an engineer. The job description is also a good place to look for this information.
However, in general, the daily responsibilities of data engineers include:
Although this will depend on the individual, there are some common threads in data engineer interviews. Like data scientists and DevOps engineers, the toughest part about being a data engineer can be learning and mastering various technologies. You need to keep integrating new tools which can improve the performance, security, reliability, and ROI of data systems.
Making sure you know about disaster management, data governance, security protocols, business requirements, and predicting data demands can also be hard to grasp. It is a hard job where you are responsible for so many things.
Again, this data engineer interview answer will be based on your experiences. If you are in tune with modern tools and third-party integration, you won’t have a problem answering this question.
You can talk about the tools for database management, data warehousing, data orchestration, data pipelines, cloud management, data cleaning, modeling and transformation, and batch and real-time processing.
Remember, there is no wrong answer to this question. The interviewer is assessing your skills and experience.
These questions are for experienced individuals. If you are a beginner and want to start a career in data engineering, complete the Data Engineer with Python career track. It consists of 19 courses that will teach your modern data engineering concept, programming language, tools, and frameworks.
After general rounds of interviews, you will usually progress into a technical stage which consists of coding challenges, problem-solving, database system design on a whiteboard, a take-home exam, and analytical questions.
This stage can be quite intense, so knowing some of the usual data engineering interview questions and answers can help you ace the interview.
This answer should come naturally if you have previously worked on a data engineering project as a student or a professional. That being said, preparing ahead of time is always helpful.
Make sure you explain how it started and what business problem you were solving. Furthermore, explain each step from accessing the raw data and converting it into a cleaned structure data.
Sometimes you are working on multiple projects, and you freeze at this question. To avoid this ever happening, it is a good practice to review the last five projects you have worked on. You can read the project documentation and understand the problem statement.
Check out the example below:
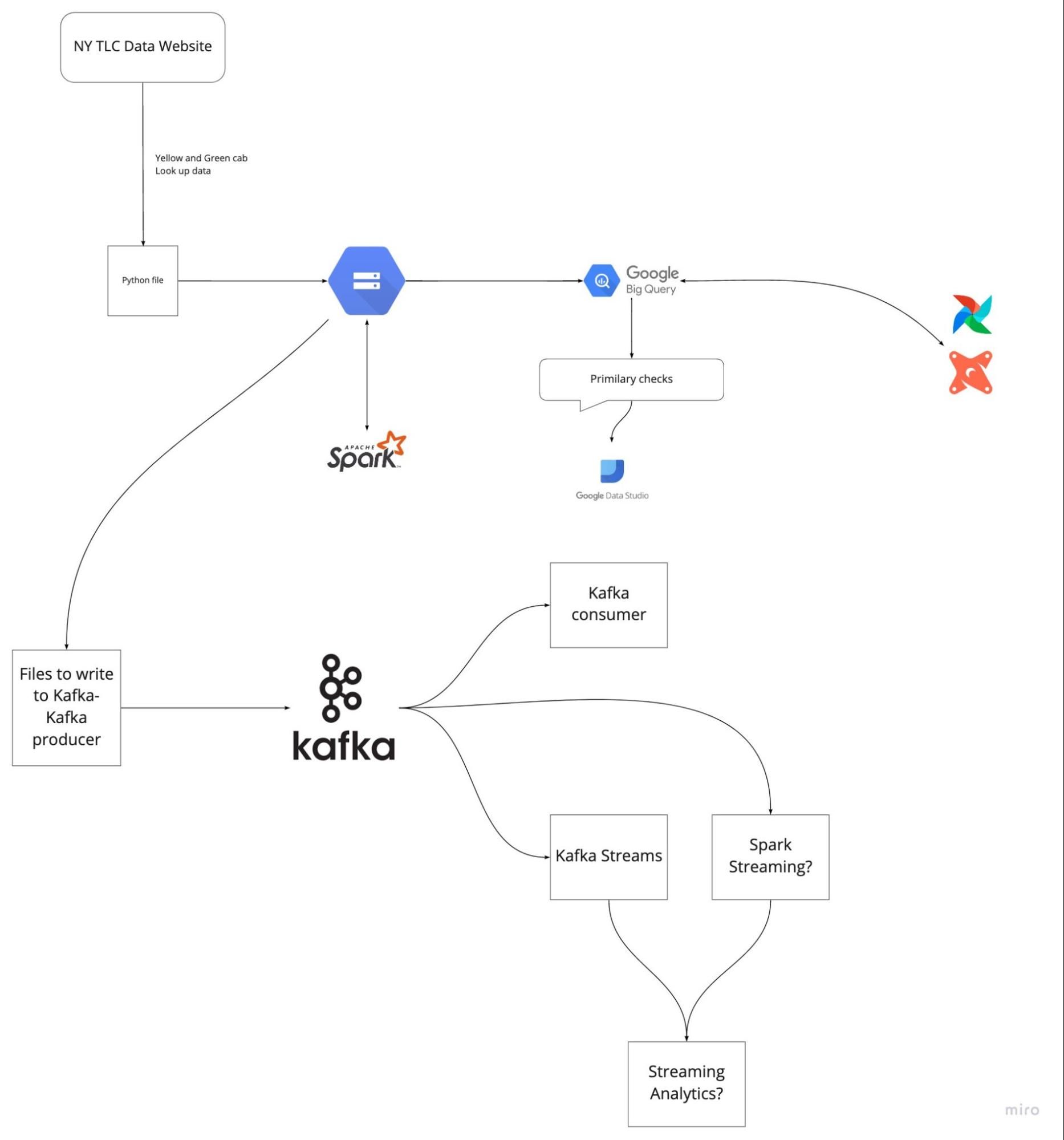
Image from DataTalksClub/data-engineering-zoomcamp
In the above project, we are ingesting TLC Trip Record data, processing, transforming, and serving it using Kafka and Spark streams.
In the project:
The junior engineering interviews are more focused on tools, coding, and SQL queries. It involves questions about database management, ETL, coding challenges, and taking home exams.
When companies hire fresh graduates, they want to make sure that you are capable of handling their data and systems.
There are three data modeling design schemas: Star, Snowflake, and Galaxy.
The star schema contains various dimension tables which are connected to that fact table in the center.
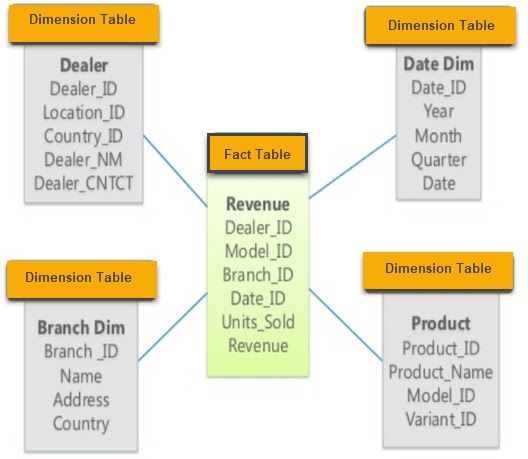
Image from guru99
Snowflake is the extension of the star schema. It consists of a fact table and dimension tables with snowflake-like layers.
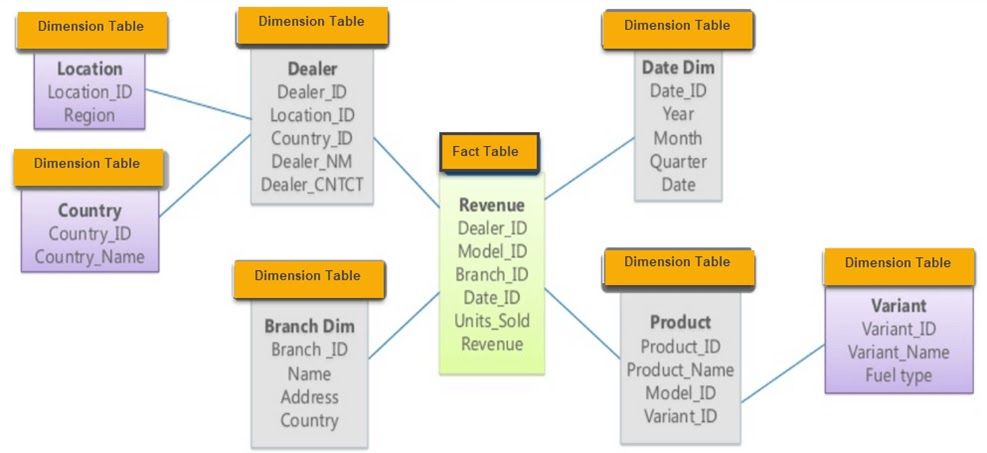
Image from guru99
The Galaxy schema contains two fact tables, and it shares dimension tables between them.
