
Track
Data Engineer
57hrs hr
My exposure to big data started 10+ years ago as a software engineer working in Ad-Tech. Back then, datasets started to grow fast and explode in size.
At the same time, this was a big opportunity but also a challenge.
Queries to answer basic but critical reporting questions suddenly took hours. As a response, I started leveraging column-oriented databases such as BigQuery in 2013.
These cloud-based databases allowed us to run analytical loads performantly and cost-effectively and to scale resources if needed.
In the last few years, I led a large team of data engineers that built a 10+ PB BigQuery data warehouse to keep up with a fast-growing catalog of home goods products and growing analytical needs.
Now, as the CTO of DataCamp, I lead different engineering and content teams to drive and allow our users to learn and practice exactly these skills (among many others). I am convinced that cloud data warehouses like BigQuery can make many workflows much more efficient and robust. That's why I want to share my experiences with you in this tutorial.
In this guide, you'll learn what BigQuery is, how it works, and its differences from traditional data warehouses. You will learn how to use the BigQuery console to query public datasets provided by Google with a practical example of how to query Google Trends to learn about popular topics.
BigQuery is a fully managed data warehouse developed by Google that helps manage and analyze data. The tool’s serverless architecture enables organizations to get insights into their business and answer questions quickly. BigQuery’s scalable and distributed analytical engine also lets users query petabytes of data using SQL.
BigQuery interfaces include the Google Cloud console interface and the BigQuery command-line tool. In addition, it provides developers with client libraries for popular languages such as C#, Go, Java, Node.js, PHP, Python, and Ruby.
BigQuery provides built-in machine-learning capabilities and allows the use of externally trained models in Google Cloud Platform (GCP) VertexAI and even importing custom models trained outside BigQuery.
This tutorial is appropriate for data analysts, data engineers, and data warehouse administrators as an introduction to BigQuery. If after this tutorial you'd like to go deeper with BigQuery, our introduction to BigQuery course is a good place to start.
A traditional data warehouse is deployed on-premise, typically requiring high upfront costs, a skilled team to manage it, and proper planning to meet increasing demand due to the rigid nature of traditional data center resource scaling.
On the other hand, a cloud data warehouse solution is managed and hosted by a cloud services provider.
Typically, a cloud data warehouse has several advantages over traditional data warehouses:
Example of a row-oriented database:

Example of a column-oriented database:
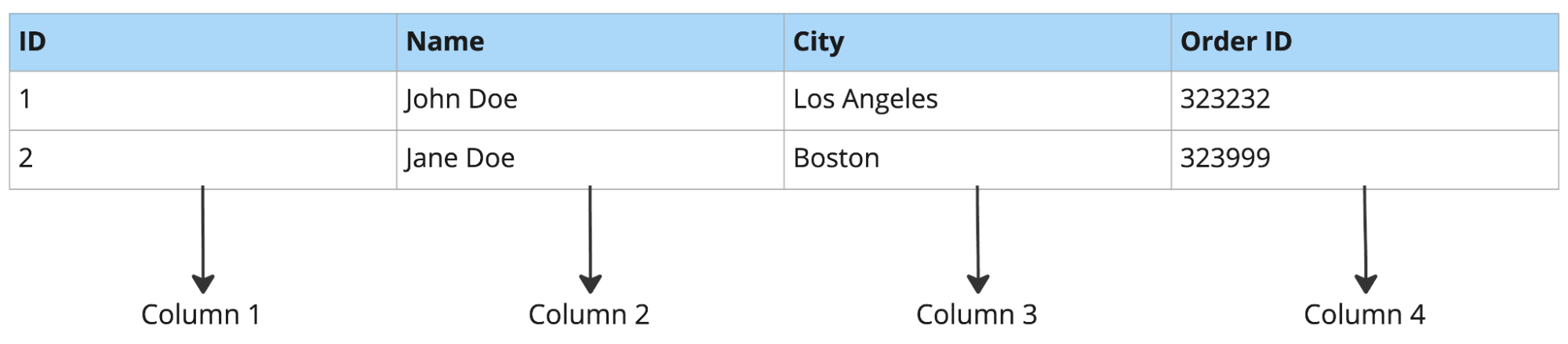
Row-oriented databases are well suited to workloads with full row lookups, insertion of new records, and manipulation. Conversely, this makes them poorly suited for analytical workloads. For example, querying a few columns from a table with dozens of columns would result in reading a large amount of unnecessary data (this is common in analytical workloads, such as product forecasting, ad-hoc analysis, and more).
Row-oriented databases are typically well suited for online transaction processing (OLTP), and column-oriented databases for online analytical processing (OLAP).
