
course
Large Language Models (LLMs) Concepts
2 hours
25.8K
Imagine a Large Language Model (LLM) where the answers you get aren't just relevant; they're finely curated, prioritized, and refined to match your exact needs. While LLMs have revolutionized the realm of AI, they are not without limitations. Issues such as hallucinations and data obsolescence can compromise the accuracy and relevance of their outputs. This is where Retrieval-Augmented Generation (RAG) and reranking come into play, offering a way to enhance LLMs by integrating them with dynamic, up-to-date information retrieval processes. Curious about the steps of this recipe? Keep reading.
LLMs have revolutionized the realm of AI and pushed the boundaries of what we can achieve by using AI. They have become the go-to tool for anyone seeking versatile NLP solutions in virtually any domain by modeling a range of natural language understanding and generation tasks, as shown below.
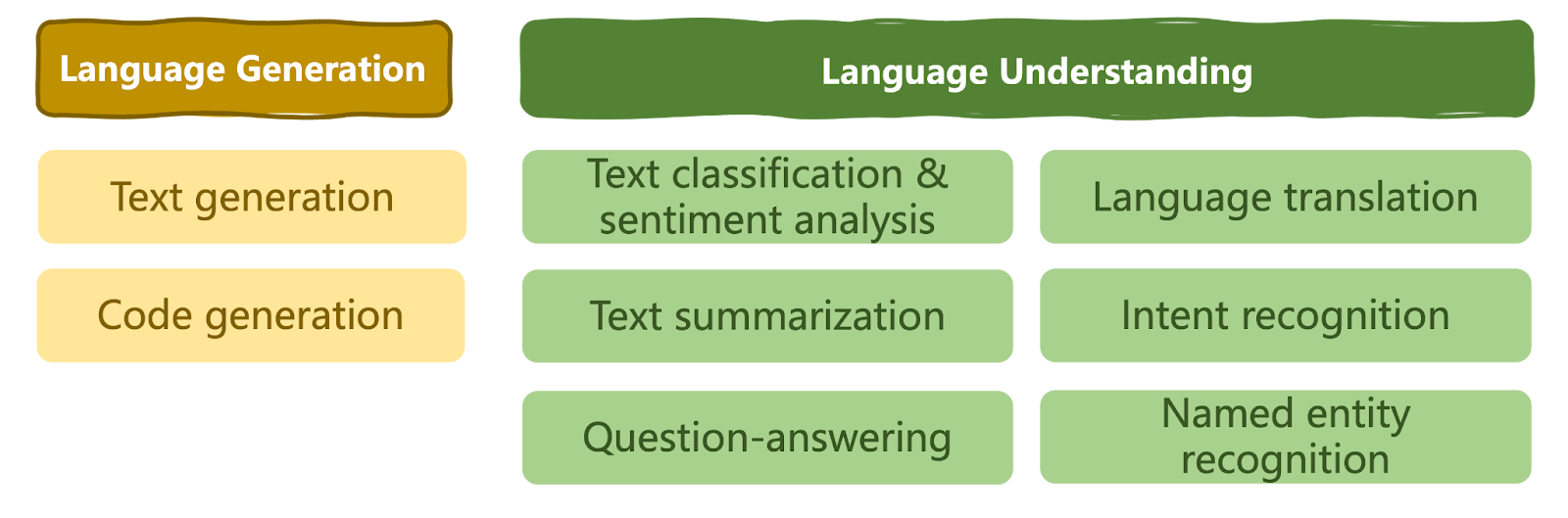
A taxonomy of solvable language tasks by LLMs | Iván Palomares
Despite their capabilities, LLMs also have limitations in certain scenarios. Depending on the specific use case and the knowledge they have learned from the vast dataset they are trained on, LLMs sometimes fail to generate coherent, relevant, or contextually appropriate text. Sometimes, in the absence of relevant truthful data to create a response to user queries, they may even generate incorrect or nonsensical information as if it were true. This phenomenon is known as hallucination.
Consider, for instance, the question: "What are the common flu symptoms?"
A standard LLM might generate a response based on general knowledge, listing common symptoms like fever, cough, and body aches.
However, unless it had been trained on very domain-specific flu virus data, the LLM might not consider variations in symptom severity or distinguish between flu strains, thereby providing rather generic and even somewhat “automated” replies to different users regardless of their circumstances or needs.
What’s more, if, for instance, the model had been trained on clinical flu data collected up to December 2023, and a new flu strain appears and quickly spreads across the population in January 2024, a standalone LLM will be unable to provide accurate responses due to the lack of up-to-date knowledge about the problem domain.
This “data obsolescence” problem is known as knowledge cut-off.
In some cases, the solution to the above problem could be frequently retraining and fine-tuning the LLM on fresh, up-to-date information. But is this necessarily the best course of action?
