track
Machine Learning Fundamentals
16hrs hours
The ever-growing field of data science thrives on data, but acquiring large, labeled datasets can be a significant bottleneck in the model development process. This is where few-shot learning steps in, offering a revolutionary approach that enables us to extract valuable insights from just a handful of examples.
In contrast to traditional supervised learning methods that demand vast amounts of data, few-shot learning empowers models to learn and adapt quickly, making them highly relevant in domains where data is scarce, expensive to collect, or sensitive in nature.
This article provides a comprehensive exploration of few-shot learning, delving into its importance, mechanisms, and diverse applications across various industries.
Few-shot learning (FSL) is a subfield of machine learning where models learn to recognize patterns and make predictions based on a very small number of training examples. This contrasts with traditional supervised learning, which often requires vast amounts of labeled data for effective training.
FSL emphasizes generalization over memorization. One of the earliest works was from the paper “Language Models are Few Shot Learners” by Tom B. Brown et al challenging the need for extensive fine-tuning.
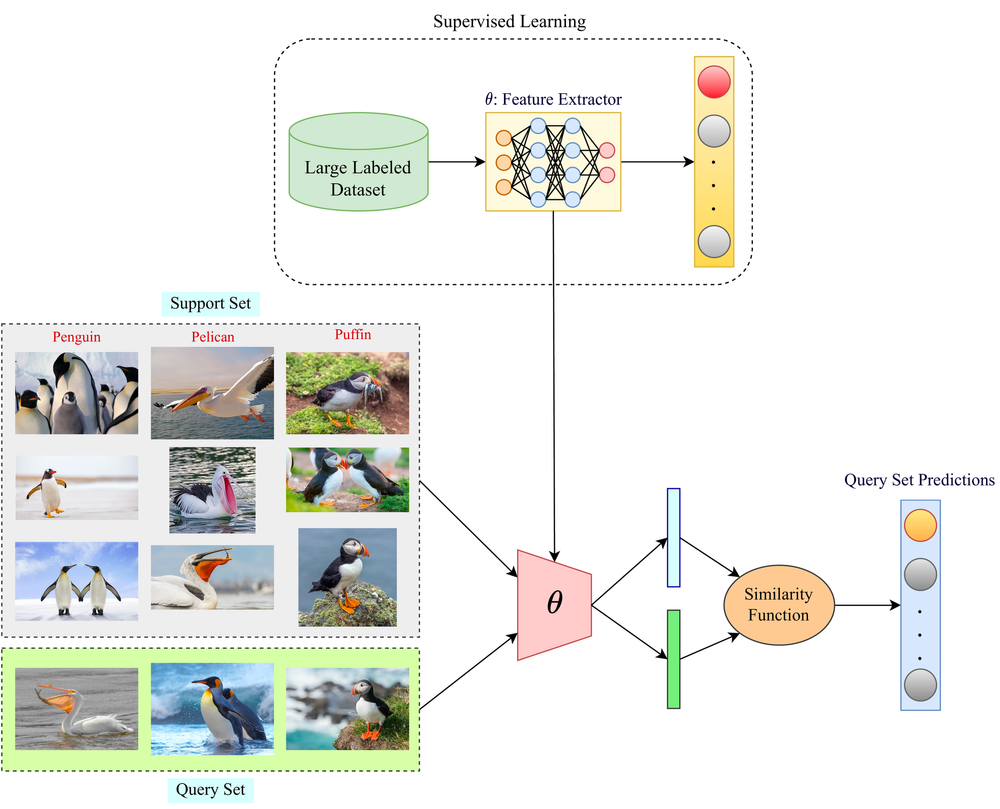
A diagram illustrating the difference between supervised learning and few-shot learning approaches. The supervised learning section shows a large labeled dataset being used to train a feature extractor model, while the few-shot learning section demonstrates using a small support set of examples and a similarity function to make predictions on a query set. Source: Paperspace
Think about a child learning to identify different animals. With just a few examples of dogs, cats, and birds, they can quickly recognize and distinguish between these creatures in the future, even if they encounter breeds or species they haven't seen before.
This ability to generalize from limited data is a hallmark of human intelligence, and it's precisely what few-shot learning aims to achieve.
The key lies in the ability to discern the underlying structure and features that define a category.
Humans possess an innate ability to extract essential information from limited experiences and apply that knowledge to new situations. Few-shot learning models attempt to emulate this by learning a general understanding of the data's underlying structure from previous experiences.
This knowledge is then leveraged to adapt quickly to new tasks with minimal additional information, just like the child recognizing a new dog breed based on their existing knowledge of dogs.