Summary of comparison:
|
Row-oriented database |
Column-oriented database |
||||||
|
Storage |
By Row |
By Column |
|||||
|
Data retrieval |
Complete records |
Revelant columns |
|||||
|
Typical application |
OLTP |
OLAP |
|||||
|
Fast operations |
Insertion, Updates, Lookups |
Querying for reporting purposes |
|||||
|
Load data |
Typically a record at a time |
Typically in batch |
|||||
|
Popular options |
Postgres, MySQL, Oracle, Microsoft SQL Server |
Snowflake, Google BigQuery, Amazon Redshift |
|||||
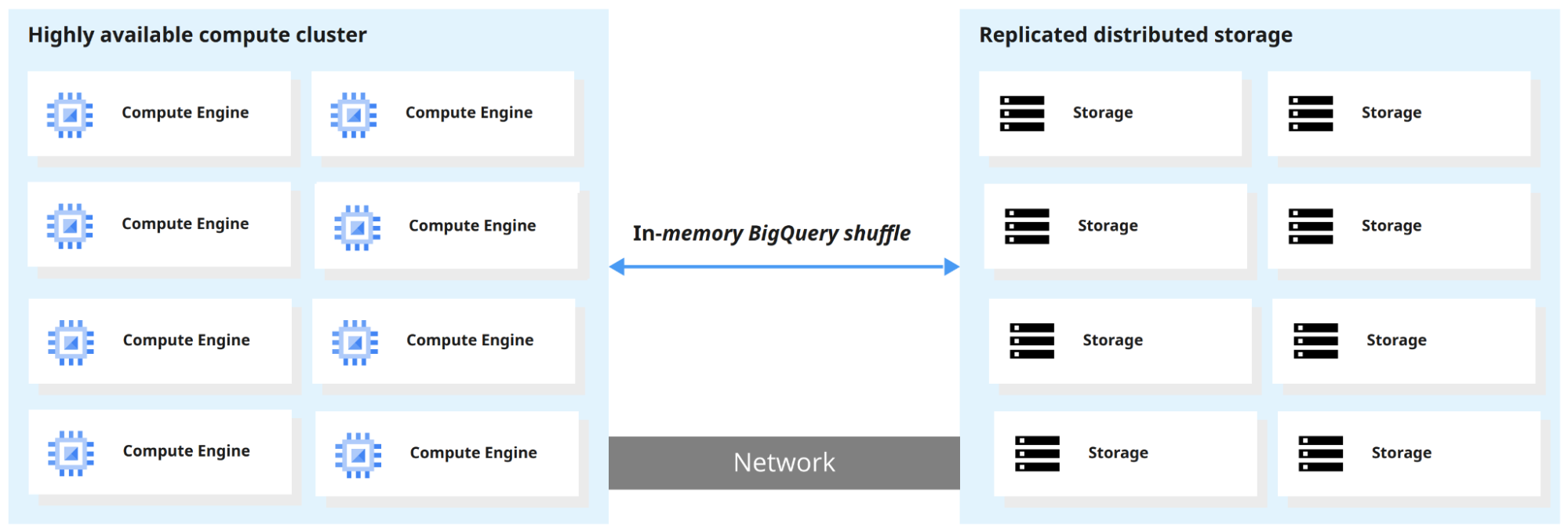
One of the key features of BigQuery is the separation of compute engine and storage so both can be scaled separately, as needed and on demand. This enables users to query terabytes of data in seconds and petabytes in minutes.
When BigQuery runs a query, the query engine distributes the work in parallel, scanning the relevant tables in storage, merging results, and returning the final data set.
In this section, we will cover how to access BigQuery and how to use BigQuery sandbox. Typically, a sandbox is a testing environment that is isolated and enables easy experimentation. The BigQuery sandbox lets you experience BigQuery without providing a credit card or creating a billing account for your project.
BigQuery can be accessed through Google Cloud Console. You will need to log in with a Gsuite email account (or create one). Once logged a welcome screen should appear:
You can find BigQuery in the left menu bar. Clicking on it will take you to the screen below:
In order to use BigQuery sandbox, first create a project, clicking on ‘Select Project.’
