
course
Vector Databases for Embeddings with Pinecone
3 hours
204
Get Started Using the OpenAI API and More!
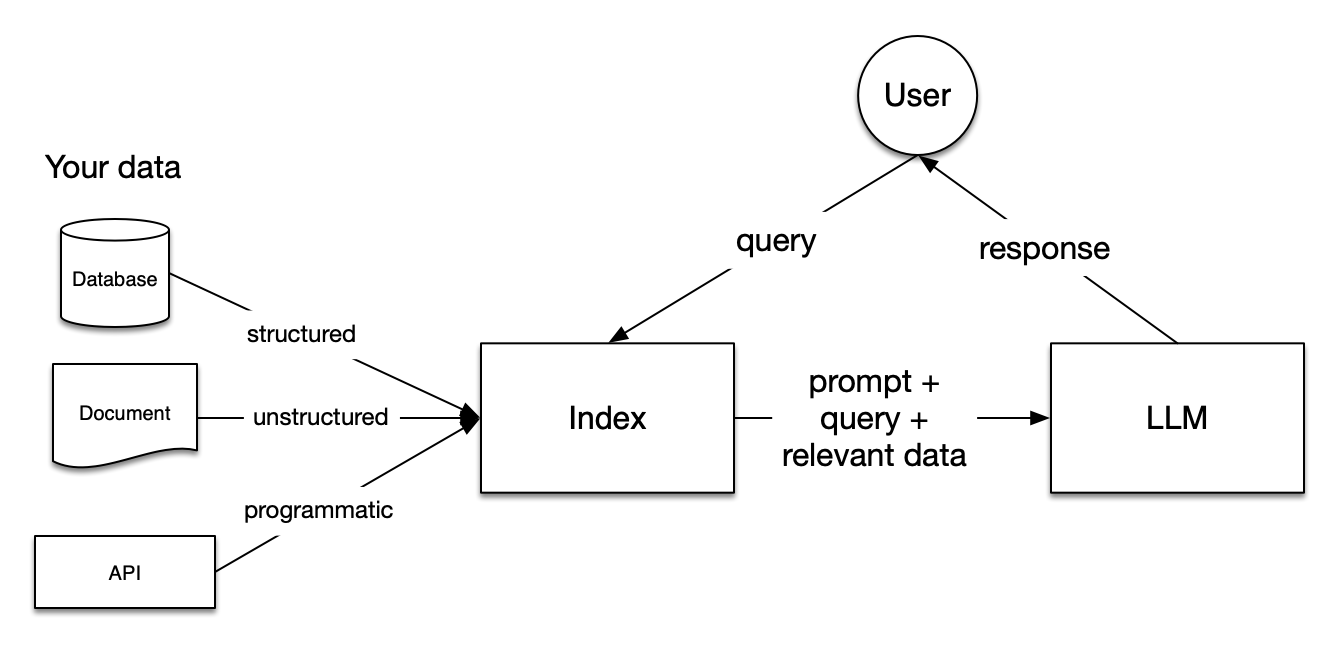
Image from LlamaIndex Documentation
Retrieval Augmented Generation (RAG) pipelines include three steps: Indexing, Retrieval, and Generation.
Indexing is fundamental for obtaining accurate and context-aware answers with LLMs. First, it starts by extracting and cleaning data with different file formats, such as Word Documents, PDF files, or HTML files. Once the data is cleaned, it’s converted into standardized plain text. To avoid context limitations within LLMs, the text is split into smaller chunks. This process is called Chunking. After, each chunk is transformed into a numeric vector or embedding using an embedding model. Finally, an index is built to store the chunks and their corresponding embeddings as key-value pairs.
During the retrieval stage, the user query is also converted into a vector representation using the same embedding model. Then, the similarity scores between the query vector and the vectorized chunks are calculated. The system retrieves the top K chunks with the greatest similarity to the user query.
The user query and the retrieved chunks are fed into a prompt template. The augmented prompt obtained from the previous steps is finally given as input to the LLM.