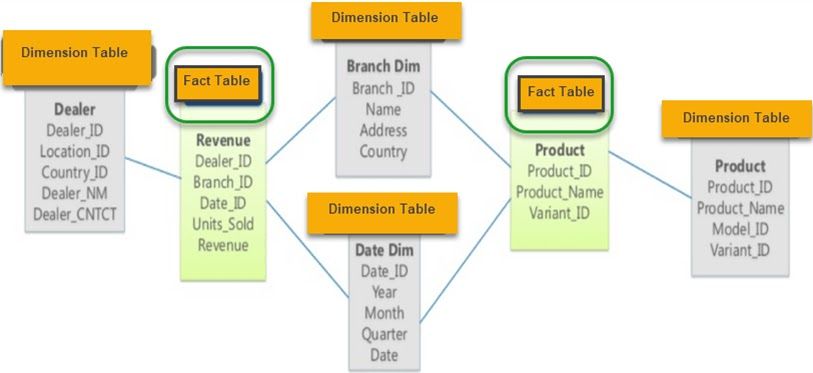
Image from guru99
Here, you should mention the list of tools that you have mastered and explain why you have selected certain tools for certain projects.
The hiring manager is assessing your experience and knowledge of various ETL tools, so explain your reason for selecting tools in terms of pros and cons.
You can also mention popular open-source tools such as dbt, Spark, Kafka, and Airbyte. You can refresh your knowledge of ETL by taking an Introduction to Data Engineering course.
For engineering manager positions, the questions are related to decision making, business understanding, curating and maintaining datasets, compliance, and security policies.
A Data warehouse serves historical data for data analytics tasks and decision making. It supports high-volume analytical processing such as OLAP. Data warehouses are designed to load high and complex queries that access multiple rows. The system supports a few concurrent users, and it is designed to retrieve fast and high volumes of data.
Operational Database Management Systems are used to manage dynamic datasets in real-time. They support high-volume transaction processing for thousands of concurrent clients. Usually, the data consists of day-to-day information about business operations.
Disaster management is the most crucial part of a data engineer manager's job. The data engineer manager plans and prepares for disaster recovery for various data storage systems.
This task involves real-time backing up of files and media. The backup storage will be used to restore the files in case of a cyber-attack or equipment failure. Security protocols are placed to monitor, trace, and restrict both incoming and outgoing traffic.

Image by Author
Data orchestration is an automated process for accessing raw data from multiple sources, performing data cleaning, transformation, and modeling techniques, and serving it for analytical tasks. The most popular tools are Apache Airflow, Prefect, Dagster, and AWS Glue.
Analytical engineering is a process where we access the processed data, transform it, apply statistical modeling, and visualize it in the form of reports and dashboards. The popular tools are dbt (data build tool), BigQuery, Postgres, Metabase, Google Data Studio, and Tableau.
The most popular libraries for data processing are pandas and Numpy. For parallel processing of large datasets, we use Dask, Pyspark, Datatable, and Rapids. They all have pros and cons, and we must understand the application based on data requirements.
In some cases, pandas.read_html works wonders. It extracts, processes, and converts data in a structured format.
Note: it is good practice to take coding challenges on sites like HackerRank, Codewars, and LeetCode. You hone your Python skills by taking DataCamp’s 5 Python challenges.
The SQL coding stage is a big part of the data engineering hiring process. You can practice various simple and complex scripts. The interviewer may ask you to write a query for data analytics, common table expressions, ranking, adding subtotals, and temporary functions.
These are used to simplify complex joins and run subqueries.
In the SQL script below, we are running a simple subquery to display all students with Science majors and grade A.
SELECT *
FROM class
WHERE id in
(SELECT DISTINCT id
FROM id
WHERE grade= "A"
AND major= "Science"
)If we are using this subquery multiple times, we can create a temporary table “temp” and call it in our query using the SELECT command as shown below.
WITH temp as (
SELECT id as id
FROM id
WHERE grade= "A"
AND major= "Science"
)
SELECT *
FROM class
WHERE id in (SELECT id from temp)You can translate this example for even complex problems.