LLMs (Large Language Models) are known to be challenging and computationally expensive to train. They require millions to billions of text data instances and often thousands of domain-specific texts for fine-tuning (see diagram below).
Most LLMs, even domain-specific ones, are typically fine-tuned to work across wide-scope domains, such as health. Therefore, introducing new fine-grained data to accommodate all possible contextual nuances across the domain may not be the most efficient solution.
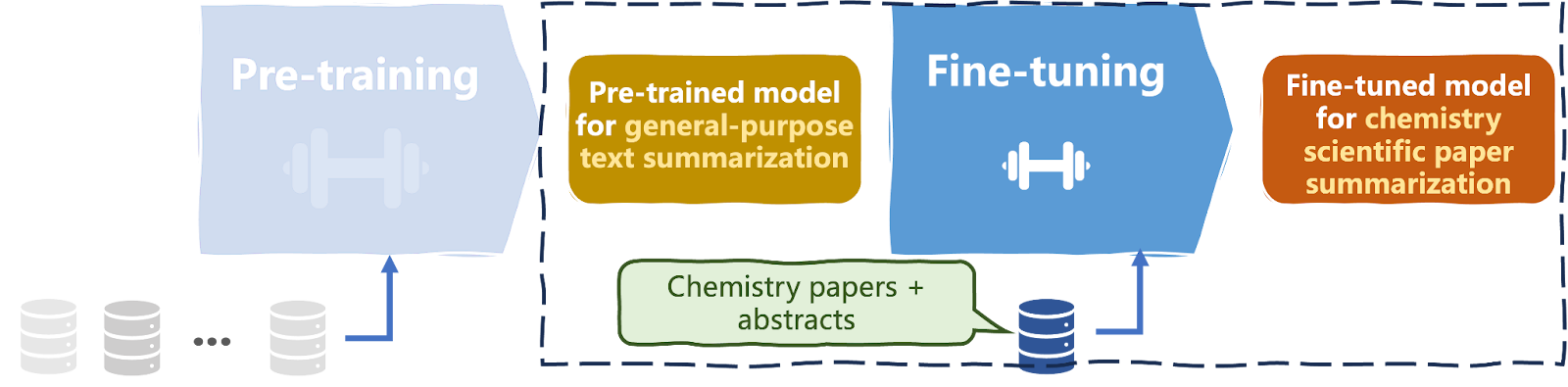
Pre-training and fine-tuning an LLM | Iván Palomares
This is where RAG (Retrieval Augmented Generation) comes to help!
RAG is an information retrieval process whereby the outputs produced by an LLM are optimized. LLMs rely on the knowledge gained from the data they have been generated upon to generate responses.
Meanwhile, RAG points to an external knowledge base.
By combining both solutions, RAG can be used to enhance the quality, user relevance, coherence, and truthfulness of the “raw” output generated by the LLM by retrieving knowledge from the knowledge base mentioned earlier.
As a result, the necessity of continuously retraining the LLM to adapt it to ever-emerging new contexts and situations is largely removed.
The general workflow of an RAG system is described in a simplified way below:
Back to the flu example, we can see that with RAG, the model could retrieve up-to-date, relevant information from medical databases or recent articles, enabling it to generate a more nuanced and accurate answer to the patient or practitioner’s inquiry.
It could incorporate insights about current flu strains, regional variations in symptoms, or emerging patterns, thereby providing a more relevant and coherent response to the user's query.