When building RAG systems, there are significant challenges you may encounter in all the three steps previously explained, such as the following:
Below, we’ll explore strategies to circumvent these limitations. We’ll discuss three broad strategies: Chunking, Re-Ranking, and Query Transformations. Moreover, we’ll showcase how these strategies can help improve RAG performance by building a RAG system that answers questions about Wikipedia entries using Llamaindex and the OpenAI API . Let’s dive in!
Before exploring the tricks to improve the performance of a RAG system, we need to establish a baseline performance by establishing a simple RAG pipeline. Let’s start by installing the llama-index and openai packages.
!pip install llama-index
!pip install openaiLlamaindex is a data framework for applications based on Large Language Models (LLMs). It enables ingesting different types of external data sources, building Retrieval Augmentation Generation (RAG) systems, and abstracting integrations with other LLMs into a few lines of code. Moreover, it provides several techniques to generate more accurate outputs with LLMs.
By default, it uses the OpenAI gpt-3.5-turbo model for text generation and the text-embedding-ada-002 model for retrieval and embeddings. To use these models, it’s necessary to create a free account on the OpenAI platform and obtain an OpenAI API key. To get the key, please visit the OpenAI API documentation.
import os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"Now that our packages our installed, we will build a RAG system that answers questions based on the Wikipedia pages of Emma Stone, Ryan Gosling, and La La Land. First, we need to install the wikipedia library to extract the Wikipedia pages:
!pip install wikipediaThen, we can easily download the data from Wikipedia:
# Import packages
from llama_index.core import (VectorStoreIndex,ServiceContext, download_loader)
# Download the documents from Wikipedia and load them
WikipediaReader = download_loader("WikipediaReader")
loader = WikipediaReader()
pages = ['Emma_Stone', 'La_La_Land', 'Ryan_Gosling']
documents = loader.load_data(pages=pages, auto_suggest=False, redirect = False)Once the data is extracted, we can split the documents into chunks of 256 characters with no overlap. Later, these chunks are transformed into numerical vectors using the embedding model and indexed in a Vector Store.
# Initialize the gpt3.5 model
gpt3 = OpenAI(temperature=0, model="gpt-3.5-turbo-instruct", api_key=OPENAI_API_KEY)
# Initialize the embedding model
embed_model = OpenAIEmbedding(model= OpenAIEmbeddingModelType.TEXT_EMBED_ADA_002, api_key=OPENAI_API_KEY)
# Transform chunks into numerical vectors using the embedding model
service_context_gpt3 = ServiceContext.from_defaults(llm=gpt3, chunk_size = 256, chunk_overlap=0, embed_model=embed_model)
index = VectorStoreIndex.from_documents(documents, service_context=service_context_gpt3)
retriever = index.as_retriever(similarity_top_k=3)To reduce the risk of hallucinations, we use the PromptTemplate module to ensure the answers of the LLM are based only on the context provided.
from llama_index.core.prompts import PromptTemplate
# Build a prompt template to only provide answers based on the loaded documents
template = (
"We have provided context information below. \n"
"---------------------\n"
"{context_str}"
"\n---------------------\n"
"Given this information, please answer the question: {query_str}\n"
"Don't give an answer unless it is supported by the context above.\n"
)
qa_template = PromptTemplate(template)Now that we’ve set up our RAG system, we can test it with questions based on retrieved documents. Let’s put it to the test!
Query 1: “What is the plot of the film that led Emma Stone to win her first Academy Award?”
This first query is challenging because it requires the model to look at different pieces of information:
# Create a prompt for the model
question = "What is the plot of the film that led Emma Stone to win her first Academy Award?"
# Retrieve the context from the model
contexts = retriever.retrieve(question)
context_list = [n.get_content() for n in contexts]
prompt = qa_template.format(context_str="\n\n".join(context_list), query_str=question)
# Generate the response
response = gpt3.complete(prompt)
print(str(response))Output:
The plot of the film that made Emma Stone win her first Academy Award is not explicitly mentioned in the provided context.Query 2: "Compare the families of Emma Stone and Ryan Gosling”
This second query is even more challenging than the previous question since it asks to select the relevant chunks regarding the families of the two actors.