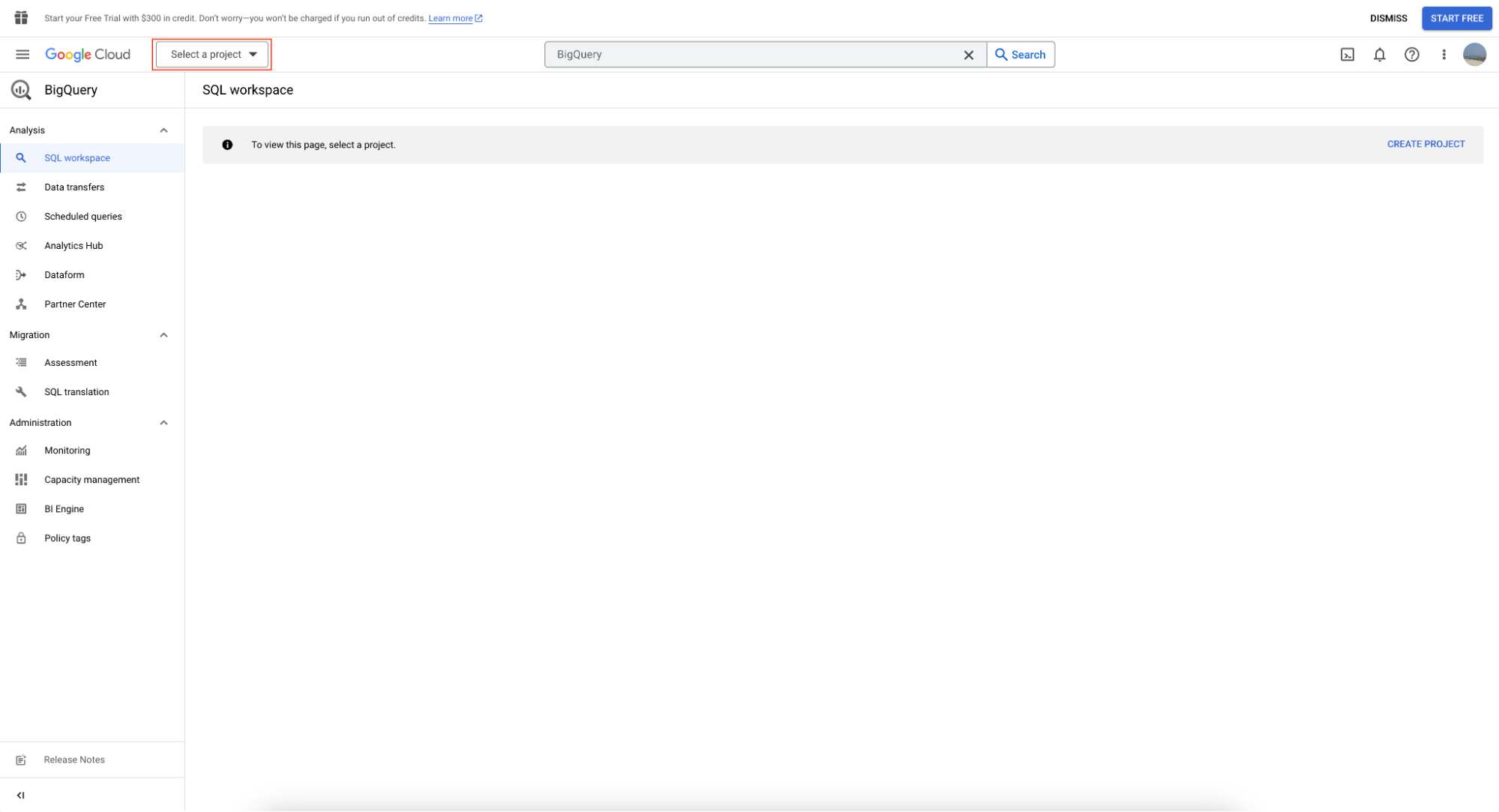
Followed by clicking on ‘New Project’:
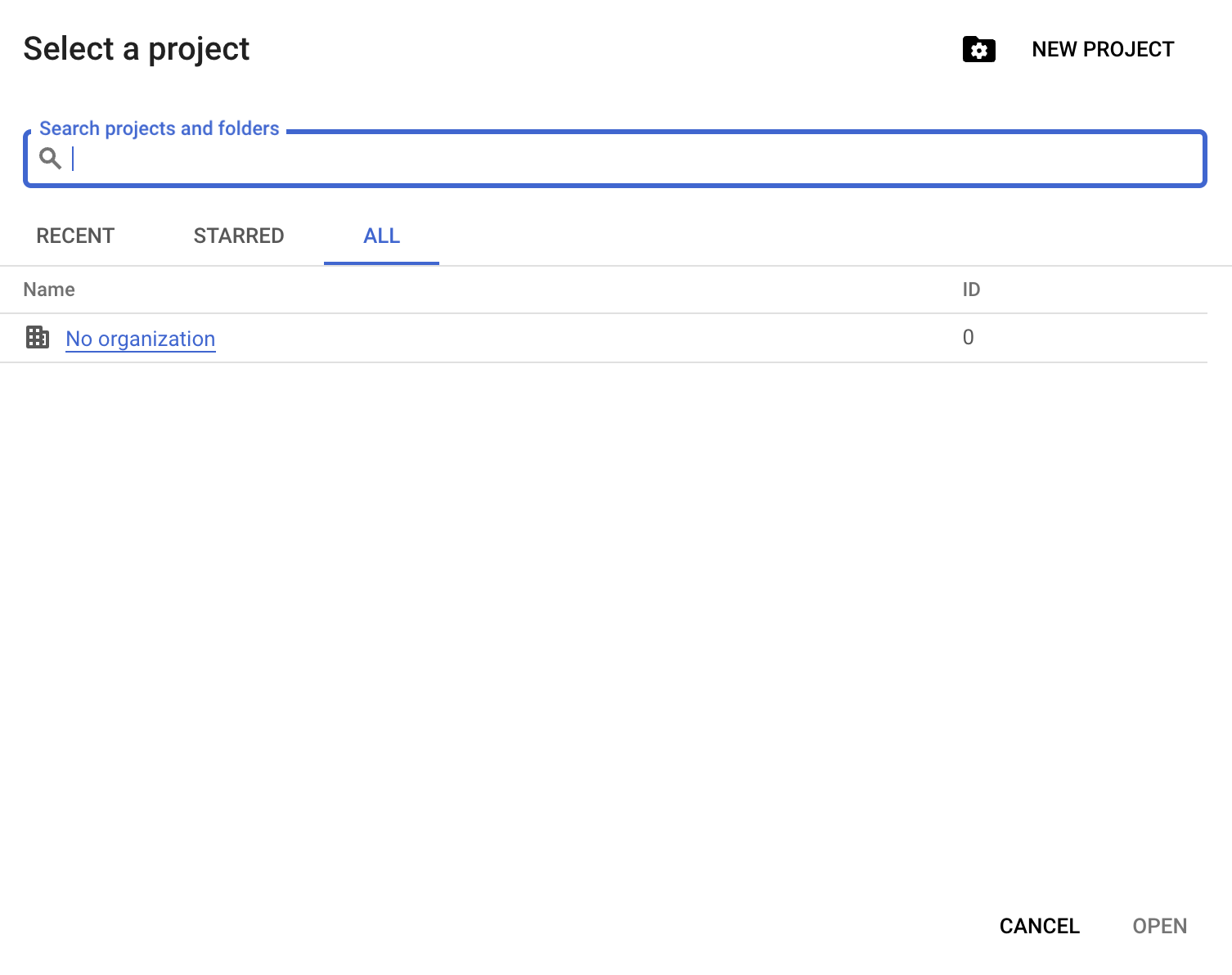
You’ll need to provide a project name; for this guide, we’re using datacamp-guide-project

A sandbox notice is now displayed on the BigQuery page, showing you have successfully enabled the BigQuery sandbox.

With the BigQuery sandbox now enabled, you can use your new project to load data and query as well as query Google public datasets.
