What is Llama 3? The Experts' View on The Next Generation of Open Source LLMs
Looking to get started with Generative AI?
Learn how to work with LLMs in Python right in your browser
What is Llama 3?
Llama 3 is a text-generation AI. That is, similar to OpenAI's GPT and Anthropic's Claude models, you write a text prompt, and it generates a text response. The latest models promise improved performance, particularly around better contextual understanding and logical reasoning. The Llama models are used to power Meta AI, a smart assistant included in Instagram, WhatsApp, Messenger and Facebook.
Llama 3 is an "open weights" model. That means that the model itself is open source, providing some transparency regarding how it makes calculations. Still, the full details to recreate it, such as the datasets used to train it, are not publicly available.

An image of 3 Llamas made with MidjourneyPrompt used “A cartoon of 3 llamas happily frolicking in a field”
New Capabilities of Llama3
Llama 3 is available in two sizes: an 8 billion parameter model and a 70 billion parameter model. In general, more parameters result in better quality of output but make the model slower and more expensive to run. 70 billion parameters is comparable to many competitor models, though there have been notable models with even larger parameter sizes. A third, larger model with 400 billion parameters was announced as being in development.
The context window—the amount of text that can be reasoned about at once—has been doubled from 4096 to 8192 tokens. A token refers to a single word or piece of punctuation, though some words are broken down into multiple tokens. In English, four tokens are about three words, so the new context window is about 15 pages of text (at 400 words per page). While the increase is welcome, it remains far from the cutting edge, with Claude 3 models offering a context window of 200,000 tokens.
Further features of the model were not described in the announcement article. Instead, much of the focus was on the surrounding ecosystem of software.
Llama 3 Ecosystem
Alongside the announcement of Llama3, Meta announced a suite of tools to make working with Llama easier and safer. Here’s an overview.
Llama Guard 2
Llama Guard 2 is an LLM tool for classifying text as "safe" or "unsafe." It can be used for both prompts and responses. For example, it can detect whether text contains descriptions of violence, hate speech, or other unsavory content.
An example use case is a chatbot. You can check each prompt, and if the content is flagged as unsafe, you then provide a warning or other method of dealing with the problematic content. Similarly, if the chatbot generates a response flagged as unsafe, you can intercept it and try again before the user sees it.
In addition to the safe/unsafe flag, the responses from Llama Guard 2 are tagged with a safety label—one of eleven categories of unsavory content from the MLCommons AI Safety Taxonomy.
Llama Code Shield
Llama Code Shield classifies code as secure or insecure. With many software developers making use of LLMs to assist them in writing code, there is a risk that insecure code is generated and included in production. The tool is designed to be incorporated into AI coding assistants and integrated into other tools like VSCode and DataLab.
CyberSec Eval 2
CyberSec Eval 2 lets you evaluate how safe an LLM is. The original CyberSec Eval lets you evaluate the safety of code generation and cyber attack protection. The latest version builds on this, with features for assessing susceptibility to prompt injection, automated offensive cybersecurity capabilities, and propensity to abuse a code interpreter.
torchtune
torchtune is a Python package that works alongside the PyTorch deep learning framework to make it easy to develop your own LLMs. There are tools for four tasks.
- Creating new models from building blocks based on existing LLMs
- Fine-tuning LLMs using techniques like LoRA and QLoRA
- Configuring settings for training, quantization, and evaluation of the models
- Prompt templates and dataset integration for more accessible training
torchtune is integrated with popular machine learning platforms such as Hugging Face, Weights & Biases, EleutherAI, and Executorch.
What are the Use Cases of Llama 3?
The use cases of Llama 3 are the same as those of Llama 2 and other LLMs. Common uses include the following.
- Chatbots: Automating customer service, support, and engagement through conversational agents.
- Document Summarization: Condensing long documents into shorter versions highlighting key points, useful in legal, academic, and business contexts.
- Content Creation: Generating articles, reports, blogs, and even creative writing like poetry and stories.
- Email and Communication Assistance: Automating the drafting of emails, responses, and other routine communications.
- Product Descriptions: Automatically generating unique and engaging product descriptions for e-commerce websites.
- Educational Tools: Creating study guides, exam questions, and educational content customized to students’ learning levels.
- Programming and Code Generation: Assisting developers by generating code snippets, debugging existing code, or providing programming recommendations.
- Data Analysis Reports: Summarizing data findings and generating reports from structured data inputs.