FSL helps the developer to focus on model development rather than data acquisition. The ability to learn from limited data offers several advantages:
Few-shot learning falls under the broader umbrella of n-shot learning, encompassing various techniques based on the number of examples provided:
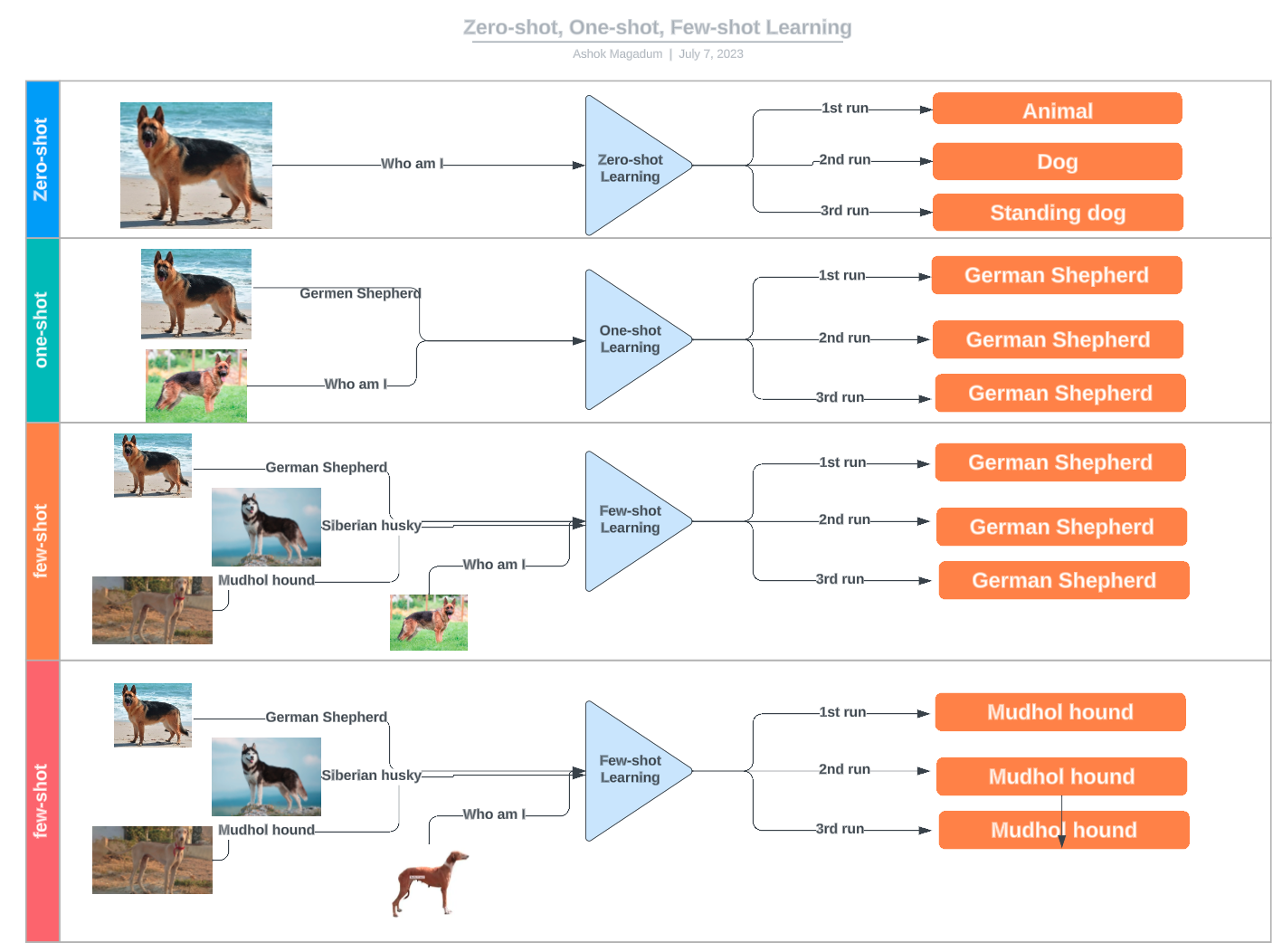
A diagram illustrating the differences between zero-shot, one-shot, and few-shot learning using examples of dog breed classification. Source: LinkedIn
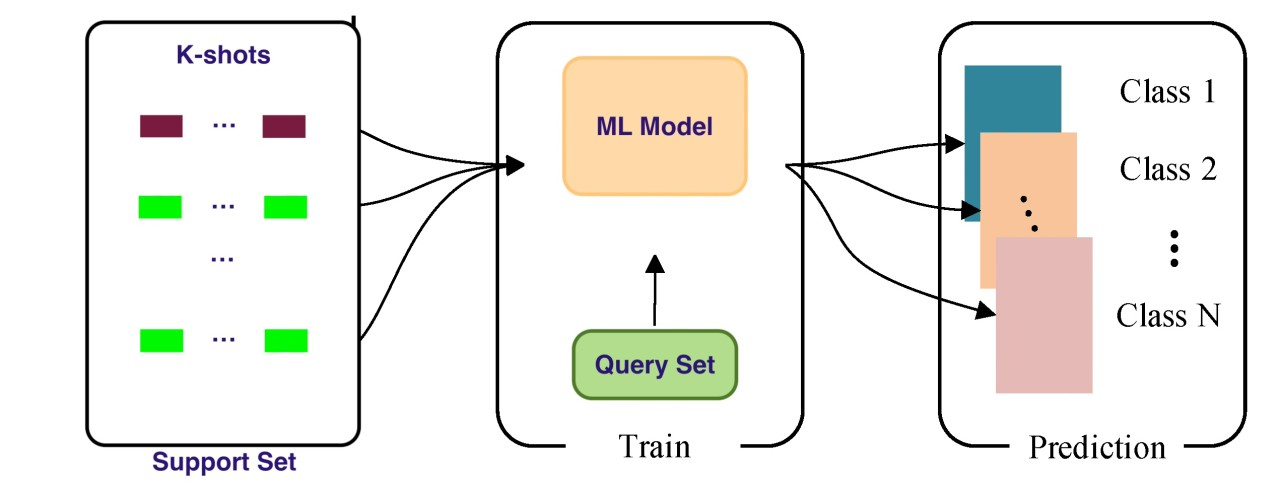
A diagram illustrating the few-shot learning process. It shows a support set containing k-shot examples for multiple classes, a machine learning model being trained on a query set, and the model then making predictions for new data instances across different classes. Source: LinkedIn
Unlike traditional supervised learning, which relies on extensive training datasets, few-shot learning models leverage prior knowledge and learning experiences to quickly adapt to new tasks with minimal additional data. By discerning the underlying structure and salient features that define a concept, these models can generalize effectively, making accurate predictions on novel instances with just a few examples.
This knowledge is then applied to quickly adapt to new tasks through a similarity function that can map the classes in the query and support sets with minimal additional information.
For context, the query set here refers to the samples from both old and new categories, which the model generalizes on and uses to evaluate performance. In contrast, the support set consists of the few labeled samples from each novel category of data, which are used to update the model’s parameters:
MAML learns a general model initialization that can be fine-tuned for specific tasks with just a few gradient steps. It is a versatile and powerful meta-learning approach, enabling models to adapt to new tasks with remarkable efficiency.
Its strength lies in its ability to learn a model initialization that facilitates rapid learning through just a few gradient descent steps on a new task.
This characteristic effectively makes the model "easy to fine-tune," allowing it to grasp the intricacies of novel tasks with minimal data quickly.
MAML operates on the principle of learning a set of initial parameters θ that are highly sensitive to changes in the task. This sensitivity ensures that small adjustments to the parameters can significantly improve the loss function of any task drawn from the task distribution p(T) when updated in the direction of the gradient of that loss.
Here's a breakdown of the MAML algorithm:
Metric learning focuses on learning a distance function that measures the similarity between data points. It focuses on learning a distance function, denoted as d(x, x'), that measures the similarity between data points x and x'. This allows models to classify new data points by comparing them to a few known examples.
Transfer learning leverages knowledge gained from a source task to improve performance on a related target task.