Before creating a table, you need to create a dataset in your new project. A dataset is a top-level container used to organize and control access to a set of tables and views. To create a dataset, click on the project’s ‘Actions’ icon:
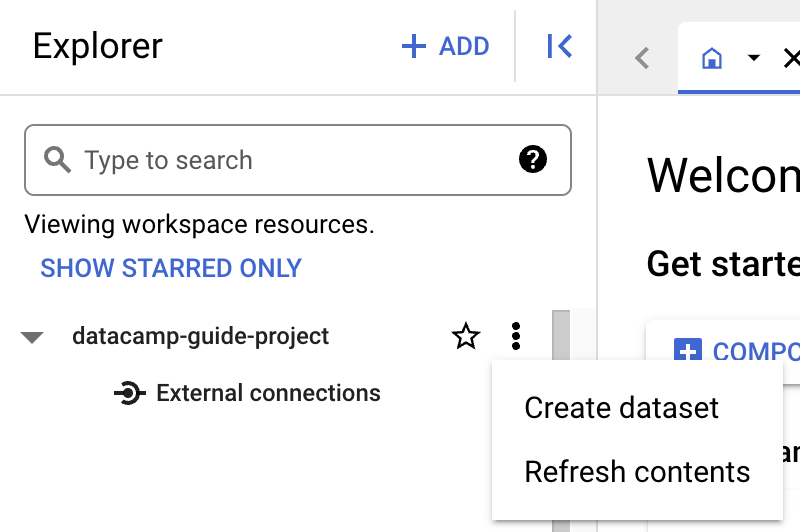
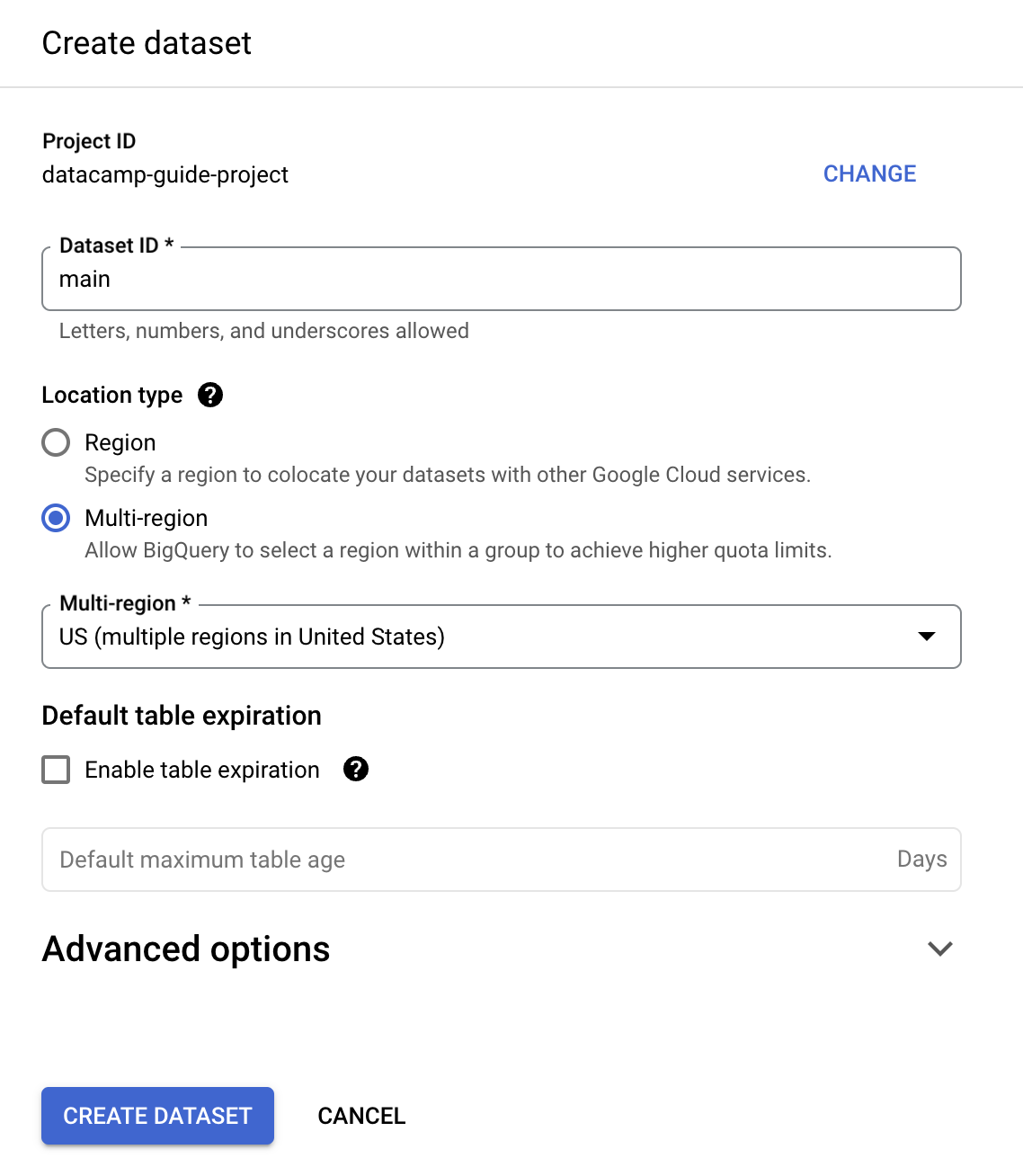
For the purpose of this guide, we’ll fill in ‘Dataset ID’ with ‘main’.
You can create a table using SQL. BigQuery uses GoogleSQL, which is ANSI compliant.
create table `datacamp-guide-project.main.users` (