- Virtual Assistants: Powering personal assistant apps that manage schedules, answer questions, and perform tasks.
How Does Llama 3's Performance Compare?
The Meta announcement shows benchmark results for the eight billion (8B) and seventy billion (70B) parameter versions of Llama 3 against two other models.
The following benchmarks were used.
- Massive Multitask Language Understanding (MMLU). Tasks on elementary mathematics, US history, computer science, law, and more. To attain high accuracy on this test, models must possess extensive world knowledge and problem-solving ability.
- Graduate-Level Google-Proof Q&A (GPQA). Multiple-choice questions written by domain experts in biology, physics, and chemistry. The questions are high-quality and extremely difficult: experts who have or are pursuing PhDs in the corresponding domains reach 74% accuracy.
- HumanEval. A test of the functional correctness of computer code, used for checking code generation.
- GSM-8K. High-quality linguistically diverse grade school math word problems.
- MATH. Middle school and high school mathematics problems.
The Llama 3 8B model was benchmarked against Google's Gemma 7B It and Mistral 7B Instruct. These are comparably sized LLMs (similar number of parameters), are open weights models available on the Hugging Face platform, and are intended for similar use cases. The results are shown in Figure 1.
Llama 3 8B comfortably outperforms the other two models on all five benchmarks.
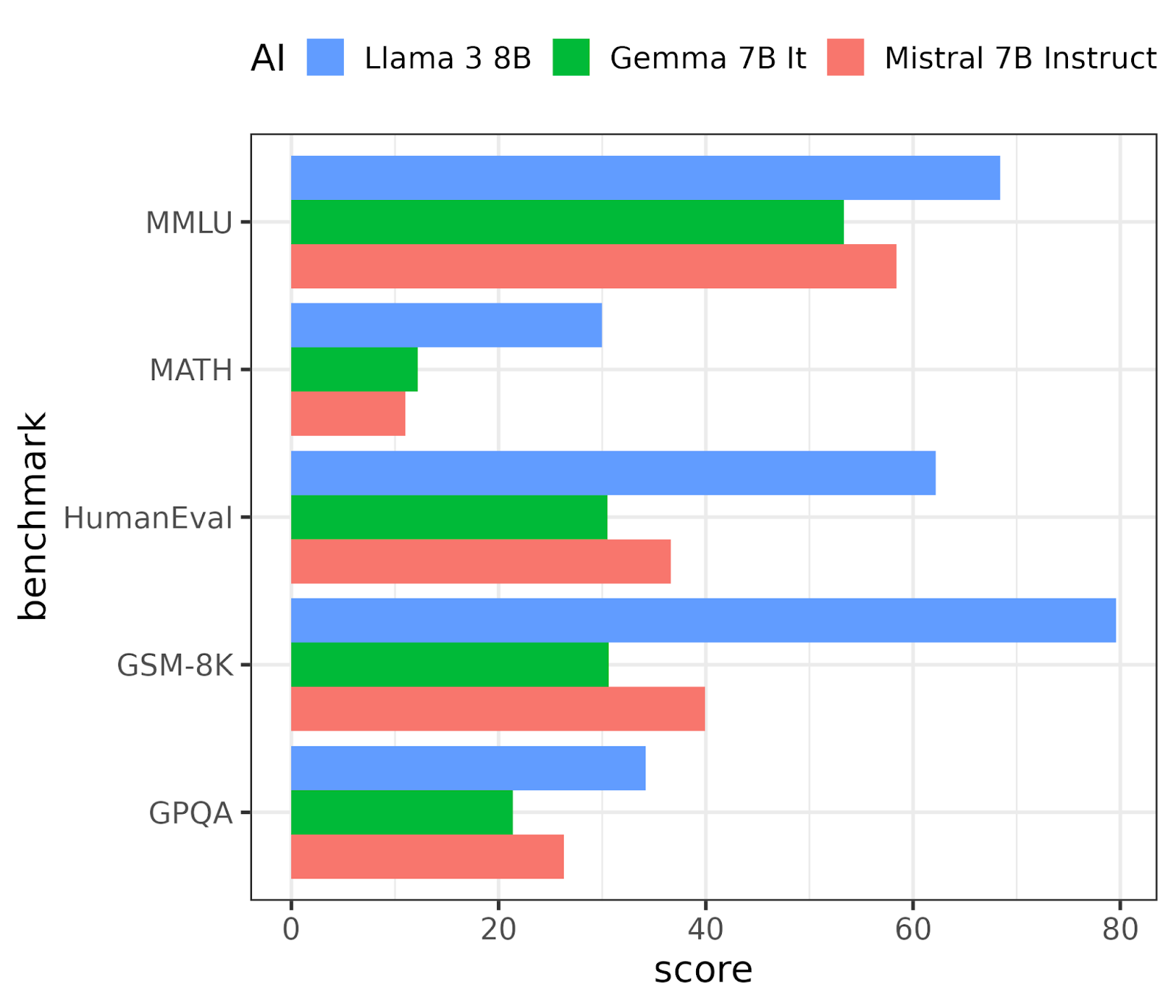
Figure 1. The performance of Llama 3 8B against two comparable models on 5 LLM benchmarks.