# Create a prompt for the model
question = "Compare the families of Emma Stone and Ryan Gosling"
# Retrieve the context from the model
contexts = retriever.retrieve(question)
context_list = [n.get_content() for n in contexts]
prompt = qa_template.format(context_str="\n\n".join(context_list), query_str=question)
# Generate the response
response = gpt3.complete(prompt)
print(str(response))We receive the following output:
Based on the context provided, it is not possible to compare the families of Emma Stone and Ryan Gosling as the information focuses on their professional collaboration and experiences while working on the film "La La Land." There is no mention of their personal family backgrounds or relationships in the context provided.As you can see, we’ve received subpar answers in both cases. In the following sections, let’s explore ways to improve the performance of this RAG system!
We can start by customizing the chunk size and the chunk overlap. As we said above, the documents are split into chunks with a specific overlap. By default, LlamaIndex utilizes 1024 as the default chunk size and 20 as the default chunk overlap. In addition to these hyperparameters, the system retrieves the top 2 chunks by default.
For example, we can fix the chunk size to 512, the chunk overlap to 50, and increase the top retrieved chucks:
# modify default values of chunk size and chunk overlap
service_context_gpt3 = ServiceContext.from_defaults(llm=gpt3, chunk_size = 512, chunk_overlap=50, embed_model=embed_model)
# build index
index = VectorStoreIndex.from_documents(
documents, service_context=service_context_gpt3
)
# returns the engine for the index
query_engine = index.as_query_engine(similarity_top_k=4)Query 1: “What is the plot of the film that led Emma Stone to win her first Academy Award?”
# generate the response
response = query_engine.query("What is the plot of the film that led Emma Stone to win her first Academy Award?")
print(response)Output:
The film that made Emma Stone win her first Academy Award is a romantic musical called La La Land.Compared to the previous answer, it’s slightly better. It successfully recognized La La Land as the film that led Emma Stone to win her first Academy Award, but it was not able to describe the film's plot.
Query 2: "Compare the families of Emma Stone and Ryan Gosling”
# generate the response
response = query_engine.query("Compare the families of Emma Stone and Ryan Gosling")
print(response)Output:
Emma Stone has expressed her close relationship with her family and mentioned being blessed with great family and people around her. She has also shared about her mother's battle with breast cancer and their celebration by getting matching tattoos. On the other hand, there is no specific information provided about Ryan Gosling's family or his personal relationships in the context.Again, the output of the RAG pipeline improved, but it still doesn’t capture information about Ryan Gosling’s family.
As the dataset grows in size and complexity, selecting relevant information for returning tailored answers to complex queries becomes crucial. For this purpose, a family of techniques called Re-Ranking allows you to understand which chunks are important within the text. They reorder and filter the documents, ranking the most relevant ones first.
There are two main approaches for Re-Ranking:
Before applying these Re-Ranking approaches, let’s evaluate what the baseline RAG system returns as the top three chunks for our second query:
# Retrieve the top three chunks for the second query
retriever = index.as_retriever(similarity_top_k=3)
query = "Compare the families of Emma Stone and Ryan Gosling"
nodes = retriever.retrieve(query)
# Print the chunks
for node in nodes:
print('----------------------------------------------------')
display_source_node(node, source_length = 500)This is the output before Re-Ranking; each chunk has a Node ID with a similarity score.
Node ID: 9b3817fe-3a3f-4417-83d2-2e2996c8b468
Similarity: 0.8415899563985404
Text: Emily Jean "Emma" Stone (born November 6, 1988) is an American actress and producer. She is the recipient of various accolades, including two Academy Awards, two British Academy Film Awards, and two Golden Globe Awards. In 2017, she was the world's highest-paid actress and named by Time magazine as one of the 100 most influential people in the world. Born and raised in Scottsdale, Arizona, Stone began acting as a child in a theater production of The Wind in the Willows in 2000. As a teenager,...
----------------------------------------------------
Node ID: 1bef0308-8b0f-4f7e-9cd6-92ce5acf811f
Similarity: 0.831147173341674
Text: Coincidentally, Gosling turned down the Beast role in Beauty and the Beast in favor of La La Land. Chazelle subsequently decided to make his characters somewhat older, with experience in struggling to make their dreams, rather than younger newcomers just arriving in Los Angeles. Emma Stone plays Mia, an aspiring actress in Los Angeles. Stone has loved musicals since she saw Les Misérables when she was eight years old. She said "bursting into song has always been a real dream of mine", and her ...