id INT64 not null,
first_name STRING NOT NULL,
middle_name STRING, -- can be null
last_name STRING NOT NULL,
active_account BOOL NOT NULL,
);
You can also use the BigQuery Console interface:
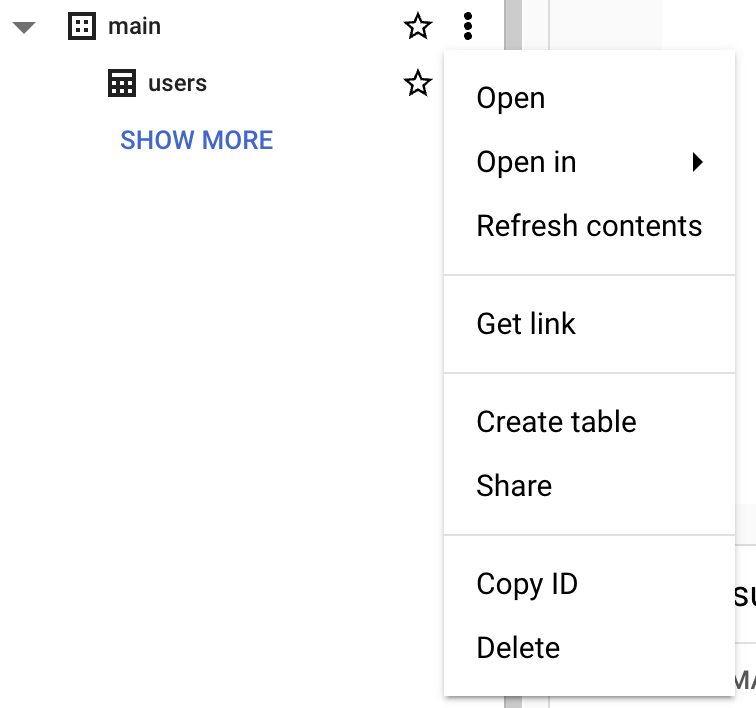
Note: It is not possible to insert data while in a sandbox environment. If you want to try inserting data, you need to enable the free trial. The next sections focus on querying public datasets provided as part of Google Cloud.