Llama 3 70B was benchmarked against Google DeepMind's Gemini Pro 1.5 and Anthropic's Claude 3 Sonnet. These are close to cutting-edge models, though not the highest-performing models available (that honor is currently being passed back and forth between OpenAI's GPT-4 Turbo or Anthropic's Claude 3 Opus). The results are shown in Figure 2.
Here, the performance is pretty much tied on three of the benchmarks. Llama 3 80B wins on the HumanEval benchmark for generating code and is second to Gemini Pro 1.5 on the MATH benchmark.
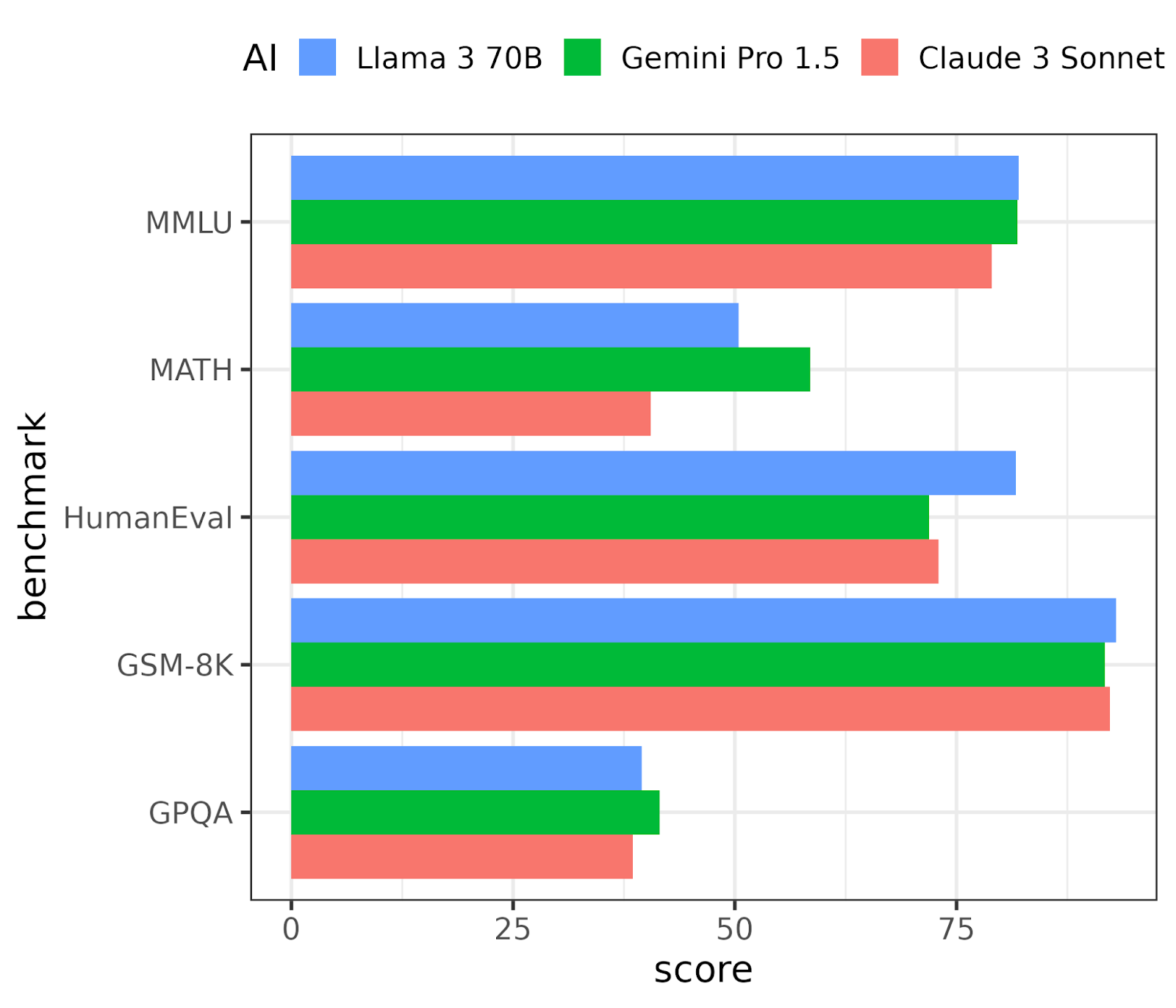
Figure 2. The performance of Llama 3 70B against two comparable models on 5 LLM benchmarks.