----------------------------------------------------
Node ID: 576ae445-b12e-4d20-99b7-5e5a91ee7d74
Similarity: 0.8289486590392277
Text: Stone was named the best-dressed woman of 2012 by Vogue and was included on similar listings by Glamour in 2013 and 2015, and People in 2014.
== Personal life == Stone moved from Los Angeles to Greenwich Village, New York, in 2009. In 2016, she moved back to Los Angeles. Despite significant media attention, she refuses to publicly discuss her personal life. Concerned with living a normal life, Stone has said she dislikes receiving paparazzi attention outside her home. She has expressed her ...To retrieve the relevant chunks, we can use an open-source Re-Ranking model from Hugging Face, called the bge-ranker-base model.
Just like the OpenAI API, using Hugging Face requires you to get a user access token. You can create a user access token from Hugging Face by following this documentation.
HF_TOKEN = userdata.get('HF_TOKEN')
os.environ['HF_TOKEN'] = HF_TOKENBefore going further, we also need to install the necessary libraries for using the Re-Ranking model:
%pip install llama-index-postprocessor-flag-embedding-reranker
!pip install git+https://github.com/FlagOpen/FlagEmbedding.gitFinally, we use the bge-ranker-base model to return the most relevant chunks.
# Import packages
from llama_index.postprocessor.flag_embedding_reranker import FlagEmbeddingReranker
from llama_index.core.schema import QueryBundle
# Re-Rank chunks based on the bge-reranker-base-model
reranker = FlagEmbeddingReranker(
top_n = 3,
model = "BAAI/bge-reranker-base",
)
# Return the updated chunks
query_bundle = QueryBundle(query_str=query)
ranked_nodes = reranker._postprocess_nodes(nodes, query_bundle = query_bundle)
for ranked_node in ranked_nodes:
print('----------------------------------------------------')
display_source_node(ranked_node, source_length = 500)This is the result after Re-Ranking:
Node ID: 9b3817fe-3a3f-4417-83d2-2e2996c8b468
Similarity: 3.0143558979034424
Text: Emily Jean "Emma" Stone (born November 6, 1988) is an American actress and producer. She is the recipient of various accolades, including two Academy Awards, two British Academy Film Awards, and two Golden Globe Awards. In 2017, she was the world's highest-paid actress and named by Time magazine as one of the 100 most influential people in the world. Born and raised in Scottsdale, Arizona, Stone began acting as a child in a theater production of The Wind in the Willows in 2000. As a teenager,...
----------------------------------------------------
Node ID: 576ae445-b12e-4d20-99b7-5e5a91ee7d74
Similarity: 2.2117154598236084
Text: Stone was named the best-dressed woman of 2012 by Vogue and was included on similar listings by Glamour in 2013 and 2015, and People in 2014.
== Personal life == Stone moved from Los Angeles to Greenwich Village, New York, in 2009. In 2016, she moved back to Los Angeles. Despite significant media attention, she refuses to publicly discuss her personal life. Concerned with living a normal life, Stone has said she dislikes receiving paparazzi attention outside her home. She has expressed her ...
----------------------------------------------------
Node ID: 1bef0308-8b0f-4f7e-9cd6-92ce5acf811f
Similarity: 1.6185210943222046
Text: Coincidentally, Gosling turned down the Beast role in Beauty and the Beast in favor of La La Land. Chazelle subsequently decided to make his characters somewhat older, with experience in struggling to make their dreams, rather than younger newcomers just arriving in Los Angeles.Emma Stone plays Mia, an aspiring actress in Los Angeles. Stone has loved musicals since she saw Les Misérables when she was eight years old. She said "bursting into song has always been a real dream of mine", and her ...From the output, it’s clear that the node with ID 1bef0308-8b0f-4f7e-9cd6-92ce5acf811f switches from the second position to the third one. Moreover, it’s worth noticing that there is more variability within the similarity scores.
