
track
AI Fundamentals
10hrs hours
The Artificial Intelligence (AI) development surge has created a notable increase in computing demands, driving the necessity for robust hardware solutions. Graphics Processing Units (GPUs) and Tensor Processing Units (TPUs) have emerged as pivotal technologies in addressing these demands.
Originally designed for rendering graphics, GPUs have evolved into versatile processors capable of handling AI tasks efficiently due to their parallel processing capabilities. In contrast, TPUs, developed by Google, are specifically optimized for AI computations, offering superior performance tailored for tasks like machine learning projects.
In this article, we will discuss GPUs vs TPUs and compare the two technologies based on metrics such as performance, cost, ecosystem, and more. We will also give you a rundown of their energy efficiency, environmental impact, and scalability in enterprise applications.
GPUs are specialized processors initially developed for rendering images and graphics in computers and gaming consoles. They function by breaking complex problems into several tasks and working on them simultaneously rather than one by one, as occurs in CPUs.
Due to their parallel processing power, their capabilities have evolved significantly beyond graphics processing, becoming integral components in various computing applications, such as the development of AI models.
But let’s rewind a little bit.
GPUs first hit the scene during the 1980s as specialized hardware for accelerating graphics rendering. Companies like NVIDIA and ATI (now part of AMD) played pivotal roles in their development. However, they didn’t gain mainstream popularity until the late 1990s and early 2000s. Their adoption was due to the introduction of programmable shaders, enabling developers to leverage parallel processing for tasks beyond graphics.
In the 2000s, more research explored GPUs for general-purpose computing tasks beyond graphics. NVIDIA's CUDA (Compute Unified Device Architecture) and AMD's Stream SDK enabled developers to harness GPU processing power for scientific simulations, data analysis, and more.
Then came the rise of AI and deep learning.
GPUs emerged as indispensable tools for training and deploying deep learning models due to their ability to handle massive amounts of data and perform computations in parallel.
Frameworks like TensorFlow and PyTorch utilize GPU acceleration, making deep learning accessible to researchers and developers worldwide.
Tensor Processing Units (TPUs) are a type of application-specific integrated circuit (ASIC) pioneered by Google to address the growing computational demands of machine learning.
In contrast to GPUs, which were initially created for graphics processing tasks and subsequently modified to cater to the demands of AI, TPUs were designed specifically to accelerate machine learning workloads.
Since they were designed for machine learning, TPUs are engineered specifically for tensor operations, which are fundamental to deep learning algorithms.
Due to their custom architecture optimized for matrix multiplication, a key operation in neural networks, they excel in processing large volumes of data and executing complex neural networks efficiently, enabling fast training and inference times.
This specialized optimization makes TPUs indispensable for AI applications, driving advancements in machine learning research and deployment.
TPUs and GPUs offer distinct advantages and are optimized for different computational tasks. While both can accelerate machine learning workloads, their architectures and optimizations lead to variations in performance depending on the specific task.
For starters, both GPUs and TPUs are specialized hardware accelerators designed to enhance performance in AI tasks, but they differ in their computational architectures, which significantly impacts their efficiency and effectiveness in handling specific types of computations.
GPUs consist of thousands of small, efficient cores designed for parallel processing.
This architecture allows them to execute multiple tasks simultaneously, making them highly effective for tasks that can be parallelized, such as graphics rendering and deep learning.
GPUs are particularly adept at matrix operations, which are prevalent in neural network computations. Their ability to handle large volumes of data and execute computations in parallel makes them well-suited for AI tasks that involve processing massive datasets and executing complex mathematical operations.
In contrast, TPUs prioritize tensor operations, allowing them to perform computations efficiently. While TPUs may not have as many cores as GPUs, their specialized architecture enables them to outperform GPUs in certain types of AI tasks, especially those heavily relying on tensor operations.
That said, GPUs excel in tasks that benefit from parallel processing and are well-suited for various computations beyond AI, such as graphics rendering and scientific simulations.
On the other hand, TPUs are optimized for tensor processing, making them highly efficient for deep learning tasks that involve matrix operations. Depending on the specific requirements of the AI workload, either GPUs or TPUs may offer better performance and efficiency.