Interpreting the benchmark results
There are more than five benchmarks: Llama 3 was benchmarked on 15 of them, but only the results for five were displayed in the announcement. Similarly, there are a lot more choices of LLMs to compare against. It is unclear how much cherry-picking was done by Meta when presenting the results.
Secondly, quality of output is only one measure of performance. The time and cost to generate responses are also important and not covered in the announcement.
Thirdly, performance will always vary by use case, so you need to try it on your own problems with your own hardware to get accurate results for your use cases.
Chatbot Arena Rankings
In the days since the Meta announcement, Llama 3 performance has shown up on the LMSYS Chatbot Arena Leaderboard, a public ranking of LLMs. Llama 3 70B is currently ranked 6th, the highest ranking of any open weights LLM. (It trails various versions of OpenAI GPT-4, Anthropic Claude 3 Opus, and Google Gemini Pro.) Meanwhile, Llama 3 8B is in 14th place.
These are noteworthy jumps in rankings, and it's worth exploring what has changed since Llama 2.
How Does Llama 3 Work?
Llama 3 uses a decoder-only transformer architecture, like its predecessors and the GPT series of models. This is the most common architecture for models that generate text. (The opposite type, encoder-only architectures, are used for understanding or classifying text provided by the user.)
The Llama 3 announcement describes no radical changes to the model structure or training process. Instead, there are many optimizations around the tradeoffs between quality of response, speed of response, and development.
A new tokenizer, used to convert text into tokens, is more efficient, so prompts and responses take up 15% fewer tokens, meaning more text can fit into the context window.
A new attention mechanism—the technique LLMs use to decide which words or phrases are essential for generating the output—called grouped query attention, provides a better tradeoff for output quality versus speed of generation compared to previous mechanisms.
The training dataset is seven times larger than the one used for Llama 2, containing four times as much code. In general, having more code in the training data means that LLMs will be better at generating code.
Interestingly, the Llama 2 model was used to evaluate and classify data for inclusion in the Llama 3 training set. The use of AI to create an even better AI is a longstanding science fiction staple (it's a plot point in the Hitchhiker's Guide to the Galaxy) and is now being put into practice.
The post-training process also has been optimized. After an LLM is created, that "raw" LLM can be tuned to improve its performance. Meta notes that the Llama 3 process includes the following techniques.
- Supervised fine-tuning, a supervised machine learning technique where pairs of prompts and a high-quality answer are used to provide examples of good output.
- Rejection sampling, where several outputs are generated and ranked, and the worst ones are rejected.
- Direct Policy Optimization and Proximal Policy Optimization reinforcement learning techniques where the model is given a reward for good responses.
What wasn't included?
There were some notable absences from this release.
No Multimodal AI
OpenAI's ChatGPT combines the GPT-4 text AI with the DALL∙E 3 image AI. That is, it is "multimodal". The Meta announcement suggests that making Llama 3 multimodal is a goal for the near future.
No Multilingual AI
The Llama 3 dataset is described as containing 95% English language text. That means that performance is expected to be much weaker for other languages. As with multimodal AI, a multilingual version of Llama 3 is on the roadmap.
No Mixture of Experts
One technique not mentioned in the announcement was using a mixture of experts' architecture. With this technique, an LLM consists of several smaller LLMs specializing in narrower tasks (for example, a code generation LLM, a document summarization LLM, and a dialog LLM). It was popularized by Mistral AI's Mixtral models and is rumored to be the basis of OpenAI's GPT-4, which provides better performance per parameter. That is, you can get the same performance with a smaller (and therefore cheaper and faster) model by using this technique. Since Meta does not mention this technique (and there is no mention of it in the Llama 3 GitHub repository), we can assume that the method was not used.
