
track
AI Fundamentals
10hrs hours
In the fast evolving field of large language models (LLMs), staying on top of state of art approaches like prompt tuning is crucial. This technique, applied to already trained foundational models, enhances performance without the high computational costs associated with traditional model training.
In this article, we’ll explore the fundamentals of prompt tuning, compare it to fine-tuning and prompt engineering, and discuss its significant benefits. We'll also provide a practical example utilizing HuggingFace’s platform, where we Prompt tune a bloomz-560m model. This guide aims to deepen your understanding of prompt tuning and inspire its integration into your projects.
Prompt tuning is a technique designed to enhance the performance of a pre-trained language model without altering its core architecture. Instead of modifying the deep structural weights of the model, prompt tuning adjusts the prompts that guide the model’s response. This method is based on the introduction of "soft prompts," a set of tunable parameters inserted at the beginning of the input sequence.
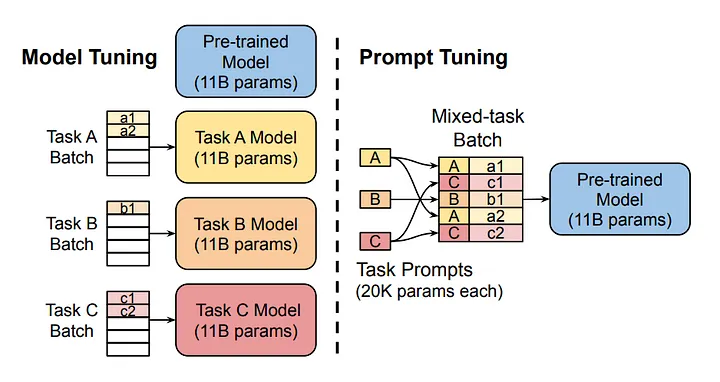
Image source
The diagram compares the traditional approach of model tuning with prompt tuning. Notice that in model tuning, each task requires a separate model. On the other hand, prompt tuning utilizes the same foundational model across multiple tasks by adjusting task-specific prompts.
Soft prompts are artificially constructed tokens that are added to the model’s input sequence. These prompts can be initialized in several ways. Random initialization is common, however they can also be initialized based on certain heuristics. Once initialized, soft prompts are attached to the start of the input data. When the model processes this data, it considers both the soft prompts and the actual input.
The training process is usually similar to that of training a standard deep neural network (DNN). It starts with a forward pass where the model processes the combined input through its layers, producing an output. This output is then evaluated against the desired outcome using a loss function, which measures the discrepancy between the model’s output and the actual expected value.
During backpropagation, the errors are propagated back through the network. However, instead of adjusting the network's weights, we only modify the soft prompt parameters. This process repeats across multiple epochs, with the soft prompts gradually learning to shape the model’s processing of inputs in such a way that minimizes the error for the given task.
The process of forward pass, loss evaluation, and backpropagation is repeated over multiple epochs. Over time, these soft prompts learn to shape the input in ways that consistently reduce the loss score, thereby improving the model's task-specific performance without compromising its underlying capabilities.
Prompt tuning, fine tuning, and prompt engineering are three distinct methods applied to pre-trained LLMs to improve their performance on a specific task. These methods are not mutually exclusive and are each suited to a particular use case.
Fine-tuning is the most resource-intensive, involving a comprehensive re-training of the model on a specific dataset for a specific purpose. This adjusts the weights of the pre-trained model, optimizing it for detailed nuances of the data but requiring substantial computational resources and increasing the risk of overfitting. Many LLMs like Chat GPT undergo fine-tuning after their initial generic training on the next word prediction task. Fine-tuning teaches these models how to function as digital assistants, making them significantly more useful than a generally trained model.
Prompt tuning adjusts a set of extra parameters, known as "soft prompts," which are integrated into the model's input processing. This method modifies how the model interprets input prompts without a complete overhaul of its weights, offering a balance between performance enhancement and resource efficiency. It is particularly valuable when computational resources are limited or when flexibility across multiple tasks is required, because after applying the technique the original model weights remain unchanged.
Prompt engineering, on the other hand, involves no training or retraining at all. It is completely based on the user designing prompts for the model. It requires a nuanced understanding of the model’s processing capabilities and leverages the intrinsic knowledge embedded within the model. Prompt engineering does not require any computational resources since it relies solely on the strategic formulation of inputs to achieve results. Check out DataCamp's course on prompt engineering for developers to learn more.