GPUs are known for their versatility in handling various AI tasks, including training deep learning models and performing inference operations. This is because GPU architecture, which relies on parallel processing, significantly boosts training and inference speed across numerous AI models. For example, processing a batch of 128 sequences with a BERT model takes 3.8 milliseconds on a V100 GPU compared to 1.7 milliseconds on a TPU v3.
Conversely, TPUs are finely tuned for quick and efficient tensor operations, crucial components of neural networks. This specialization often allows TPUs to outperform GPUs in specific deep learning tasks, particularly those optimized by Google, like extensive neural network training and complex machine learning models.
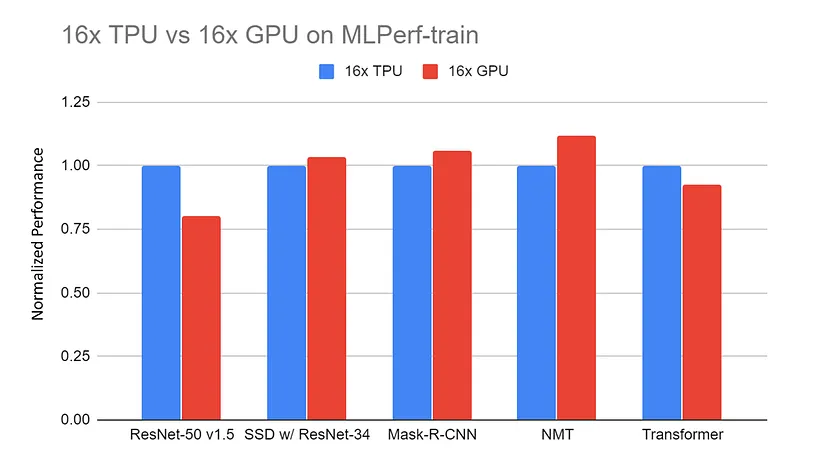
16x GPU server (DGX-2H) vs 16x TPU v3 server normalized performance on MLPerf-train benchmarks. The data is collected from the MLPerf website. All the TPU results are using TensorFlow. All the GPU results are using Pytorch, except ResNet is using MxNet |
Source: TPU vs. GPU vs Cerebras vs. Graphcore: A Fair Comparison between ML Hardware by Mahmoud Khairy
Comparisons between TPUs and GPUs in similar tasks frequently reveal TPUs outperforming GPUs in tasks specifically tailored to their architecture, providing quicker training durations and more effective processing.
For example, training a ResNet-50 model on the CIFAR-10 dataset for 10 epochs using an NVIDIA Tesla V100 GPU takes approximately 40 minutes, averaging 4 minutes per epoch. In contrast, using a Google Cloud TPU v3, the same training takes only 15 minutes, averaging 1.5 minutes per epoch.
Nonetheless, GPUs retain competitive performance across a broader spectrum of applications due to their adaptability and the considerable optimization endeavors undertaken by the community.
The choice between GPU and TPU depends on budget, computing needs, and availability. Each option offers unique advantages for different applications. In this section, we will see how GPUs and TPUs compare in terms of cost and market accessibility.
GPUs offer much more flexibility than TPUs when it comes to costs. For starters, TPUs are not sold individually; they are only available as a cloud service through providers like Google Cloud Platform (GCP). In contrast, GPUs can be purchased individually.
The approximate cost of an NVIDIA Tesla V100 GPU is between $8,000 and $10,000 per unit, and an NVIDIA A100 GPU unit is between $10,000 and $15,000. But you also have the option of on-demand cloud pricing.
Using the NVIDIA Tesla V100 GPU to train a deep learning model is likely to set you back around $2.48 per hour, and the NVIDIA A100 would be around $2.93. On the other hand, the Google Cloud TPU V3 would cost around $4.50 per hour, and the Google Cloud TPU V4 will cost approximately $8.00 per hour.
In other words, TPUs are much less flexible than GPUs and generally have higher hourly costs for on-demand cloud computing than GPUs. However, TPUs often offer faster performance, which can reduce the total computation time required for large-scale machine learning tasks, potentially leading to overall cost savings despite the higher hourly rates.
The availability of TPUs and GPUs in the market varies widely, influencing their adoption across different industries and regions…
TPUs, developed by Google, are mainly accessible through the Google Cloud Platform (GCP) for cloud-based AI tasks. This means they're primarily used by people relying on GCP for their computing needs, which might make them more popular in areas and industries big on cloud computing, like tech hubs or places with strong internet connections.