No World Model
Meta's Chief AI Scientist, Yann LeCun, has been a strong proponent of world models, where the AI develops an internal model of how the world works to learn quicker, accomplish complex tasks, and adapt to unfamiliar situations. There was no mention of this radical architecture in the announcement, so it appears not to be present in Llama 3.
Where Can I Access Llama 3?
Llama 3 is available for download from its website and its GitHub repository. It is already powering the Meta AI assistant in Facebook, Instagram, WhatsApp, and Messenger, so you can implicitly try Llama 3 by using Meta AI on those platforms.
Integrations with AWS, Databricks, Google Cloud, Hugging Face, Kaggle, IBM WatsonX, Microsoft Azure, NVIDIA NIM, and Snowflake are promised as "available soon," allowing you to access Llama 3 via those platforms.
Does Llama 3 Matter?
At the high end of performance, the recent story of the large language model landscape has been one of OpenAI's GPT-4 and Anthropic's Claude 3 Opus battling for supremacy, with Google Gemini Pro and Cohere's Command R+ in hot pursuit. It remains to be seen whether the in-development larger-sized version of Llama 3 will be a contender for the crown, but in the meantime, Meta has achieved substantial performance improvements in Llama 3.
In the last few years, closed models (where details of the model are unavailable to the public) have outperformed more open models. The fact that Llama 3 has placed 6th in the rankings is, therefore, a big deal.
Meta's main short-term goal for Llama is simply to power the Meta AI smart assistant for its social media platforms. This is a very different business model to OpenAI, Anthropic, or Cohere, who want to sell their LLM to use in other companies' AI products. In this respect, performance benchmarks for generating code or solving math problems may not matter much to the company.
Meta has a unique training dataset of the social posts created by its billions of users, and—bragging rights aside—the only performance metric that matters is "Does LLama 3 sufficiently cater to the needs of social media users?"
Beyond this, the open weights approach means that Llama 3 is potentially cheaper to run than the competition. By essentially giving away the AI, it puts downward pressure on the prices its competitors can charge for their APIs. This is important, as the heady optimism of 2023 and dreams of ever-increasing generative AI performance have given way to a more sober 2024 when executives have started noticing just how expensive LLM features are, and performance per dollar has become high on the priority list.
Open weights models are also important in situations where data privacy is paramount, for example, when using financial data, healthcare data, or personally identifiable information. Passing such highly sensitive data to an LLM hosted by another company (as is the case with GPT and the other closed models) incurs a business risk that most companies are not willing to take. This means using a more convoluted architecture for a chatbot or other AI feature in order to separate the sensitive data from the LLM. An open weights model like Llama 3 can be hosted wherever the organization likes, making it easier to create AI products and features while retaining data privacy.
Closing Notes
Llama 3 appears to be an iterative improvement over Llama 2. No significant changes were announced to the architecture, and no major features were announced.
The focus on cost-performance tradeoffs suggests that Meta is aiming for an AI that can be run cheaply at scale. The most exciting news was around the ecosystem products: helping other developers create high-quality LLMs more efficiently is one of the most important benefits of Meta's open approach.
If you’re eager to get started in the world of generative AI, our AI Fundamentals skill track will help you get up to speed with machine learning, deep learning, NLP, generative models, and more.
Looking to get started with Generative AI?
Learn how to work with LLMs in Python right in your browser
Is Llama3 Open Source?
Is Llama3 Free or Paid?
Is Llama3 Multimodal?
blog
Introduction to Meta AI’s LLaMA

Abid Ali Awan
8 min


blog
8 Top Open-Source LLMs for 2024 and Their Uses

Javier Canales Luna
13 min

blog
What is an LLM? A Guide on Large Language Models and How They Work
Javier Canales Luna
12 min
tutorial
How to Run Llama 3 Locally: A Complete Guide
Abid Ali Awan
15 min
tutorial
Llama.cpp Tutorial: A Complete Guide to Efficient LLM Inference and Implementation

Zoumana Keita
11 min
tutorial
Fine-Tuning Llama 3 and Using It Locally: A Step-by-Step Guide
Abid Ali Awan
19 min