To query a public dataset follow the steps below:
1. Click ‘Add’ next to Explorer.

2. Then, choose a dataset.
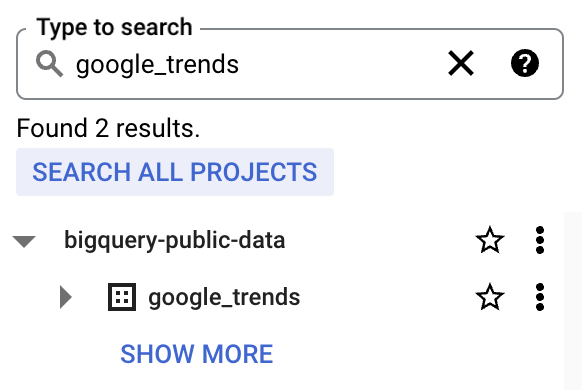
3. Search for ‘Google Trends’ and choose Google Trends, followed by clicking the ‘View dataset’ button.

4. bigquery-public-data will show up with a long list of datasets. Star bigquery-public-data so that it becomes “stick” in the explorer
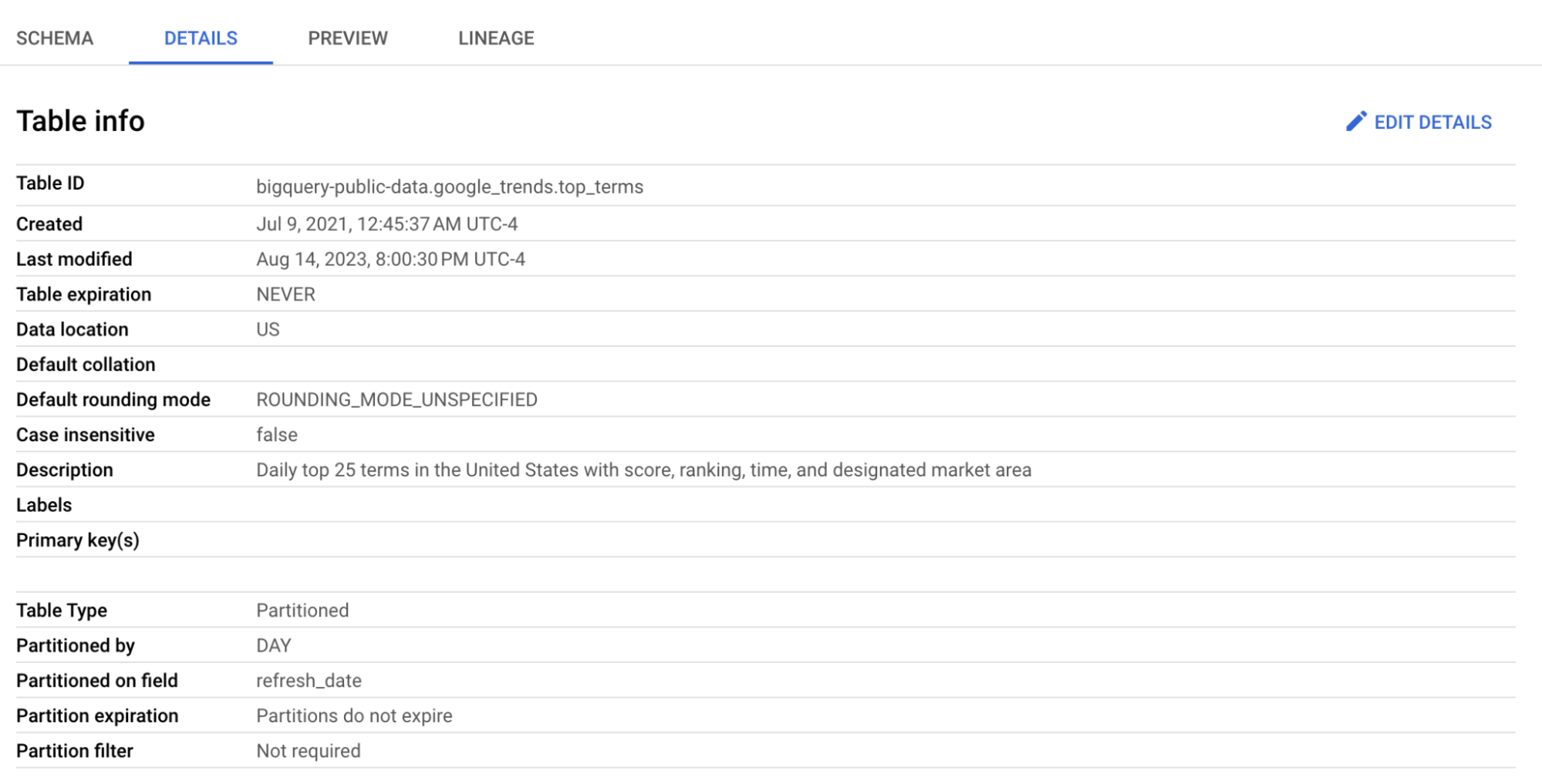
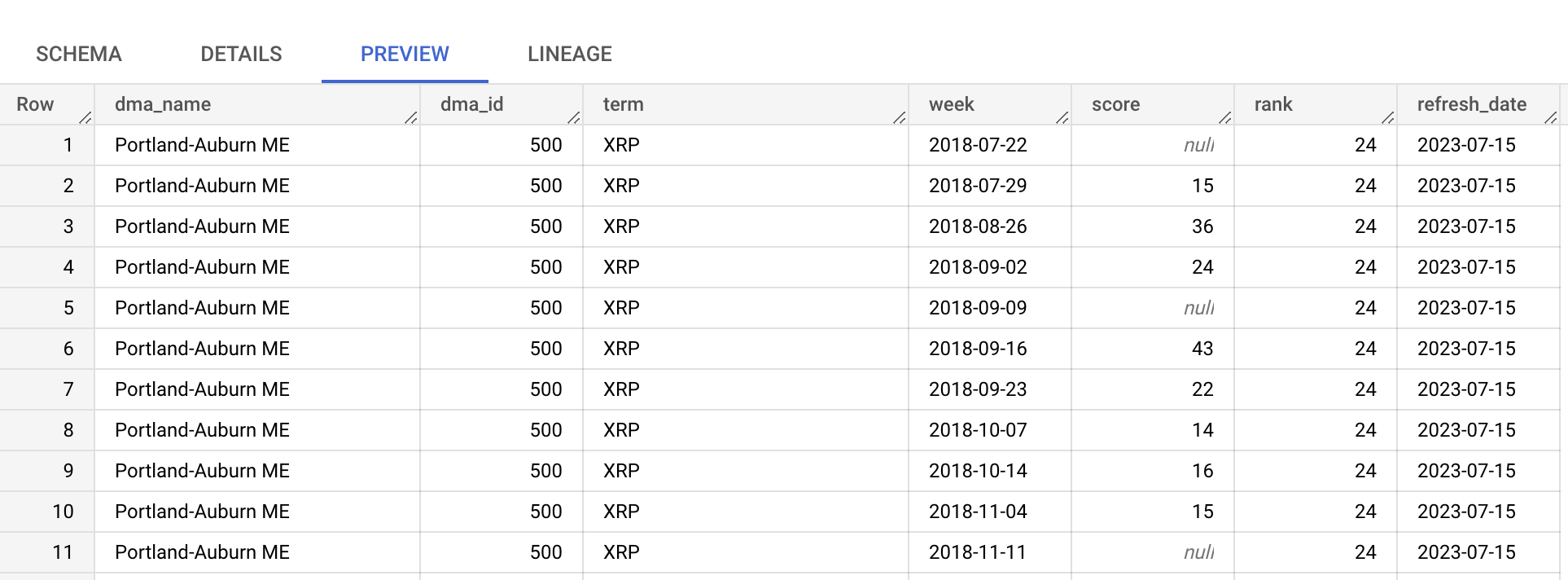
We will leverage the table top_terms:

Click the top_terms table to open, and inspect the Details and Preview table to learn more about top_terms data.