Meanwhile, GPUs are made by companies like NVIDIA, AMD, and Intel, and they're available in various options for consumers and businesses alike. This wider availability makes GPUs a popular choice across various industries, including gaming, science, finance, healthcare, and manufacturing. GPUs can be set up on-premises or in the cloud, giving users flexibility in their computing setup.
Consequently, GPUs are more likely to be used across different industries and regions, regardless of their tech infrastructure or computing needs. Overall, the market availability of TPUs and GPUs influences how they are adopted. TPUs are more common in cloud-focused areas and sectors (e.g., Machine learning), while GPUs are widely used across different fields and locations.
Google’s TPUs are tightly integrated with TensorFlow, its leading open-source machine learning framework. JAX, another library for high-performance numerical computing, also supports TPUs, enabling efficient machine learning and scientific computing.
TPUs are seamlessly integrated into the TensorFlow ecosystem, making it straightforward for TensorFlow users to leverage TPU capabilities. For example, TensorFlow offers tools such as TensorFlow XLA (Accelerated Linear Algebra) compiler, which optimizes computations for TPUs.
In essence, TPUs are designed to accelerate TensorFlow operations, providing optimized performance for training and inference. They also support TensorFlow's high-level APIs, making it easier to migrate and optimize models for TPU execution.
In contrast, GPUs are widely adopted across various industries and research fields, making them popular for diverse machine learning applications. This means they have more integrations than GPUs and are supported by a wider range of deep learning frameworks, including TensorFlow, PyTorch, Keras, MXNet, and Caffe.
GPUs also benefit from extensive libraries and tools like CUDA, cuDNN, and RAPIDS, further enhancing their versatility and ease of integration into various machine learning and data science workflows.
Regarding community support, GPUs have a broader ecosystem with extensive forums, tutorials, and documentation available from various sources like NVIDIA, AMD, and community-driven platforms. Developers can access vibrant online communities, forums, and user groups to seek help, share knowledge, and collaborate on projects. Additionally, numerous tutorials, courses, and documentation resources cover GPU programming, deep learning frameworks, and optimization techniques.
Community support for TPUs is more centralized around Google's ecosystem, with resources primarily available through GCP documentation, forums, and support channels. While Google provides comprehensive documentation and tutorials specifically tailored for using TPUs with TensorFlow, community support may be more limited than the broader GPU ecosystem. However, Google's official support channels and developer resources still offer valuable assistance to developers utilizing TPUs for AI workloads.
The energy efficiency of GPUs and TPUs varies based on their architectures and intended applications. Generally, TPUs are more energy-efficient than GPUs, particularly the Google Cloud TPU v3, which is significantly more power-efficient than the high-end NVIDIA GPUs.
For more context:
TPUs lower power consumption can contribute to much lower operational costs and increased energy efficiency, especially in large-scale machine learning deployments.
TPUs and GPUs employ specific optimizations to enhance energy efficiency when performing large-scale AI operations.
As mentioned earlier in the article, the TPU architecture is designed to prioritize tensor operations commonly used in neural networks, allowing for the efficient execution of AI tasks with minimal energy consumption. TPUs also feature custom memory hierarchies optimized for AI computations, reducing memory access latency and energy overhead.
They leverage techniques such as quantization and sparsity to optimize arithmetic operations, minimizing power consumption without sacrificing accuracy. These factors enable TPUs to deliver high performance while conserving energy.
Similarly, GPUs implement energy-efficient optimizations to enhance performance in AI operations. Modern GPU architectures incorporate features like power gating and dynamic voltage and frequency scaling (DVFS) to adjust power consumption based on workload demands. They also utilize parallel processing techniques to distribute computational tasks across multiple cores, maximizing throughput while minimizing energy per operation.
GPU manufacturers develop energy-efficient memory architectures and cache hierarchies to optimize memory access patterns and reduce energy consumption during data transfers. These optimizations, combined with software techniques such as kernel fusion and loop unrolling, further enhance energy efficiency in GPU-accelerated AI workloads.