Now that we’ve used Re-Ranking, let’s evaluate what the RAG response to the original query looks like now:
# Initialize the query engine with Re-Ranking
query_engine = index.as_query_engine(
similarity_top_k = 3,
node_postprocessors=[reranker]
)
# Print the response from the model
response = query_engine.query("Compare the families of Emma Stone and Ryan Gosling")
print(response)This is the response provided after applying the Re-Ranking model:
Both Emma Stone and Ryan Gosling have close relationships with their families. Stone has expressed her gratitude for having a great family and people around her who keep her grounded. Gosling, on the other hand, has drawn from his own experiences as an aspiring artist, indicating a connection to his personal background.There is a significant improvement compared to earlier responses, but it’s still incomplete. Let’s evaluate how an LLM-based Re-Ranking approach can help improve RAG performance.
This time, we can rely on an LLM as a Re-Ranker. Here, we use the module RankGPT, which leverages the GPT model’s capabilities to rank documents within the RAG system. To get started, we install the required packages:
%pip install llama-index-postprocessor-rankgpt-rerankWe use the RankGPTRerank function to Re-Rank the chunks by using the gpt-3.5-turbo-0125 model.
# Import packages
from llama_index.postprocessor.rankgpt_rerank import RankGPTRerank
# Re-Rank the top 3 chunks based on the gpt-3.5-turbo-0125 model
reranker = RankGPTRerank(
top_n = 3,
llm = OpenAI(model="gpt-3.5-turbo-0125"),
)
# Display the top 3 chunks based on RankGPT
query_bundle = QueryBundle(query_str=query)
ranked_nodes = reranker._postprocess_nodes(nodes, query_bundle = query_bundle)
for ranked_node in ranked_nodes:
print('----------------------------------------------------')
display_source_node(ranked_node, source_length = 500)By using RankGPT, we get the following chunks:
----------------------------------------------------
Node ID: 1bef0308-8b0f-4f7e-9cd6-92ce5acf811f
Similarity: 1.6185210943222046
Text: Coincidentally, Gosling turned down the Beast role in Beauty and the Beast in favor of La La Land. Chazelle subsequently decided to make his characters somewhat older, with experience in struggling to make their dreams, rather than younger newcomers just arriving in Los Angeles.Emma Stone plays Mia, an aspiring actress in Los Angeles. Stone has loved musicals since she saw Les Misérables when she was eight years old. She said "bursting into song has always been a real dream of mine", and her ...
----------------------------------------------------
Node ID: 9b3817fe-3a3f-4417-83d2-2e2996c8b468
Similarity: 3.0143558979034424
Text: Emily Jean "Emma" Stone (born November 6, 1988) is an American actress and producer. She is the recipient of various accolades, including two Academy Awards, two British Academy Film Awards, and two Golden Globe Awards. In 2017, she was the world's highest-paid actress and named by Time magazine as one of the 100 most influential people in the world. Born and raised in Scottsdale, Arizona, Stone began acting as a child in a theater production of The Wind in the Willows in 2000. As a teenager,...
----------------------------------------------------
Node ID: 576ae445-b12e-4d20-99b7-5e5a91ee7d74
Similarity: 2.2117154598236084
Text: Stone was named the best-dressed woman of 2012 by Vogue and was included on similar listings by Glamour in 2013 and 2015, and People in 2014.
== Personal life == Stone moved from Los Angeles to Greenwich Village, New York, in 2009. In 2016, she moved back to Los Angeles. Despite significant media attention, she refuses to publicly discuss her personal life. Concerned with living a normal life, Stone has said she dislikes receiving paparazzi attention outside her home. She has expressed her ...Since RankGPT doesn’t sort the passages based on the similarity score, the scores presented in the output are not updated. From the output, we can observe that the first node considered the most relevant mentions both Emma Stone and Ryan Gosling, while the remaining nodes contain more details about Emma Stone’s life.
Now, if we print the response of the model with this Re-Ranking Methodology, we get the following output:
Both Emma Stone and Ryan Gosling have close relationships with their families. Stone has expressed gratitude for having a great family and supportive people around her, while Gosling has drawn from his own experiences as an aspiring artist, indicating a connection to his family as well. Stone's family has played a significant role in her life, supporting her career pursuits and celebrating important milestones with her. Similarly, Gosling's experiences as an actor have likely been influenced by his family dynamics and relationships.The answer is longer and contains more details than the previous Re-Ranking technique.
