Certification available
Course
Introduction to SQL
2 hr
566.2K
Real world data is almost always messy. As a data scientist or a data analyst or even as a developer, if you need to discover facts about data, it is vital to ensure that data is tidy enough for doing that. There is actually a well-rounded definition of tidy data, and you can check out this wiki page to find more resources about it.
In this tutorial, you will be practicing some of the most common data cleaning techniques in SQL. You will create your own dummy dataset, but the techniques can be applied to the real world data (of the tabular form) as well. Lots of things to cover. Let's begin!
Note that you should already be knowing how to write basics SQL queries in PostgreSQL (the RDBMS you will be using in this tutorial). If you need to revise the concepts then following might be some useful resources:
In the tabular forms of data, the most common data-types are string, numeric or date-time. You can encounter messy values across all of these types. Let's now take each of these types and see some examples of their respective messy values. Let's start with the numeric type.
Numbers can be in messy forms in a number of ways. Here, you will be introduced to the most common ones:
Undesired type/Type mismatch: Consider there is a column named age in a dataset you are working with. You see the values that are present in that column are of float type - the sample values are like 23.0, 45.0, 34.0 and so on. In this case, you don't need the age column to be of float type. Isn't it so?
Null values: While this is particularly common with all of the data-types mentioned above, null values here merely means that the values are not available/blank. However, null values can be present in other forms as well. Take the Pima Indian Diabetes dataset for example. The dataset contains zero values for columns like Plasma glucose concentration, Diastolic blood pressure which is practically invalid. If you perform any statistical analysis on the dataset without taking care of these invalid entries, your analysis will not be accurate.
Let's now study the problems that can get raised from these issues and how to deal with them.
Let's now take a look at the most common problems that you may face if you do not clean the messy data (w.r.t to the above-mentioned types).
Suppose you have null entries for a numeric column and you are calculating summary statistics (like mean, maximum, minimum values) on that column. The results will not get conveyed accurately in this case. Again consider the Pima Indian Diabetes dataset with the invalid zero entries. If you calculated summary statistics on the columns as mentioned before, would you get the right results? Won't the results be erroneous? So, how to address this problem? There are several ways:
- Removing the entries containing missing/null values (not recommended)
- Imputing the null entries with a numeric value (typically with mean or median of the respective column)Let's now get hands-on with these problems and the second option for combating null values.
Consider the following PostgreSQL table named entries:
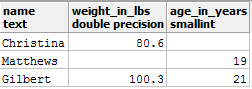
You can see two null entries in the above table. Suppose you want to the get the average weight value from this table and you executed the following query:
select avg(weight_in_lbs) as average_weight_in_lbs from entries;
You got 90.45 as the output. Is this correct? So, what can be done? Let's fill the null entry with this average value with the help of the COALESCE() function.
Let's fill the missing values first with COALESCE() (remember that COALESCE() does not change the values in the original table, it just returns a temporary view of the table with the values changed):
select *, COALESCE(weight_in_lbs, 90.45) as corrected_weights from entries;
You should get an output like:
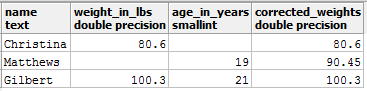
Now you can apply the AVG() again:
select avg(corrected_weights) from
(select *, COALESCE(weight_in_lbs, 90.45) as corrected_weights from entries) as subquery;
This is a much more accurate result than the earlier one. Let's now study another problem that can take place if you have mismatches in the column data-types.
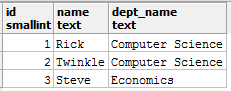
Consider you are working with the following tables student_metadata and department_details:

You can see in the student_mtadata table, dept_id is of integer type, and in the department_details table, it is present in text type. Now, suppose, you want to join these two tables and want to produce a report which will contain the following columns:
To do this, you run this query:
select id, name, dept_name from
student_metadata s join department_details d
on s.dept_id = d.dept_id;
You will encounter this error, then:
ERROR: operator does not exist: smallint = text
Here's an amazing infographic which depicts this problem (from DataCamp's Reporting in SQL course):
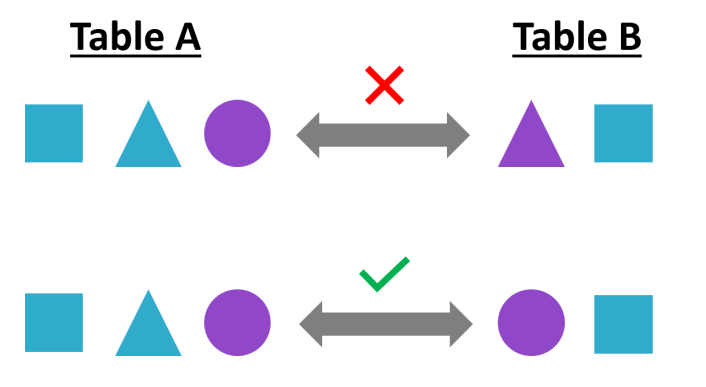
This happening because the data-types are not getting matched while joining the two tables. Here, you can CAST the dept_id column in the department_details table to integer while joining the tables. Here's how to do that:
select id, name, dept_name from
student_metadata s join department_details d
on s.dept_id = cast(d.dept_id as smallint);
And you get your desired report:
Let's now discuss how strings can be present in messy forms, their problems and ways to deal with them.
String values are also very common. Let's start this section by looking at the values of a column dept_name (denoting department names) taken from a table named student_details:
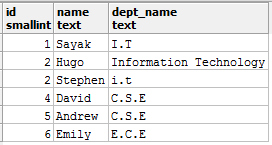
String values like the above can cause a lot of unexpected problems. I.T, Information Technology, and i.t all mean the same department, i.e. Information Technology and suppose the specification document requires the values to be present as I.T only. Now, say, you want to count the number of students belonging to the department of I.T., and you run this query:
select dept_name, count(dept_name) as student_count
from student_details
group by dept_name;
And you get:
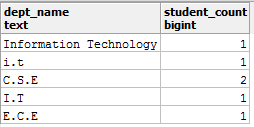
Is this an accurate report? - No! So, how can you address this problem?
Let's first identify the problem in a more detailed way:
Information Technology as a value which should be converted to I.T andi.t as another value which should be converted to I.T.In the first case, you can REPLACE the value Information Technology to I.T, and in the second case, you convert the character to UPPER case. You can accomplish this in a single query though it is advised to address this kind of problems in a step-by-step fashion. Here's the query to address the problem:
select upper(replace(dept_name, 'Information Technology', 'I.T')) as dept_cleaned,
count(dept_name) as student_count
from student_details
group by dept_cleaned;
And the report:
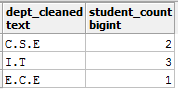
You can read more about PostgreSQL string functions here.
Let's now discuss some example where date values can be messy and what you can do to clean them.
Consider you are working with a table named employees which contains a column called birthdate but not in an appropriate date type. Now, you want to execute queries with dedicated date functions like DATE_PART(). You will not be able to do that until and unless you CAST the birthdate column to date type. Let's see this in action.
Consider the birthdates to be in the YYYY-MM-DD format.
Here's what the employees table looks like:
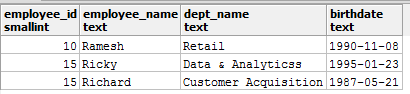
Now, you run the following query to extract the months from the birthdates:
select date_part('month', birthdate) from employees;
And you instantly get this error:
ERROR: function date_part(unknown, text) does not exist
Along with the error, you get a very good hint also:
HINT: No function matches the given name and argument types. You might need to add explicit type casts.
Let's follow the hint and CAST the birthdate to the appropriate date type and then apply DATE_PART():
select date_part('month', CAST(birthdate AS date)) as birthday_months from employees;
You should get the result:

Let's now proceed to the pre-concluding section of this tutorial where you will study the effects of data duplications and how you can tackle them.
In this section, you will be studying some of the most common causes which lead to data duplications. You will also see their effects and some of the ways using which prevent them. Consider the following two tables band_details and some_festival_record:

The table band_details conveys information about musical bands, it contains their identifiers, names and the total shows they have delivered. On the other hand, the table some_festival_record portrays a hypothetical music festival and contains records about the bands performed there.
Now, suppose you want to produce a report which should contain band names, their show counts, and the total number of times they have performed at the festival. INNER joining is needed here. You run the following query:
select band_name, sum(total_show_count) as total_shows, sum(performed) as total_times_performed
from band_details b join some_festival_record s
on b.id = s.band_id
group by band_name;
And the query produces:
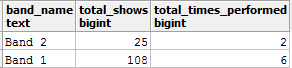
Don't you think the total_shows values are erroneous here? Because from the band_details table, you know that Band_1 has delivered a total of 36 shows. Then what went wrong here? Duplicates!
While joining the two tables, you mistakenly aggregated total_show_count column which caused a data duplication in the intermediate join results. If you remove the aggregation and modify the query accordingly you should get the desired results:
select band_name, total_show_count, sum(performed) as total_times_performed
from band_details b join some_festival_record s
on b.id = s.band_id
group by band_name, total_show_count;
You get your expected results now:
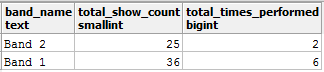
There is another way to prevent data duplication, i.e. add another field in your JOIN clause so that the tables get joined on stricter conditions.
You can use this .SQL file to generate the tables used here and also the values are shown.
Thank you for reading this tutorial. The tutorial introduced you to one of the most vital steps in the data analysis pipeline - data cleaning. You saw different forms of messy data and ways to tackle them. However, there are more advanced techniques to deal with more complex data cleaning problems, and if you want to pursue something in that regard, the following are some excellent DataCamp courses which you can take:
Feel free post your views in the Comments section.
SQL Courses
Course
Course
Course
blog
Matt Crabtree
8 min
blog
Jake Roach
8 min
blog
Elena Kosourova
7 min
podcast
Richie Cotton
36 min
tutorial
Abid Ali Awan
5 min
tutorial
Abid Ali Awan
5 min