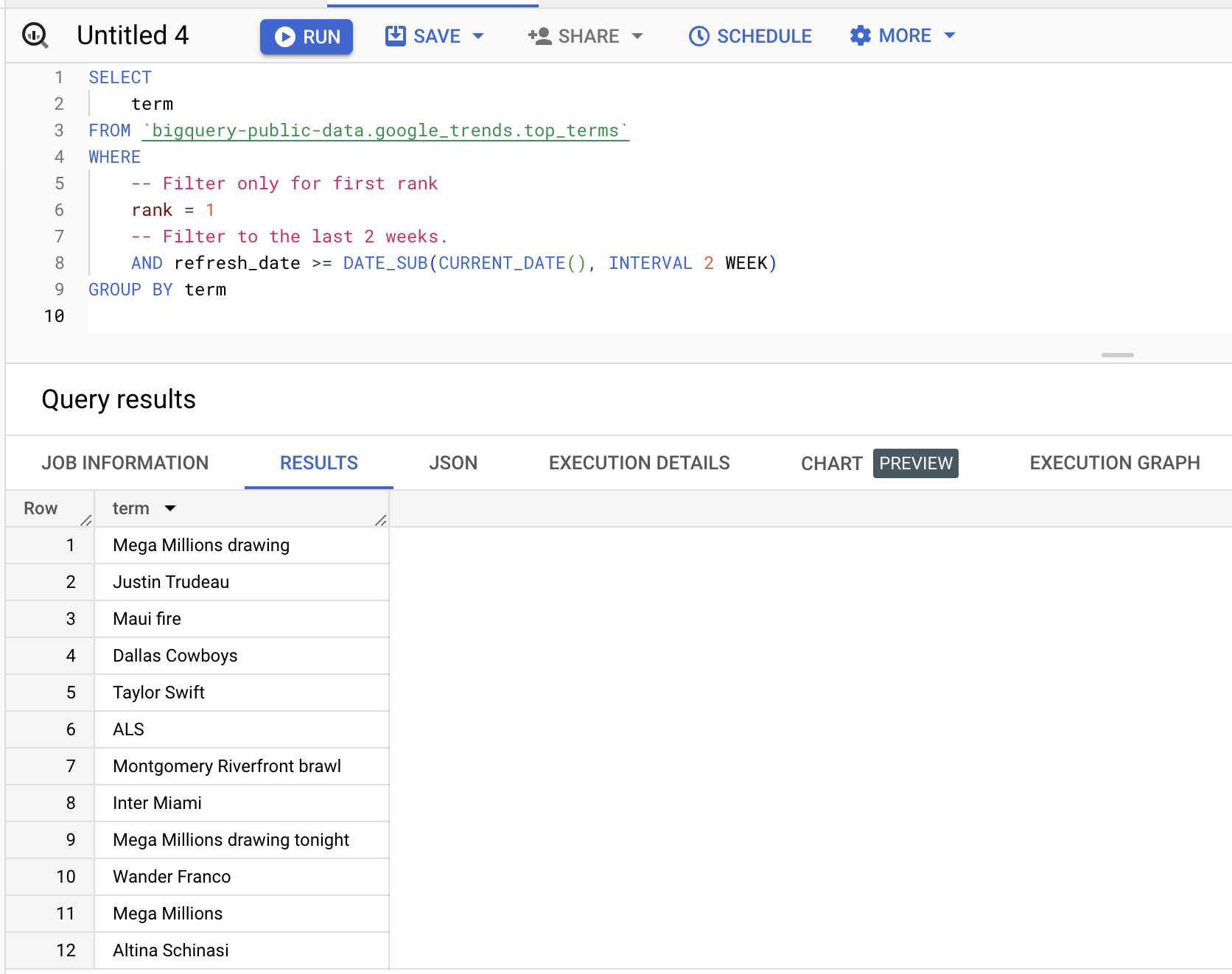
You can query the dataset, example below to fetch terms that ranked in first position in the last two weeks:
SELECT
term
FROM `bigquery-public-data.google_trends.top_terms`
WHERE
-- Filter only for first rank
rank = 1
-- Filter to the last 2 weeks.
AND refresh_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 2 WEEK)
GROUP BY term
Results (will vary):
You’re now ready to get started using BigQuery. Google Cloud offers a free trial of $300. BigQuery offers various payment options. For querying, you get 1TB free a month, and beyond that is $6.25 per TB. You can find more pricing information on the pricing page.
For those who are interested in a comprehensive understanding of data engineering, including working with cloud-based data warehouses like BigQuery, DataCamp offers a Data Engineer Learning Track that covers everything from the basics to advanced topics.
You can also check out our cheat sheet for a comparison of AWS, Azure, and Google Cloud Platform to get further insight into the tools available.
Get Started with Data Engineering Today!
Track
Course
Course
Nisha Arya Ahmed
15 min
Nisha Arya Ahmed
15 min
Abid Ali Awan
10 min
Srujana Maddula
9 min
Kurtis Pykes
8 min
Bex Tuychiev
9 min