Query transformation, also called query rewriting, is an approach that converts a query into another query rather than using the raw query to retrieve the top k chunks. We are going to explore the following techniques:
HyDE stands for Hypothetical Document Embeddings. It consists of two steps. First, it creates a hypothetical answer to a user query. Once the hypothetical answer/document is determined, the answer and the query are transformed into embeddings. Then, the system retrieves the documents closest to the embeddings in the vector space. Let’s see it in action!
# Import packages
from llama_index.core.indices.query.query_transform import HyDEQueryTransform
from llama_index.core.query_engine.transform_query_engine import (
TransformQueryEngine,
)
# build index and query engine for the index
index = VectorStoreIndex.from_documents(documents, service_context=service_context_gpt3)
query_engine = index.as_query_engine(similarity_top_k=4)
# HyDE setup
hyde = HyDEQueryTransform(include_original=True)
# Transform the query engine using HyDE
hyde_query_engine = TransformQueryEngine(query_engine, hyde)
# Print the response from the model
response = hyde_query_engine.query("Compare the families of Emma Stone and Ryan Gosling")
print(response)This is the output:
Both Emma Stone and Ryan Gosling come from diverse family backgrounds. Ryan Gosling's parents were of part French Canadian descent, along with some German, English, Scottish, and Irish. He grew up in a family that practiced the Church of Jesus Christ of Latter-day Saints. On the other hand, Emma Stone was born and raised in Scottsdale, Arizona, without specific details provided about her family's ethnic background or religious affiliation.Compared to the Re-Ranking methods, we observe a partial improvement. Previously, the outputs related more to the actors’ relationship with their families. Now, they focus more on origins.
The multi-step query transformation approach splits the user's query into sequential subquestions. This method can be handy when working with complex questions.
As we have noticed, LLMs tend to struggle when comparing two facts, even if they can answer correctly when the question concerns only a specific topic. Here, we can see multi-step query transformations in action.
# Multi-step query setup
step_decompose_transform_gpt3 = StepDecomposeQueryTransform(gpt3, verbose=True)
index_summary = "Breaks down the initial query"
# Return query engine for the index
multi_step_query_engine = MultiStepQueryEngine(
query_engine=query_engine,
query_transform=step_decompose_transform_gpt3,
index_summary=index_summary
)
# print the response from the model
response = multi_step_query_engine.query("Compare the families of Emma Stone and Ryan Gosling")We can see the intermediate questions that enable us to reach the final output:
> Current query: Compare the families of Emma Stone and Ryan Gosling
> New query: What is the family background of Emma Stone and Ryan Gosling?
> Current query: Compare the families of Emma Stone and Ryan Gosling
> New query: What is the specific family background of Emma Stone?
> Current query: Compare the families of Emma Stone and Ryan Gosling
> New query: What is Emma Stone's relationship with her family like?This is the following response to the user query:
Both Ryan Gosling and Emma Stone have strong family connections, with Emma Stone emphasizing the importance of her family in keeping her grounded. Ryan Gosling's family background includes a mix of French Canadian, German, English, Scottish, and Irish heritage.In this case, using multi-step query transformation to compare Emma Stone and Ryan Gosling’s families was helpful.
In this article, you have learned various techniques for Improving RAG Performance. Whether it is Chunking, Re-Ranking, or Query Transformations, the best approach often depends on the use case and your desired output for a given query.
If you want to go deeper into RAG, we recommend watching our code-alongs on Retrieval Augmented Generation with LlamaIndex and Retrieval Augmented Generation with GPT and Milvus. These videos show how to combine LLM with vector databases using the retrieval augmented generation in different use cases.
Continue Your AI Journey Today!
course
course
course
blog
Natassha Selvaraj
8 min
blog
Ryan Ong
11 min
tutorial
Iván Palomares Carrascosa
11 min
tutorial
Dr Ana Rojo-Echeburúa
19 min
code-along
Dan Becker
code-along
Yujian Tang