TPUs and GPUs both offer scalability for large AI projects, but they approach it differently. TPUs are tightly integrated into cloud infrastructure, particularly through Google Cloud Platform (GCP), offering scalable resources for AI workloads. Users can access TPUs on-demand, scaling up or down based on computational needs, which is crucial for handling large-scale AI projects efficiently. Google provides managed services and pre-configured environments for deploying AI models on TPUs, simplifying the integration process into cloud infrastructure.
On the other hand, GPUs also scale effectively for large AI projects, with options for on-premises deployment or utilization in cloud environments offered by providers like Amazon Web Services (AWS) and Microsoft Azure. GPUs offer flexibility in scaling, allowing users to deploy multiple GPUs in parallel for increased computational power.
Additionally, GPUs excel at handling large datasets thanks to their high memory bandwidth and parallel processing capabilities. This enables efficient data processing and model training, which is essential for large-scale AI projects dealing with vast datasets.
Overall, both TPUs and GPUs offer scalability for large AI projects, with TPUs tightly integrated into cloud infrastructure and GPUs providing flexibility for on-premises or cloud-based deployment. Their ability to handle large datasets and scale computational resources makes them invaluable for tackling complex AI tasks at scale.
| Feature | GPUs | TPUs |
|---|---|---|
| Computational Architecture | Thousands of small, efficient cores for parallel processing | Prioritize tensor operations, specialized architecture |
| Performance | Versatile, excel in various AI tasks, including deep learning and inference | Optimized for tensor operations, often outperform GPUs in specific deep learning tasks |
| Speed and Efficiency | E.g., 128 sequences with BERT model: 3.8 ms on V100 GPU | E.g., 128 sequences with BERT model: 1.7 ms on TPU v3 |
| Benchmarks | ResNet-50 on CIFAR-10: 40 minutes for 10 epochs (4 minutes/epoch) on Tesla V100 GPU | ResNet-50 on CIFAR-10: 15 minutes for 10 epochs (1.5 minutes/epoch) on Google Cloud TPU v3 |
| Cost | NVIDIA Tesla V100: $8,000 - $10,000/unit, $2.48/hour; NVIDIA A100: $10,000 - $15,000/unit, $2.93/hour | Google Cloud TPU v3: $4.50/hour; TPU v4: $8.00/hour |
| Availability | Widely available from multiple vendors (NVIDIA, AMD, Intel), for consumers and businesses | Mainly accessible through Google Cloud Platform (GCP) |
| Ecosystem and Development Tools | Supported by many frameworks (TensorFlow, PyTorch, Keras, MXNet, Caffe), extensive libraries (CUDA, cuDNN, RAPIDS) | Integrated with TensorFlow, supports JAX, optimized by TensorFlow XLA compiler |
| Community Support and Resources | Broad ecosystem with extensive forums, tutorials, and documentation from NVIDIA, AMD, and communities | Centralized around Google's ecosystem with GCP documentation, forums, and support channels |
| Energy Efficiency | NVIDIA Tesla V100: 250 watts; NVIDIA A100: 400 watts | Google Cloud TPU v3: 120-150 watts; TPU v4: 200-250 watts |
| Optimization for AI Tasks | Energy-efficient optimizations (power gating, DVFS, parallel processing, kernel fusion) | Custom memory hierarchies, quantization, and sparsity for efficient AI computation |
| Scalability in Enterprise Applications | Scalable for large AI projects, on-premises or cloud (AWS, Azure), high memory bandwidth, parallel processing | Tightly integrated into cloud infrastructure (GCP), on-demand scalability, managed services for deploying AI models |
Choose GPUs when:
Choose TPUs when:
GPUs and TPUs are specialized hardware accelerators used in AI applications. Originally developed for graphics rendering, GPUs excel at parallel processing and have been adapted for AI tasks, offering versatility across various industries. TPUs, in contrast, are custom-built by Google specifically for AI workloads, prioritizing tensor operations commonly found in neural networks.
This article compared GPU and TPU technologies based on their performance, cost and availability, ecosystem and development, energy efficiency and environment impact, and scaleability in AI applications. To continue your learning about TPUs and GPUs, check out some of these resources to continue your learning:
Learn AI Skills with DataCamp
track
course
course
blog
Sandra Kublik
25 min
blog
Matt Crabtree
10 min
blog
Javier Canales Luna
7 min
blog
Adel Nehme
7 min
tutorial
Abid Ali Awan
12 min
tutorial
Matt Crabtree
14 min