Reranking is an information retrieval process where an initial set of retrieved results is reordered to improve relevance to the user query, needs, and context, thereby enhancing the overall output quality. Here’s how it works:
The following diagram illustrates the reranking process:
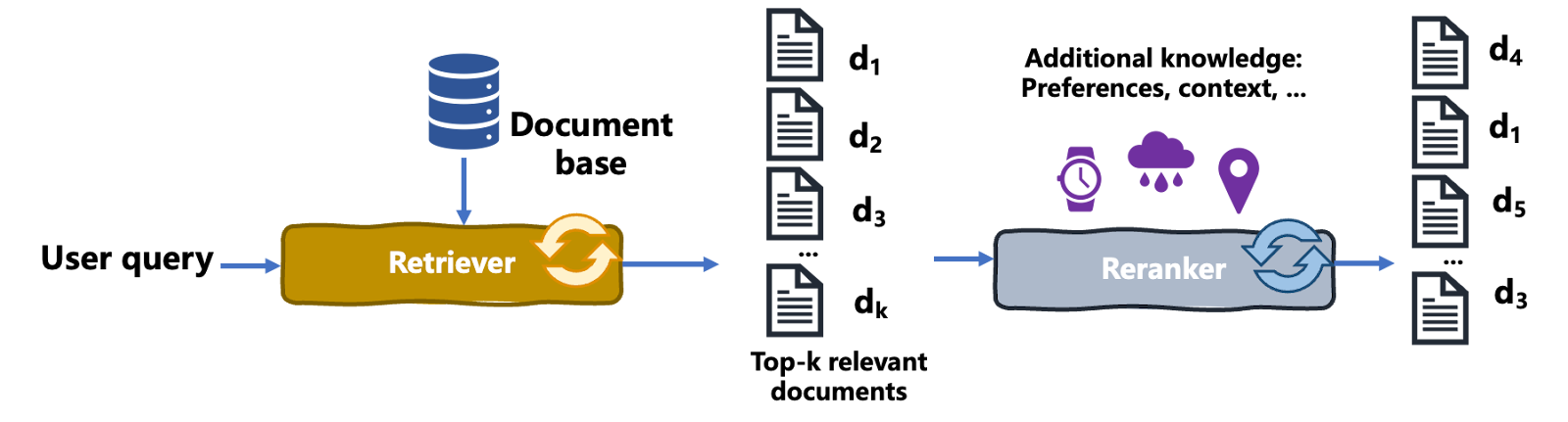
Reranking process | Iván Palomares
Let's clarify an important point here: reranking reorders retrieved documents based on various criteria, such as user preferences. However, reranking is different from recommender engines, like the ones that suggest relevant products to buy on e-commerce sites.
Reranking is used in search use cases where a user provides an input query in real time.
In contrast, recommender engines proactively create personalized suggestions for users based on their interactions and preferences over time.
Let’s revisit the flu example.
Consider a situation where a healthcare professional searches for "best treatments for flu symptoms." An initial retrieval system might return a list of documents, including general flu information, treatment guidelines, and research articles.
But a reranking model, possibly using additional patient-specific data and contextual information, can then reorder these documents to prioritize the most relevant and recent treatment protocols, patient care tips, and peer-reviewed research studies directly addressing flu symptoms and their management, thereby prioritizing results that go “straight to the point.”
To sum up, reranking reorganizes a list of retrieved documents based on additional relevance criteria to display the most relevant to the specific user first.
Reranking is particularly useful in Large Language Models (LLMs) equipped with Retrieval-Augmented Generation (RAG). RAG combines LLMs with external document retrieval to provide more informed and accurate responses.
After the initial retrieval of documents based on a query, a reranking process can refine the selection, ensuring the LLM works with the most relevant and high-quality information.
This process enhances the overall performance of the LLM, improving response accuracy and relevance, particularly in specialized domains where precise information is critical.
There is no single recipe for implementing a reranker. Several approaches have been established, some of which are:
Now that we understand the benefits of incorporating RAG into LLMs, as well as the reranking mechanisms for knowledge retrieval, it’s time to integrate these elements together and see them in action.
This example uses Langchain library (community version) to build a simple RAG pipeline with reranking. Discover much more about developing LLM applications with Langchain in Developing LLM Applications course and this tutorial on how to build LLM applications with Langchain.
The code has been implemented in a Google Colab notebook.
pip install -U langchain-communityFirst, we install langchain-community in our notebook.
Next, import the necessary packages, classes, and functions.
import os
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.text_splitter import CharacterTextSplitter
from langchain.schema import Document
from langchain.chains.qa_with_sources import load_qa_with_sources_chain
from sklearn.metrics.pairwise import cosine_similarity
import numpy as npThe following function is defined to load a list of documents (.txt files) from a local directory your code notebook should be able to read from. These will be the documents to be retrieved and reranked to enhance LLM outputs:
# Function to load documents from a directory
def load_documents_from_directory(directory_path):
documents = []
for filename in os.listdir(directory_path):
if filename.endswith(".txt"):
with open(os.path.join(directory_path, filename), 'r') as file:
documents.append(file.read())
return documents
# Load documents from the specified directory
directory_path = "./sample_data"
documents = load_documents_from_directory(directory_path)
To optimize the performance of embedding representations of text documents, we limit their size to 1000 and split documents with longer extensions into smaller chunks. The CharacterTextSplitter class helps do the job.
The chunk_overlap argument is set to 0 to avoid overlapping portions of text across chunks.
# Split documents into chunks for better embedding performance
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
We will use OpenAI embeddings to build our embedding vector store. Notice that depending on the environment you are running your code on, you may be required to get a validation key from OpenAI defined in OPENAI_API_KEY.
# Initialize OpenAI embeddings
embeddings = OpenAIEmbeddings()
# Build FAISS vector store upong document chunk embeddings
vector_store = FAISS.from_documents(docs, embeddings)
# Load and initialize OpenAI LLM
llm = OpenAI(model="text-davinci-003", temperature=0.7)FAISS creates a vector store from embeddings. We need to pass two arguments to its from_documents() function. The document chunks, and the initialized embeddings instance with the aid of OpenAIEmbeddings.