Each of these techniques offers a different approach to leveraging the capabilities of pre-trained models. The choice between them depends on the specific needs of the application, such as the availability of computational resources, the requirement for model customization, and the desired level of interaction with the model's learning parameters.
|
Method |
Resource Intensity |
Training Required |
Best For |
|
Fine-Tuning |
High |
Yes |
Tasks requiring deep model customization |
|
Prompt Tuning |
Low |
Yes |
Maintaining model integrity across tasks |
|
Prompt Engineering |
None |
No |
Quick adaptations with no computational cost. |
Each method has its place depending on the specific needs of your project.
Prompt tuning brings several key benefits to the table, making it an indispensable technique for optimizing large language models.
Prompt tuning maintains the pre-trained model's parameters unchanged, significantly reducing the computational power needed. This efficiency is especially crucial in resource-constrained environments, allowing for sophisticated model use without the high cost. As the average size of foundational models increases, “freezing” model parameters becomes even more appealing since a separate model doesn't need to be deployed for each task.
Unlike comprehensive fine-tuning, prompt tuning requires adjustments only to a small set of soft prompt parameters. This speeds up the adaptation process, enabling quicker transitions between different tasks and reducing downtime.
By keeping the core architecture and weights of the model intact, prompt tuning preserves the original capabilities and knowledge embedded in the pre-trained model. This is critical for maintaining the reliability and generalizability of the model across various applications.
Prompt tuning facilitates using a single foundational model for multiple tasks by simply changing the soft prompts. This approach reduces the need to train and maintain separate models for each specific task, enhancing scalability and simplicity in model management.
Prompt tuning requires significantly less human intervention than prompt engineering, where carefully crafting prompts to suit a particular task can be error-prone and time-consuming. Instead, the automated optimization of soft prompts during training minimizes human error and maximizes efficiency.
Research indicates that for large models, prompt tuning can achieve performance levels comparable to those of fine tuning. This benefit becomes increasingly significant as model sizes grow, combining high efficiency with strong results.
For this guide, we'll apply prompt tuning to BigScience's bloomz-560m model. We'll be working within the Hugging Face ecosystem using the PEFT (Parameter-Efficient Fine-Tuning) library.
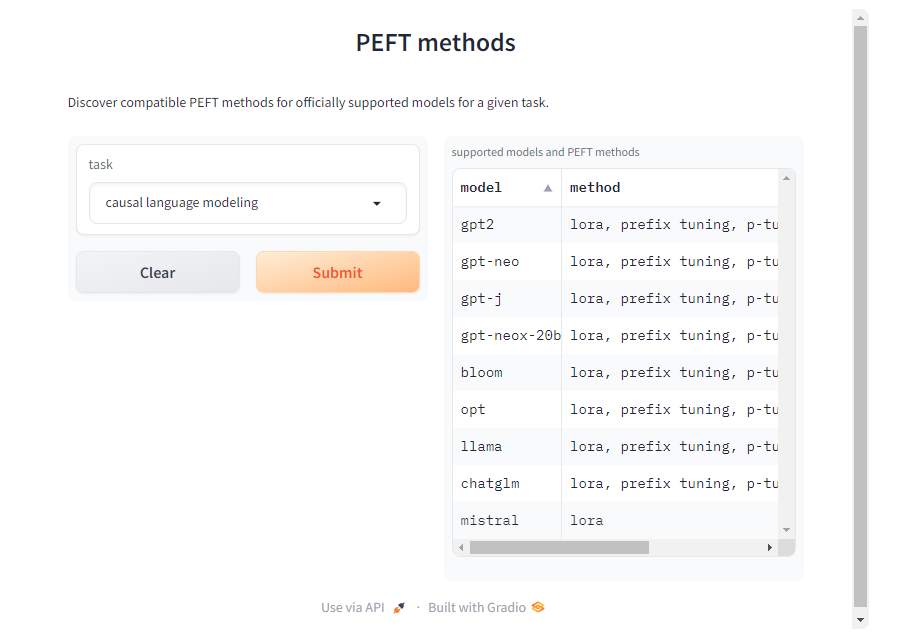
Although we'll focus on the causal language modeling task here, the PEFT library supports various tasks, models, and tuning techniques. You can find compatible PEFT methods for other models and tasks on the PEFT documentation page.
To start, we load the model and tokenizer from the BigScience bloomz-560m model. The tokenizer is used to process text inputs, while the foundational model handles causal language modeling tasks. The trust_remote_code=True parameter allows you to use custom code provided by the model's maintainers for specific architectures.
While this is useful for gaining full functionality, only trust the model’s code if it's from a reputable source. Avoid using untrusted code for models from unknown or unverified creators, as it may pose security or stability risks.
