

course
Generative AI Concepts
2 hours
25.6K
Large language models (LLMs) are revolutionizing various industries. From customer service chatbots to sophisticated data analysis tools, the capabilities of this powerful technology are reshaping the landscape of digital interaction and automation.
However, practical applications of LLMs can be limited by the need for high-powered computing or the necessity for quick response times. These models typically require sophisticated hardware and extensive dependencies, which can make difficult their adoption in more constrained environments.
This is where LLaMa.cpp (or LLaMa C++) comes to the rescue, providing a lighter, more portable alternative to the heavyweight frameworks.

Llama.cpp logo (source)
Learn to build AI applications using the OpenAI API.
LLaMa.cpp was developed by Georgi Gerganov. It implements the Meta’s LLaMa architecture in efficient C/C++, and it is one of the most dynamic open-source communities around the LLM inference with more than 390 contributors, 43000+ stars on the official GitHub repository, and 930+ releases.
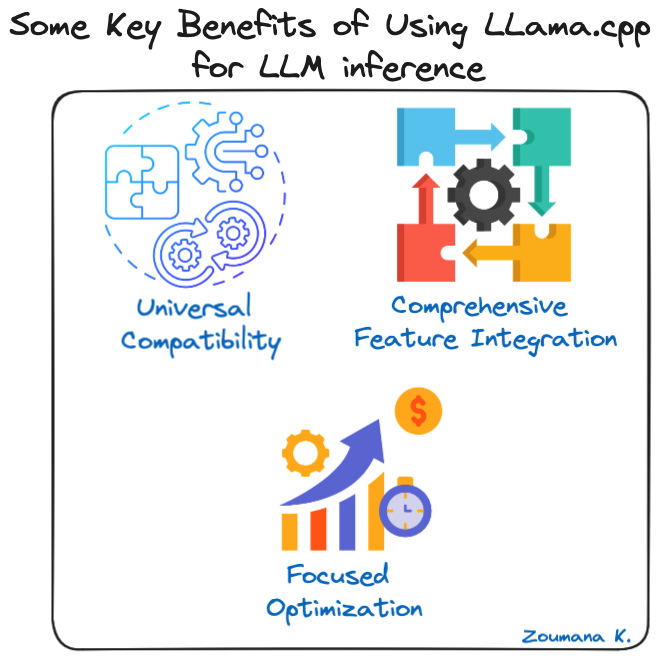
Some key benefits of using LLama.cpp for LLM inference
With this understanding of Llama.cpp, the next sections of this tutorial walks through the process of implementing a text generation use case. We start by exploring the LLama.cpp basics, understanding the overall end-to-end workflow of the project at hand and analyzing some of its application in different industries.
Llama.cpp’s backbone is the original Llama models, which is also based on the transformer architecture. The authors of Llama leverage various improvements that were subsequently proposed and used different models such as PaLM.
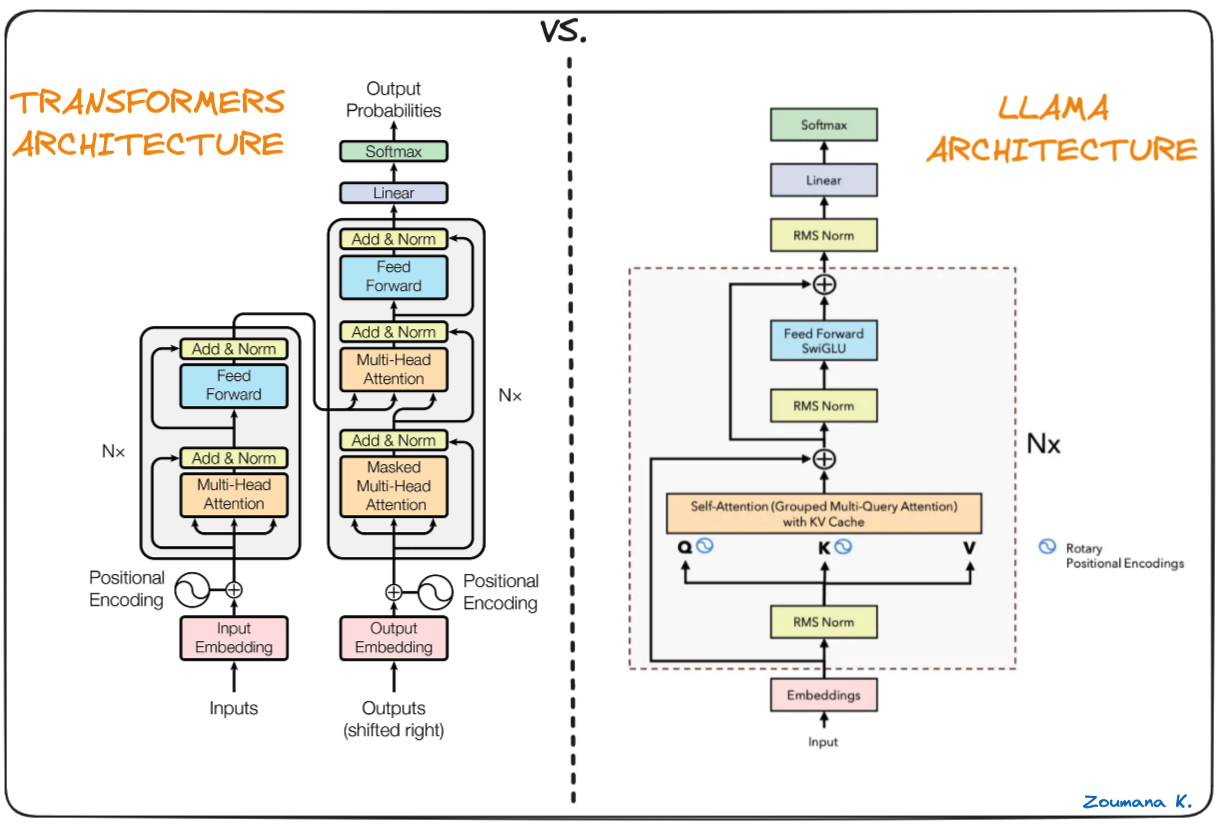
Difference between Transformers and Llama architecture (Llama architecture by Umar Jamil)
The main difference between the LLaMa architecture and the transformers’:
The prerequisites to start working with LLama.cpp include:
Python: to be able to run the pip, which is the Python package managerLlama-cpp-python: the Python binding for llama.cppIt is recommended to create a virtual environment to avoid any trouble related to the installation process, and conda can be a good candidate for the environment creation.
All the commands in this section are run from a terminal. Using the conda create statement, we create a virtual environment called llama-cpp-env.
conda create --name llama-cpp-envAfter successfully creating the virtual environment, we activate the above virtual environment using the conda activate statement, as follows from:
conda activate llama-cpp-envThe above statement should display the name of the environment variable between brackets at the beginning of the terminal as follows:

Name of the virtual environment after activation
Now, we can install the Llama-cpp-python package as follows:
pip install llama-cpp-python
or
pip install llama-cpp-python==0.1.48The successful execution of the llama_cpp_script.py means that the library is correctly installed.
To make sure the installation is successful, let’s create and add the import statement, then execute the script.
from llama_cpp import Llama to the llama_cpp_script.py file, thenllama_cpp_script.py to execute the file. An error is thrown if the library fails to import; hence, it needs further diagnosis for the installation process.At this stage, the installation process should be successful, and let’s dive into understanding the basics of LLama.cpp.
The Llama class imported above is the main constructor leveraged when using Llama.cpp, and it takes several parameters and is not limited to the ones below. The complete list of parameters is provided in the official documentation:
model_path: The path to the Llama model file being usedmax_tokens: The maximum number of tokens to be generated in the model’s responseFor instance, let’s consider that we want to use a large language model called <MY_AWESOME_MODEL> stored in the current working directory, the instantiation process will look like this:
# Instanciate the model
my_aweseome_llama_model = Llama(model_path="./MY_AWESOME_MODEL")
prompt = "This is a prompt"
max_tokens = 100
temperature = 0.3
top_p = 0.1
echo = True
stop = ["Q", "\n"]
# Define the parameters
model_output = my_aweseome_llama_model(
prompt,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
echo=echo,
stop=stop,
)
final_result = model_output["choices"][0]["text"].strip()The code is self-explanatory and can be easily understood from the initial bullet points stating the meaning of each parameter.
The result of the model is a dictionary containing the generated response along with some additional metadata. The format of the output is explored in the next sections of the article.
Now, it is time to get started with the implementation of the text generation project. Starting a new Llama.cpp project has nothing more than following the above python code template that explains all the steps from loading the large language model of interest to generating the final response.
The project leverages the GGUF version of the Zephyr-7B-Beta from Hugging Face. It is a fine-tuned version of the mistralai/Mistral-7B-v0.1 that was trained on on a mix of publicly available, synthetic datasets using Direct Preference Optimization (DPO).
Our An Introduction to Using Transformers and Hugging Face provides a better understanding of Transformers and how to harness their power to solve real-life problems. We also have a Mistral 7B tutorial.
Zephyr model from Hugging Face (source)
Once the model is downloaded locally, we can move it to the project location in the model folder. Before diving into the implementation, let’s understand the project structure:

The structure of the project
The first step is to load the model using the Llama constructor. Since this is a large model, it is important to specify the maximum context size of the model to be loaded. In this specific project, we use 512 tokens.
from llama_cpp import Llama
# GLOBAL VARIABLES
my_model_path = "./model/zephyr-7b-beta.Q4_0.gguf"
CONTEXT_SIZE = 512
# LOAD THE MODEL
zephyr_model = Llama(model_path=my_model_path,
n_ctx=CONTEXT_SIZE)Once the model is loaded, the next step is the text generation phase, by using the original code template, but we use a helper function instead called generate_text_from_prompt.
def generate_text_from_prompt(user_prompt,
max_tokens = 100,
temperature = 0.3,
top_p = 0.1,
echo = True,
stop = ["Q", "\n"]):
# Define the parameters
model_output = zephyr_model(
user_prompt,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
echo=echo,
stop=stop,
)
return model_outputWithin the __main__ clause, the function can be executed using a given prompt.
if __name__ == "__main__":
my_prompt = "What do you think about the inclusion policies in Tech companies?"
zephyr_model_response = generate_text_from_prompt(my_prompt)
print(zephyr_model_response)The model response is provided below:

The model’s response
The response generated by the model is <What do you think about the inclusion policies in Tech companies?> and the exact response of the model is highlighted in the orange box.
Even though this complete output can be useful for further use, we might be only interested in the textual response of the model. We can format the response to get such a result by selecting the “text” field of the “choices” element as follows:
final_result = model_output["choices"][0]["text"].strip()
The strip() function is used to remove any leading and trailing whitespaces from a string and the result is:
Tech companies want diverse workforces to build better products.This section walks through a real-world application of LLama.cpp and provides the underlying problem, the possible solution, and the benefits of using Llama.cpp.
Imagine ETP4Africa, a tech startup that needs a language model that can operate efficiently on various devices for their educational app without causing delays.
They implement Llama.cpp, taking advantage of its CPU-optimized performance and the ability to interface with their Go-based backend.
The integration of Llama.cpp allows ETP4Africa app to offer immediate, interactive programming guidance, improving the user experience and engagement.
Data Engineering is a key component to any Data Science and AI project, and our tutorial Introduction to LangChain for Data Engineering & Data Applications provides a complete guide for including AI from large language models inside data pipelines and applications.
In summary, this article has provided a comprehensive overview on setting up and utilizing large language models with LLama.cpp.
Detailed instructions were provided for understanding the basics of Llama.cpp, setting up the working environment, installing the required library, and implementing a text generation (question-answering) use case.
Finally, Practical insights were provided for a real-world application and how Llama.cpp can be used to efficiently tackle the underlying problem.
Ready to dive deeper into the world of large language models? Enhance your skills with the powerful deep learning frameworks LangChain and Pytorch used by AI professionals with our How to Build LLM Applications with LangChain tutorial and How to Train a LLM with PyTorch.
Start Your AI Journey Today!
course
track
course
tutorial
Abid Ali Awan
15 min
tutorial
Abid Ali Awan
12 min
tutorial
Abid Ali Awan
19 min
tutorial
Abid Ali Awan
14 min
tutorial
Abid Ali Awan
10 min
code-along
Maxime Labonne