After that, we bring one of the main actors into stage: the LLM! We use OpenAI to load the text-davinci-003 model, setting a moderately high model temperature 0.7 to allow for some degree of originality in text generation.
Let’s take a few more steps:
# Define the prompt template for the LLM
prompt_template = PromptTemplate(template="Answer the question based on the context: {context}\n\nQuestion: {question}\nAnswer:")
# Define the RAG chain with reranking using a QA chain
qa_chain = load_qa_with_sources_chain(llm, prompt_template=prompt_template, retriever=vector_store.as_retriever())
# Example question
question = "What are the common symptoms of the flu and how can it be treated?"
# Generate an answer using the QA chain
response = qa_chain(question=question)
print(response)The above code first defines a question-answering prompt template. It then calls the load_qa_with_sources_chain() function to create a question-answering pipeline (or chain in Langchain jargon). Its retriever argument allows to incorporate a retrieval component into the LLM pipeline, thereby enabling RAG.
A question is finally formulated, and we run the defined pipeline qa_chain. Voila!
Here’s the output (it depends on the documents you’d be reading from):
“Common symptoms of the flu include fever, cough, sore throat, runny or stuffy nose, body aches, headache, chills, and fatigue. Some people may experience vomiting and diarrhea, particularly children. The flu can be treated with antiviral drugs, which can make the illness milder and shorten the duration of sickness. Antiviral drugs may also prevent serious complications such as pneumonia. Prompt treatment is recommended for individuals who are very sick or at high risk of complications.”
The previous example looked nice, except that it didn’t incorporate the reranking phase. Modifying the code to incorporate reranking is relatively straightforward.
The list of imports is the same, as we already made in the previous version all the necessary imports for the reranking phase -even though we hadn’t used some of them yet:
# Previous code here
#...
# Define the prompt template for the LLM
prompt_template = PromptTemplate(template="Answer the question based on the context: {context}\n\nQuestion: {question}\nAnswer:")
# Reranking function
def rerank_documents(question, retrieved_docs, top_n=5):
question_embedding = embeddings.embed_text(question)
doc_embeddings = [doc.embedding for doc in retrieved_docs]
similarities = cosine_similarity([question_embedding], doc_embeddings)[0]
ranked_indices = np.argsort(similarities)[::-1] # Sort by descending similarity
ranked_docs = [retrieved_docs[i] for i in ranked_indices[:top_n]]
return ranked_docsAs we can see, what we do first is define a rerank_documents function that uses cosine similarity on embeddings to calculate the similarity between the question embedding and document embeddings, returning the top-n ranked documents.
# Custom QA chain with reranking
class CustomQAWithReranking:
def __init__(self, llm, retriever, prompt_template, top_n=5):
self.llm = llm
self.retriever = retriever
self.prompt_template = prompt_template
self.top_n = top_n
def __call__(self, question):
retrieved_docs = self.retriever.retrieve_documents(question)
ranked_docs = rerank_documents(question, retrieved_docs, self.top_n)
context = "\n".join([doc.page_content for doc in ranked_docs])
prompt = self.prompt_template.format(context=context, question=question)
return self.llm(prompt)The CustomQAWithReranking class integrates in the LLM the retrieval and reranking steps in the LLM pipeline, which will be invoked by calling the call () function in this class.
# Define the custom QA chain with reranking
qa_chain = CustomQAWithReranking(llm, vector_store.as_retriever(), prompt_template)
# Example question
question = "What are the benefits of using multi-vector rerankers?"
# Generate an answer using the custom QA chain
response = qa_chain(question)All that remains is instantiating again qa_chain. Notice this time we will do this by defining an object of the class we just create, which encapsulates most of the logic in our previous version plus our custom reranking mechanism.
Finally, we formulate the question and invoke the chain to get a response.
In the realm of LLMs and AI as a whole, RAG has arguably come to stay. Having an LLM access and retrieve knowledge from external sources as part of the process to generate responses, has become a widely accepted alternative to constant retraining and fine-tuning of LLMs.
This article discussed reranking as a useful approach to incorporating effective information retrieval as part of an LLM pipeline. It highlighted how the reranking process works, different types of rerankers, and a practical example using Langchain and the OpenAI API.
Interested in learning more? Take a look at these additional resources:
Learn More About LLMs
course
course
track
blog
Natassha Selvaraj
8 min
blog
Ryan Ong
11 min
tutorial
Abid Ali Awan
13 min
tutorial
Eugenia Anello
code-along
Dan Becker
code-along
Yujian Tang