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "bigscience/bloomz-560m"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
trust_remote_code=True
)Before any tuning, it's essential to establish a baseline by running inference with the un-tuned foundational model. Using a prompt like "I want you to act as a logistician," we can observe how the model generates responses without further tuning. Make sure to include an extra space after the prompt, otherwise the model might not generate anything.
This serves as a reference for comparing improvements after tuning.
We will be using a custom generate_text function to make our life easier.
def generate_text(model, tokenizer, prompt_text, max_tokens):
prompt_text = tokenizer(prompt_text, return_tensors="pt")
outputs = model.generate(
input_ids=prompt_text["input_ids"],
attention_mask=prompt_text["attention_mask"],
max_length=max_tokens,
repetition_penalty=1.5,
eos_token_id=tokenizer.eos_token_id
)
return tokenizer.batch_decode(outputs, skip_special_tokens=True)
initial_output = generate_text(model, tokenizer, "I want you to act as a logistician. ", 100)
print("Initial model output:", initial_output)This is the model output:
['I want you to act as a logistician. You will be able to: Analyze the data']
As you can see the model is not quite sure of the context.
The dataset is a crucial element of prompt tuning. We use the `awesome-chatgpt-prompts` dataset for tuning. This dataset provides motivational content for tuning, ensuring that the model adapts its responses accordingly.
from datasets import load_dataset
dataset_prompt = "fka/awesome-chatgpt-prompts"
data_prompt = load_dataset(dataset_prompt)
data_prompt = data_prompt.map(lambda x: tokenizer(x["prompt"]), batched=True)
train_prompts = data_prompt["train"].select(range(50))We tokenize the dataset and prepare a small subset for training.
Now, the most interesting part; we configure the prompt tuning using the PromptTuningConfig class from the PEFT library.
from peft import get_peft_model, PromptTuningConfig, TaskType, PromptTuningInit
tuning_config = PromptTuningConfig(
task_type=TaskType.CAUSAL_LM, #This type indicates the model will generate text.
prompt_tuning_init=PromptTuningInit.RANDOM, #The added virtual tokens are initializad with random numbers
num_virtual_tokens=4, #Number of virtual tokens to be added and trained.
tokenizer_name_or_path=model_name
)
peft_model = get_peft_model(model, tuning_config)The training arguments are specified using the TrainingArguments class.
from transformers import TrainingArguments
training_args = TrainingArguments(
use_cpu=True, # This is necessary for CPU clusters.
output_dir = "./",
auto_find_batch_size=True, # Find a suitable batch size that will fit into memory automatically, you can also use a custom batch size
learning_rate= 0.005,
num_train_epochs=5
)A Trainer object manages the training process. With DataCollatorForLanguageModeling, the data collator ensures that the training samples are appropriately formatted. The training phase is initiated with the train method, fine-tuning the bloomz-560m model for the specific prompt tasks.
from transformers import Trainer, DataCollatorForLanguageModeling
trainer = Trainer(
model=peft_model, # We pass in the PEFT version of the foundation model, bloomz-560M
args=training_args, #The args for the training.
train_dataset=train_prompts, #The dataset used to train the model.
data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False) # mlm=False indicates not to use masked language modeling
)
trainer.train()The tuned model is stored in the trainer object, we can use trainer.model to access it. We use the generate_text function to run inference with the tuned model!
tuned_output = generate_text(trainer.model, tokenizer, "I want you to act as a logistician. ", 100)
print("Tuned model output:", tuned_output)Here is the output of the tuned model:
['I want you to act as a logistician. You will be responsible for the logistics of your business.']
As you can see now, the model knows what the logistician does. Feel free to experiment with different prompts, models and datasets!
Prompt tuning is a powerful tool to make large language models more efficient on a specific task. We have explored prompt tuning by first explaining what it is and how it operates. Then we compared it to other similar techniques: fine tuning and prompt engineering. Lastly, we discussed its benefits and went through a step-by-step guide of applying prompt tuning to a pretrained model.
As the field of generative AI continues to evolve, It is important to stay on top of the latest developments. To further enhance your skills and understanding of AI, Datacamp offers a variety of in-depth resources. I encourage you to explore these comprehensive tutorials:
Keep Learning With DataCamp
track
course
course
tutorial
Josep Ferrer
12 min
tutorial
Moez Ali
11 min
tutorial
Moez Ali
11 min
tutorial
Dimitri Didmanidze
12 min
code-along
Isabella Bedoya
code-along
Adel Nehme