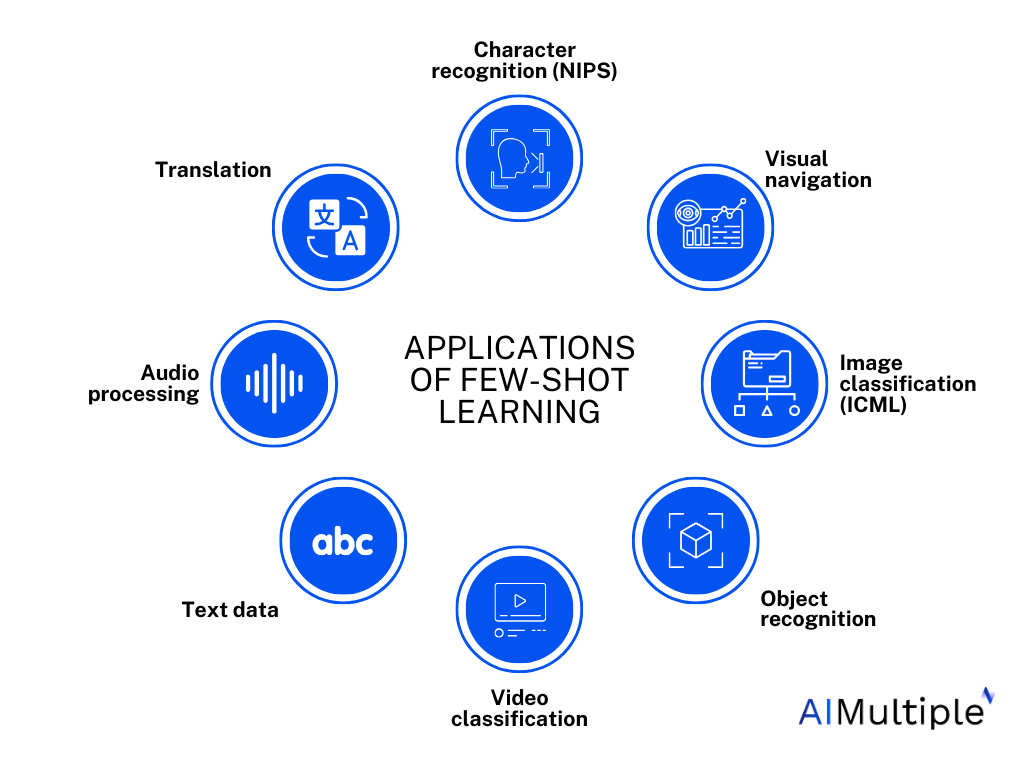
A summary of the applications of FSL in various domains. Source: AI Multiple Research
The applications of few-shot learning are vast and far-reaching, spanning fields as diverse as computer vision, natural language processing, robotics, and healthcare. In the realm of computer vision, for instance, few-shot learning can enable systems to recognize rare objects or identify obscure patterns in medical imaging with only a handful of training examples.
In natural language processing, few-shot learning could pave the way for personalized language models that can mimic an individual's unique writing style or dialect, revolutionizing content creation and communication. Additionally, it holds immense potential for preserving and translating low-resource languages, fostering greater cultural understanding and inclusivity.
Perhaps one of the most transformative applications lies in drug discovery and healthcare. By training models on limited data from clinical trials or rare disease cases, few-shot learning could accelerate the development of life-saving treatments and enable more accurate diagnosis, ultimately improving patient outcomes.
Despite its immense potential, few-shot learning is not without its challenges. One of the primary hurdles is the risk of overfitting, where models become too specialized on the limited training data and fail to generalize effectively to new instances. Additionally, selecting the appropriate similarity measure or distance function is crucial for accurate performance, and task ambiguity or noisy data can further impede model effectiveness.
However, these challenges have only fueled a surge of research and innovation in the field. Approaches like meta-learning, metric learning, and transfer learning have emerged as promising strategies to enhance few-shot learning capabilities. Techniques such as Model-Agnostic Meta-Learning (MAML) and Prototypical Networks have demonstrated remarkable success in rapidly adapting to new tasks with minimal data.
As the field continues to evolve, we can expect even more sophisticated and robust few-shot learning methods to emerge, pushing the boundaries of what is possible with limited data. Ultimately, the true power of few-shot learning lies in its ability to democratize AI, making it accessible to domains and applications previously hampered by data scarcity, and ushering in a new era of data-efficient, adaptable, and inclusive artificial intelligence.
Few-shot learning represents a significant step forward in the field of machine learning, enabling us to extract insights from limited data. By understanding the various approaches and applications, junior data practitioners can leverage this powerful tool to tackle real-world problems across diverse domains.
As research continues, we can expect even more innovative and efficient few-shot learning techniques to emerge, further pushing the boundaries of data science.
If you’re keen on mastering other machine learning concepts, check out our Machine Learning Scientist with Python career track.
Keep Learning With DataCamp
track
course
track
blog
Karlijn Willems
12 min
blog
Kurtis Pykes
8 min
blog
Hugo Bowne-Anderson
7 min
tutorial
Lars Hulstaert
17 min
tutorial
Kurtis Pykes
13 min
tutorial
Joanne Xiong
11 min