Data engineers commonly rank values based on parameters such as sales and profit.
The query below ranks the data based on sales. You can also use DENSE_RANK(), which does not skip subsequent ranks if the values are the same.
SELECT
id,
sales,
RANK() OVER (ORDER BY sales desc)
FROM billJust like Python, you can create a function in SQL and use it in your query. It looks elegant, and you can avoid writing huge case statements - Better Programming.
In the script below, we have created a simple “get_gender” temporary function. It uses CASE to change Type from “M/F” to full form “male/female”. After that, we can invoke it by providing a column name to the get_gender function.
CREATE TEMPORARY FUNCTION get_gender(type varchar) AS (
CASE WHEN type = "M" THEN "male"
WHEN type = "F" THEN "female"
ELSE "n/a"
END
)
SELECT
name,
get_gender(Type) as gender
FROM classSolving SQL coding exercises is the best way to practice and revise forgotten concepts. You access your SQL skills by taking DataCamp’s assessment test Data Analysis in SQL (you will need a DataCamp account to access this assessment).
In this section, we explore the most frequently asked data engineering interview questions by Facebook, Amazon, and Google and HR managers for a data engineering position.
The Kafka cluster consists of multiple brokers to distribute data on multiple instances. It is scalable without downtime. The Apache Kafka clusters are used to avoid delays. If the primary cluster goes down, other Kafka clusters will be used to deliver the same services.
The Kafka cluster architecture consists of Topics, Broker, ZooKeeper, Producers, and Consumers. It handles data streams for big data, which is used to create data-driven applications.
Apache Airflow allows you to manage and schedule pipelines for the analytical workflow, data warehouse management, and data transformation and modeling under one roof.
You can monitor execution logs in one place, and callbacks can be used to send failure alerts to Slack and Discord. Finally, it is easy to use, provides a helpful user interface and robust integrations, and is free to use.
It is the most common question asked during coding interviews, and the answer is simple. You are going to split the string on “.” and create multiple checks to determine the validity of the IP address.
def is_valid(ip):
ip = ip.split(".")
for i in ip:
if (len(i) > 3 or int(i) < 0 or
int(i) > 255):
return False
if len(i) > 1 and int(i) == 0:
return False
if (len(i) > 1 and int(i) != 0 and
i[0] == '0'):
return False
return True
A = "255.255.11.135"
B = "255.050.11.5345"The A IP is valid and it returns True, whereas B returns False as it has 4 digits after the dot.
print(is_valid(A))
>>> True
print(is_valid(B))
>>> FalseHadoop mainly works on 3 modes:
You can avoid duplicates using DISTINCT.
The query below will return unique data points from the CUSTOMERS table.
SELECT DISTINCT Name, ADDRESS FROM CUSTOMERS
ORDER BY Name;Or delete duplicate rows using rowid with Max or Min command.
The SQL query is deleting rowid where rowid is a MAX, group by employee name and address. It will group the table into Name and ADDRESS and pick the highest row id and discard the others. Every record in the table has a unique rowid that points to a physical location in the disk.
DELETE FROM Employee
WHERE rowid NOT IN (
SELECT MAX(rowid)
FROM Employee
GROUP BY Name, ADDRESS
);This is one of the most common coding interview challenges. The interviewer is looking for efficient code with reasoning.
We will create the search_missing_number function that will:
def search_missing_number(list_num):
n = len(list_num)
# checks
if(list_num[0] != 1):
return 1
if(list_num[n-1] != (n+1)):
return n+1
total = (n + 1)*(n + 2)/2
sum_of_L = sum(list_num)
return total - sum_of_LValidation:
num_list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 13]
print("The missing number is", search_missing_number(num_list))
>>> The missing number is 12.0Before appearing for an interview, you should review all of the concepts and standard terms used in data engineering. Furthermore, you should prepare for a technical interview.
Learn how to become a data engineer to jump-start your career and land a job in the most in-demand career in data science.
Courses for Data Engineers
Course
Course
Course
Abid Ali Awan
10 min
Nisha Arya Ahmed
6 min
Srujana Maddula
9 min
Kurtis Pykes
8 min
Bex Tuychiev
9 min
Zoumana Keita









